Physics:Trigger efficiency
Triggers are used to bring the rate of useful events into a range manageable by the data acquisition equipment. Trigger counters also provide timing signals to the various detector parts. The trigger efficiency is mainly determined by two components:
- a) The efficiency of the trigger algorithm: In the presence of a large number of topologies, fast methods to define useful event candidates will usually not lead to the required unique solution. On the other hand, useful events should not be lost, or at least not in a biased way. For a maximum available processing time a compromise must be chosen between selectivity (higher reduction of data rate) and risk of bias. A general recipe is impossible to give; useful tools for studying efficiencies of triggers are Monte Carlo methods, in combination with the toolkit of hypothesis testing (e.g. the Neyman-Pearson diagram).
b) Dead time losses: Without a higher level trigger, the frequency of recording is given by

where f1 is the frequency of recording, f0 the raw trigger frequency, and
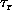 the recording time, usually equivalent to dead time .
the recording time, usually equivalent to dead time .
Introducing a second level trigger, i.e. a triggering algorithm that starts operating only if and when the lower-level trigger has fired, the rate of recording for good events can be improved. The relative gain is given by
![]()
where f2 is the rate of good events recorded with the second level trigger, ![]() is the fraction of events retained in the second level trigger, and
is the fraction of events retained in the second level trigger, and ![]() is the decision time on the second level which may include partial data readout. In order to have any gain introduced by the second level trigger (i.e. less dead time), it is necessary that
is the decision time on the second level which may include partial data readout. In order to have any gain introduced by the second level trigger (i.e. less dead time), it is necessary that
![]()
or
![]()
Usually, this simple algorithm is not quite applicable: the decision times for accepted and rejected events may typically have very different distributions, and some degree of parallelism is often introduced such that during the higher-level decision making, the readout starts, getting aborted if a reject decision is arrived at. Also, trigger algorithms are never fully efficient in the sense of a) above, and again compromises have to be found from case to case.
 |

