Oblivious RAM
This article has multiple issues. Please help improve it or discuss these issues on the talk page. (Learn how and when to remove these template messages)
(Learn how and when to remove this template message)
|
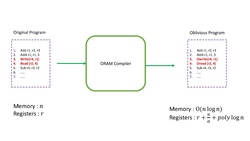
An Oblivious RAM (ORAM) simulator is a compiler that transforms an algorithm in such a way that the resulting algorithm preserves the input-output behavior of the original algorithm but the distribution of the memory access patterns of the transformed algorithm is independent of the memory access pattern of the original algorithm.
The use of ORAMs is motivated by the fact that an adversary can obtain nontrivial information about the execution of a program and the data that the program is using just by observing the pattern in which the program accesses various memory locations during its execution. An adversary can get this information even if the data in memory is encrypted.
This definition is suited for settings like protected programs running on unprotected shared memory or clients running programs on their systems by accessing previously stored data on a remote server. The concept was formulated by Oded Goldreich and Rafail Ostrovsky in 1996.[1]
Definition
A Turing machine (TM), a mathematical abstraction of a real computer (program), is said to be oblivious if, for any two inputs of the same length, the motions of the tape heads remain the same. Pippenger and Fischer[2] proved that every TM with running time can be made oblivious and that the running time of the oblivious TM is . A more realistic model of computation is the RAM model. In the RAM model of computation, there is a CPU that can execute the basic mathematical, logical, and control instructions. The CPU is also associated with a few registers and a physical random access memory, where it stores the operands of its instructions. The CPU also has instructions to read the contents of a memory cell and write a specific value to a memory cell. The definition of ORAMs captures a similar notion of obliviousness for memory accesses in the RAM model.
Informally, an ORAM is an algorithm at the interface of a protected CPU and the physical RAM such that it acts like a RAM to the CPU by querying the physical RAM for the CPU while hiding information about the actual memory access pattern of the CPU from the physical RAM. In other words, the distribution of memory accesses of two programs that make the same number of memory accesses to the RAM is indistinguishable from each other. This description will still make sense if the CPU is replaced by a client with a small storage and the physical RAM is replaced with a remote server with a large storage capacity, where the data of the client resides.
The following is a formal definition of ORAMs. Let denote a program requiring memory of size when executing on an input . Suppose that has instructions for basic mathematical and control operations in addition to two special instructions and , where reads the value at location and writes the value to . The sequence of memory cells accessed by a program during its execution is called its memory access pattern and is denoted by .
A polynomial-time algorithm is an Oblivious RAM (ORAM) compiler with computational overhead and memory overhead , if given and a deterministic RAM program with memory-size outputs a program with memory-size such that for any input , the running-time of is bounded by where is the running-time of , and there exists a negligible function such that the following properties hold:
- Correctness: For any and any string , with probability at least , .
- Obliviousness: For any two programs , any and any two inputs, if , then is -close to in statistical distance, where and .
Note that the above definition uses the notion of statistical security. One can also have a similar definition for the notion of computational security.[3]
History of ORAMs
ORAMs were introduced by Goldreich and Ostrovsky,[4][5][1] where the key motivation was stated as providing software protection from an adversary who can observe a program's memory access pattern (but not the contents of the memory).
The main result in this work[1] is that there exists an ORAM compiler that uses server space and incurs a running time overhead of when making a program that uses memory cells oblivious. There are several attributes that need to be considered when comparing various ORAM constructions. The most important parameters of an ORAM construction's performance are the client-side space overhead, server-side space overhead, and the time overhead required to make one memory access. Based on these attributes, the construction of Asharov et al.,[6] called "OptORAMa", is the first optimal ORAM construction. It achieves client storage, server storage, and access overhead, matching the known lower bounds.
Another important attribute of an ORAM construction is whether the access overhead is amortized or worst-case. Several earlier ORAM constructions have good amortized access overhead guarantees but have worst-case access overheads. Some ORAM constructions with polylogarithmic worst-case computational overheads are.[7][8][9][10][11][12] The constructions of[4][5][1] were in the random oracle model, where the client assumes access to an oracle that behaves like a random function and returns consistent answers for repeated queries. Access to the oracle could be replaced by a pseudorandom function whose seed is a secret key stored by the client, if one assumes the existence of one-way functions. The papers[13][14] were aimed at removing this assumption completely. The authors of[14] also achieve an access overhead of
While most of the earlier works focus on proving security computationally, there are more recent works[3][10][13][14] that use the stronger statistical notion of security.
One of the only known lower bounds on the access overhead of ORAMs is due to Goldreich et al.[1] They show a lower bound for ORAM access overhead, where is the data size. Another lower bound is by Larsen and Nielsen.[15] There is also a conditional lower bound on the access overhead of ORAMs due to Boyle et al.[16] that relates this quantity with that of the size of sorting networks.
ORAM constructions
Trivial construction
A trivial ORAM simulator construction, for each read or write operation, reads from and writes to every single element in the array, only performing a meaningful action for the address specified in that single operation. The trivial solution thus, scans through the entire memory for each operation. This scheme incurs a time overhead of for each memory operation, where n is the size of the memory.
A simple ORAM scheme
A simple version of a statistically secure ORAM compiler constructed by Chung and Pass[3] is described in the following along with an overview of a proof of its correctness. The compiler on input n and a program Π with its memory requirement n, outputs an equivalent oblivious program Π′.
If the input program Π uses r registers, the output program Π′ will need registers, where is a parameter of the construction. Π′ uses memory and its (worst-case) access overhead is .
The ORAM compiler is very simple to describe. Suppose that the original program Π has instructions for basic mathematical and control operations in addition to two special instructions and , where reads the value at location l and writes the value v to l. The ORAM compiler, when constructing Π′, simply replaces each read and write instructions with subroutines Oread and Owrite and keeps the rest of the program the same. It may be noted that this construction can be made to work even for memory requests coming in an online fashion.
Memory organization of the oblivious program
The program Π′ stores a complete binary tree T of depth in its memory. Each node in T is represented by a binary string of length at most d. The root is the empty string, denoted by λ. The left and right children of a node represented by the string are and respectively. The program Π′ thinks of the memory of Π as being partitioned into blocks, where each block is a contiguous sequence of memory cells of size α. Thus, there are at most blocks in total. In other words, the memory cell r corresponds to block .
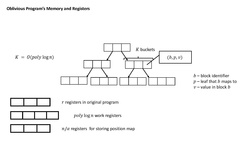
At any point in time, there is an association between the blocks and the leaves in T. To keep track of this association, Π′ also stores a data structure called a position map, denoted by , using registers. This data structure, for each block b, stores the leaf of T associated with b in .
Each node in T contains an array with at most K triples. Each triple is of the form , where b is a block identifier and v is the contents of the block. Here, K is a security parameter and is .
Description of the oblivious program
The program Π′ starts by initializing its memory as well as registers to ⊥. Describing the procedures, Owrite and Oread is enough to complete the description of Π′. The sub-routine Owrite is given below. The inputs to the sub-routine are a memory location and the value v to be stored at the location l. It has three main phases, namely FETCH, PUT_BACK, and FLUSH.
input: a location l, a value v
Procedure FETCH // Search for the required block.
// b is the block containing l.
// i is l's component in block b.
if then . // Set pos to a uniformly random leaf in T.
flag .
for each node N on the path from the root to pos do
if N has a triple of the form then
Remove from N, store x in a register, and write back the updated N to T.
flag .
else
Write back N to T.
Procedure PUT_BACK // Add back the updated block at the root. . // Set pos' to a uniformly random leaf in T. if flag then Set x' to be the same as x except for v at the i-th position. else Set x' to be a block with v at i-th position and ⊥'s everywhere else. if there is space left in the root then Add the triple to the root of T. else Abort outputting overflow.
Procedure FLUSH // Push the blocks present in a random path as far down as possible. . // Set to a uniformly random leaf in T. for each triple in the nodes traversed the path from the root to Push down this triple to the node N that corresponds to the longest common prefix of and . if at any point some bucket is about to overflow then Abort outputting overflow.
The task of the FETCH phase is to look for the location l in the tree T. Suppose pos is the leaf associated with the block containing location l. For each node N in T on the path from root to pos, this procedure goes over all triples in N and looks for the triple corresponding to the block containing l. If it finds that triple in N, it removes the triple from N and writes back the updated state of N. Otherwise, it simply writes back the whole node N.
In the next phase, it updates the block containing l with the new value v, associates that block with a freshly sampled uniformly random leaf of the tree, and writes back the updated triple to the root of T.
The last phase, which is called FLUSH, is an additional operation to release the memory cells in the root and other higher internal nodes. Specifically, the algorithm chooses a uniformly random leaf and then tries to push down every node as much as possible along the path from root to . It aborts outputting an overflow if at any point some bucket is about to overflow its capacity.
The sub-routine Oread is similar to Owrite. For the Oread sub-routine, the input is just a memory location and it is almost the same as Owrite. In the FETCH stage, if it does not find a triple corresponding to location l, it returns ⊥ as the value at location l. In the PUT_BACK phase, it will write back the same block that it read to the root, after associating it with a freshly sampled uniformly random leaf.
Correctness of the simple ORAM scheme
Let C stand for the ORAM compiler that was described above. Given a program Π, let Π′ denote . Let denote the execution of the program Π on an input x using n memory cells. Also, let denote the memory access pattern of . Let μ denote a function such that for any , for any program Π and for any input , the probability that outputs an overflow is at most . The following lemma is easy to see from the description of C.
- Equivalence Lemma
- Let and . Given a program Π, with probability at least , the output of is identical to the output of .
It is easy to see that each Owrite and Oread operation traverses root-to-leaf paths in T chosen uniformly and independently at random. This fact implies that the distribution of memory access patterns of any two programs that make the same number of memory accesses are indistinguishable if they both do not overflow.
- Obliviousness Lemma
- Given two programs and and two inputs such that , with probability at least , the access patterns and are identical.
The following lemma completes the proof of correctness of the ORAM scheme.
- Overflow Lemma
- There exists a negligible function μ such that for every program Π, every n and input x, the program outputs overflow with probability at most .
Computational and memory overheads
During each Oread and Owrite operation, two random root-to-leaf paths of T are fully explored by Π′. This takes time. This is the same as the computational overhead and is since K is .
The total memory used up by Π′ is equal to the size of T. Each triple stored in the tree has words in it and thus there are words per node of the tree. Since the total number of nodes in the tree is , the total memory size is words, which is . Hence, the memory overhead of the construction is .
References
- ↑ 1.0 1.1 1.2 1.3 1.4 Goldreich, Oded; Ostrovsky, Rafail (1996), "Software protection and simulation on oblivious RAMs", Journal of the ACM 43 (3): 431–473, doi:10.1145/233551.233553
- ↑ Pippenger, Nicholas; Fischer, Michael J. (1979), "Relations among complexity measures", Journal of the ACM 26 (2): 361–381, doi:10.1145/322123.322138
- ↑ 3.0 3.1 3.2 Chung, Kai-Min; Pass, Rafael (2013), "A simple ORAM", IACR Cryptology ePrint Archive, https://eprint.iacr.org/2013/243
- ↑ 4.0 4.1 Goldreich, Oded (1987), "Towards a theory of software protection and simulation by oblivious RAMs", in Aho, Alfred V., Proceedings of the 19th Annual ACM Symposium on Theory of Computing (STOC '87), Association for Computing Machinery, pp. 182–194, doi:10.1145/28395.28416, ISBN 0-89791-221-7
- ↑ 5.0 5.1 Ostrovsky, Rafail (1990), "Efficient computation on oblivious RAMs", Proceedings of the 22nd Annual ACM Symposium on Theory of Computing (STOC '90), Association for Computing Machinery, pp. 514–523, doi:10.1145/100216.100289, ISBN 0-89791-361-2
- ↑ Asharov, Gilad; Komargodski, Ilan; Lin, Wei-Kai; Nayak, Kartik; Peserico, Enoch; Shi, Elaine (2023), "OptORAMa: Optimal Oblivious RAM", Journal of the ACM, 70, Association for Computing Machinery, pp. 4:1–4:70, doi:10.1145/3566049
- ↑ Asharov, Gilad; Komargodski, Ilan; Lin, Wei-Kai; Shi, Elaine (2023), "Oblivious {RAM} with Worst-Case Logarithmic Overhead", Journal of Cryptology, Springer, pp. 7, doi:10.1007/s00145-023-09447-5
- ↑ Kushilevitz, Eyal; Lu, Steve; Ostrovsky, Rafail (2012), "On the (in)security of hash-based oblivious RAM and a new balancing scheme", Proceedings of the Twenty-Third Annual ACM-SIAM Symposium on Discrete Algorithms, Association for Computing Machinery, pp. 143–156, doi:10.1137/1.9781611973099.13, ISBN 978-1-61197-210-8
- ↑ Ostrovsky, Rafail; Shoup, Victor (1997), "Private information storage (extended abstract)", in Leighton, F. Thomson; Shor, Peter W., Proceedings of the Twenty-Ninth Annual ACM Symposium on the Theory of Computing (STOC '97), Association for Computing Machinery, pp. 294–303, doi:10.1145/258533.258606, ISBN 0-89791-888-6
- ↑ 10.0 10.1 Shi, Elaine; Chan, T.-H. Hubert; Stefanov, Emil; Li, Mingfei (2011), "Oblivious RAM with worst-case cost", in Lee, Dong Hoon; Wang, Xiaoyun, Advances in Cryptology – ASIACRYPT 2011 – 17th International Conference on the Theory and Application of Cryptology and Information Security, Seoul, South Korea, December 4–8, 2011, Proceedings, Lecture Notes in Computer Science, 7073, Springer, pp. 197–214, doi:10.1007/978-3-642-25385-0_11, ISBN 978-3-642-25384-3
- ↑ Goodrich, Michael T.; Mitzenmacher, Michael; Ohrimenko, Olga; Tamassia, Roberto (2011), "Oblivious RAM simulation with efficient worst-case access overhead", in Cachin, Christian; Ristenpart, Thomas, Proceedings of the 3rd ACM Cloud Computing Security Workshop, CCSW 2011, Chicago, IL, USA, October 21, 2011, Association for Computing Machinery, pp. 95–100, doi:10.1145/2046660.2046680, ISBN 978-1-4503-1004-8
- ↑ Chung, Kai-Min; Liu, Zhenming; Pass, Rafael (2014), "Statistically-secure ORAM with overhead", in Sarkar, Palash; Iwata, Tetsu, Advances in Cryptology - ASIACRYPT 2014 - 20th International Conference on the Theory and Application of Cryptology and Information Security, Kaoshiung, Taiwan, R.O.C., December 7-11, 2014, Proceedings, Part II, Lecture Notes in Computer Science, 8874, Springer, pp. 62–81, doi:10.1007/978-3-662-45608-8_4, ISBN 978-3-662-45607-1
- ↑ 13.0 13.1 Ajtai, Miklós (2010), "Oblivious RAMs without cryptographic assumptions [extended abstract]", Proceedings of the 42nd ACM Symposium on Theory of Computing (STOC 2010), Association for Computing Machinery, pp. 181–190, doi:10.1145/1806689.1806716
- ↑ 14.0 14.1 14.2 Damgård, Ivan; Meldgaard, Sigurd; Nielsen, Jesper Buus (2011), "Perfectly secure oblivious RAM without random oracles", in Ishai, Yuval, Theory of Cryptography - 8th Theory of Cryptography Conference, TCC 2011, Providence, RI, USA, March 28-30, 2011, Proceedings, Lecture Notes in Computer Science, 6597, Springer, pp. 144–163, doi:10.1007/978-3-642-19571-6_10, ISBN 978-3-642-19570-9
- ↑ Larsen, Kasper Green; Nielsen, Jesper Buus (2018), "Yes, There is an Oblivious {RAM} Lower Bound!", Advances in Cryptology - CRYPTO, Springer, pp. 523–542, doi:10.1007/978-3-319-96881-0_18
- ↑ Boyle, Elette; Naor, Moni (2016), "Is there an oblivious RAM lower bound?", Proceedings of the 2016 ACM Conference on Innovations in Theoretical Computer Science (ITCS '16), Association for Computing Machinery, pp. 357–368, doi:10.1145/2840728.2840761, ISBN 978-1-4503-4057-1
See also
 |  |
