Virtual synchrony
Virtual synchrony is an interprocess message passing (sometimes called ordered, reliable multicast) technology. Virtual synchrony systems allow programs running in a network to organize themselves into process groups, and to send messages to groups (as opposed to sending them to specific processes). Each message is delivered to all the group members, in the identical order, and this is true even when two messages are transmitted simultaneously by different senders. Application design and implementation is greatly simplified by this property: every group member sees the same events (group membership changes and incoming messages) in the same order.
A virtually synchronous service is typically implemented using a style of programming called state machine replication, in which a service is first implemented using a single program that receives inputs from clients through some form of remote message passing infrastructure, then enters a new state and responds in a deterministic manner. The initial implementation is then transformed so that multiple instances of the program can be launched on different machines, using a virtually synchronous message passing system to replicate the incoming messages over the members. The replicas will see the same events in the same order, and are in the same states, hence they will make the same state transitions and remain in a consistent state.
The replication of the service provides a form of fault-tolerance: if a replica fails (by crashing), the others remain and can continue to provide responses. Different members of the replica group can also be programmed to subdivide the workload, typically by using the group membership to determine their respective roles. This permits a group of N members to run as much as N times faster than a single member, or to handle N times as many requests, while continuing to offer fault-tolerance in the event of a crash.
Virtual synchrony is distinguished from classical state machine replication because the model includes features whereby a programmer can request early (optimistic) delivery of messages, or relaxed forms of ordering. When used appropriately, these features can enable substantial speedup. However, the programmer needs to be sure that the relaxation of guarantees will not compromise correctness.
For example, in a service that uses locking to protect concurrently updated data, the messaging system can be instructed to use an inexpensive form of message ordering, in which the messaging system respects the ordering in which individual senders send messages (FIFO guarantee) but does not attempt to impose an agreed order if messages are sent concurrently by different senders. Provided that the sender indeed held locks on the data, it can be shown that FIFO ordering suffices for correctness. The benefit is that FIFO ordering is much less costly to implement than total ordering for concurrent messages.
To give another example, by delivering messages optimistically, virtual synchrony systems can outperform the Paxos that is normally required for implementation of state machine replication: Paxos normally requires a 2-phase protocol, whereas optimistic virtual synchrony protocols can deliver messages immediately upon their arrival. However, this could result in a violation of the safety property of the state machine replication model. To prevent such problems, the programmer who uses this feature is required to invoke a primitive called flush, which delays the caller until any optimistically delivered messages have reached all of the group members. Provided that the programmer understands this behavior and is careful to call flush before interacting with external clients or persistent storage, higher performance can be achieved without loss of safety.
The flexibility associated with these limited forms of event reordering and optimistic early delivery permit virtual synchrony platforms to achieve extremely high data rates while still preserving very strong fault-tolerance and consistency guarantees.
Detailed Discussion
Distributed computer systems often need a way to replicate data for sharing between programs running on multiple machines, connected by a network. Virtual synchrony is one of three major technologies for solving this problem.[citation needed] The key idea is to create a form of distributed state machine associated with the replicated data item. Called a process group, these state machines share copies of the data, and updates are delivered as events that occur in the same order at all the copies.[citation needed] If a process fails or crashes, this is reported to the other processes in the group; if a process joins, this is similarly reported, and a state transfer is used to initialize the joining member. An application with lots of data items to replicate might do so by using a single group for the whole set, or it could create different groups for different items, with the former approach used when the items are replicated at the identical places, and the latter being used when the replication patterns differ.[citation needed]
Each process group has a name, visible within the network. A single application program can become a member of many groups at the same time.[citation needed] In effect, a process group becomes an abstraction for sharing data, coordinating actions, and monitoring other processes. In the most widely used software libraries implementing the model, virtual synchrony is typically employed within individual objects, which are then incorporated into object oriented code in languages like Java or C#.[citation needed] The objects themselves act as a unit of replication with virtual synchrony properties.
The term virtual synchrony refers to the fact that applications see the shared data evolve in what seems to be a synchronous manner. This form of synchronization is virtual because the actual situation is more complex than seems to be the case from a programmer's perspective.[citation needed] Like a compiler that sometimes reorders the execution of instructions for higher performance, or an operating system that sometimes stores random access memory on disk, virtual synchrony sometimes reorders events in ways that improve performance, and yet won't be noticeable to applications.[citation needed]
Using the virtual synchrony model, it is relatively easy to maintain fault-tolerant replicated data in a consistent state.[citation needed] One can then build higher level abstractions over the basic replication mechanisms. For example, many virtual synchrony libraries also support tools for building distributed key-value stores, replicating external files or databases, locking or otherwise coordinating the actions of group members, etc.[citation needed]
Virtual synchrony replication is used mostly when applications are replicating information that evolves extremely rapidly.[citation needed] As discussed further below,[clarification needed] the kinds of applications that would need this model include multiuser role-playing games, air traffic control systems, stock exchanges, and telecommunication switches.[citation needed] Of course, there are other ways to solve the same problems. For example, most of today's online multiuser role-playing games give users a sense that they are sharing replicated data, but in fact the data lives in a server on a data center, and any information passes through the data centers. Those games probably wouldn't use models like virtual synchrony, at present.[citation needed] However, as they push towards higher and higher data rates, taking the server out of the critical performance path becomes important, and with this step, models such as virtual synchrony are potentially valuable.
The trend towards cloud computing has increased interest in consistent state replication. Cloud computing systems are large virtualized data centers, operated by internet search or commerce firms such as IBM, Microsoft, Google and Amazon. Inside a cloud computing platform one finds services such as lock management systems (Google's is called Chubby, and Yahoo! uses one called Zookeeper), and these are implemented using virtual synchrony or closely related models.[citation needed] Other services that might be implemented using virtual synchrony include the cluster management tools that relaunch failed applications when nodes in a cluster crash, event notification tools that inform applications when significant events occur, and logging tools that help an application save its state for replay during recovery.[citation needed]
Three Distributed Data Replication Models
Virtual Synchrony is a popular computing model, closely related to the transactional one-copy serializability model (used mostly in replicated database systems) and the state machine (consensus) model, sometimes known as "Paxos", the name given to the most widely cited state-machine implementation.
- Among these, transactional replication is probably the most widely known model—most database textbooks discuss it. Yet overheads are very high when using true one-copy serializability, hence the approach to replication has never been a commercial success.[citation needed] Turing Award winner Jim Gray offers some thoughts on this issue in a paper he wrote about "The Dangers of Replication and a Solution". Today, few database products support true replication of the sort Gray warns about. Instead, they fragment large databases into what are called shards, and they often relax consistency, offering a so-called NoSQL model instead of the full ACID replication model. The resulting relaxation of consistency is adequate for some purposes, but mission-critical computing systems often need stronger guarantees.
- Virtual synchrony offers options for maintaining consistency at the higher performance levels required in demanding settings. The model has also been standardized as part of the CORBA reference model, and is supported by JGroups , a part of the widely used JBoss technology. However, the very features that enable these high levels of performance also make virtual synchrony relatively difficult to use correctly—programmers need some training, and without proper care, correctness of a replicated service can be impacted.
- The state machine / Paxos is used in a number of commercial products that power large scalable systems, such as Chubby, a locking service used by Google applications. However, Paxos can be slow and scales poorly, and like virtual synchrony, can be quite hard to use correctly.
Data Replication and Fault Tolerance
The basic goal for all of these protocols is to replicate data in a distributed system in a manner that makes the replicated entity indistinguishable from a non-replicated object implementing the same interface. For example, if we imagine a simple variable, x, that can be read or written to, a replicated version might consist of some set of replicas x0, x1, ... xn and an associated protocol, such that reads and writes to the replicates are performed in a way that looks indistinguishable from reads and writes to the original variable. The challenge is to deal with cases in which multiple updates are initiated concurrently (sometimes called an edit conflict), or where a failure disrupts an update while it is still in progress. When we create a process group, the idea is that each of its members will hold a replica. Updates are delivered to the group members through an event notification interface implemented in a way that eliminates these kinds of problems.
The central difference between the three models is that virtual synchrony assumes that the variable is replicated in memory by a set of processes executing on some collection of machines in a network. Transactional one-copy serializability assumes that the data resides in a collection of transactional databases (on disk), and implements the full transactional ACID properties, with the usual begin/commit/abort interface. State-machine consensus lies somewhere in the middle: the variables are assumed to be persistent (for example they might be stored in files), but are not assumed to have full ACID properties, and access is not assumed to go through a transactional begin/commit/abort interface.
None of the three models is particularly difficult to support in a system where the set of participating processes is stable, and where messages are delivered reliably. However, in real networks, computers can crash or become disconnected and messages can be lost. The need to preserve the properties of the model while masking failures and maintaining high performance is what makes the data replication problem so difficult.
All three models assume that machines may fail by crashing: a computer halts, or some process on it halts, and other processes sense the failure by timeout. Timeout, of course, is a potentially inaccurate way to sense failures (timeouts always discover true crashes, but sometimes a timeout will trigger for some other reason, such as a transient connectivity problem.) A platform implementing any of these models must provide the programmer with a set of system calls that allows him or her to write code that will continue to respect the model even if these kinds of problems occur. In effect, the platform hides this difficult fault-tolerance problem from the programmer.
None of the three models can handle more complex failures, such as machines that are taken over by a virus, or a network that sometimes modifies the messages transmitted. The so-called Byzantine agreement model goes beyond the data replication schemes discussed here by also solving such issues, but does so at a price: Byzantine replication protocols typically require larger numbers of servers, and can be much slower.
Other uses for virtual synchrony
Virtual synchrony is useful for more than just replicating data, although replication is probably the most common use. Other mechanisms that can be constructed "over" a virtual synchrony platform include:
- Event notification (also called publish-subscribe). These are interfaces that let applications publish event messages, tagging them with topic names. Applications can subscribe to a topic, or a pattern that matches many topics, specifying a function to be invoked when a matching message is received. The platform matches publishers to subscribers. With group communication, this is done by creating a group to correspond to each topic, or to a set of topics. Each new event is published by multicasting it within the group.
- Locking. Many systems need some form of locking or synchronization mechanism. Locking can easily be implemented on top of a virtual synchrony subsystem. For example, a system can associate a token with each group, and make the rule that to hold the lock, a process must gain "ownership" of the token. A multicast is used to request the lock: every member of the group will thus learn of every request. To release a lock, the holder selects the oldest pending request, and multicasts a message releasing the lock to the process that issued that oldest request. Every process in the group will thus learn that the lock has been passed, and to whom. Similarly, if a lock holder crashes, every process will learn that this happened, and a leader (usually, the oldest non-crashed group member) can take remedial action, then release the lock.
- Why is virtual synchrony of value in such a solution? Recall that a communication layer implementing virtual synchrony must take steps to ensure that every group member sees every message, and has a definition of what these terms mean (in terms of the temporal model seen earlier). This makes it relatively easy to prove that the locking protocol is correct.
- Contrast this with the same protocol, but in a system lacking virtual synchrony (for example, using UDP multicast, which provides no guarantees at all). Even if the same sequence of events occurs and the same messages are sent, the protocol becomes very hard to reason about, because processes may join or leave the group, or fail, while the protocol is running. If some processes miss a locking request, or a lock-release message, bugs can easily arise. Thus virtual synchrony made it easy to solve this problem; without virtual synchrony, the problem is extremely hard to solve.
- Fault-tolerance. A group can easily support primary-backup forms of fault-tolerance, in which one process performs actions and a second one stands by as a backup. Even fancier is the "coordinator/cohort" model, in which each request is assigned to a different coordinator process. Other processes in the group are ranked to serve as a primary backup, secondary, etc. Since failures are rare, the effect is that a group with N members can potentially handle N times the compute load. Yet if a failure does occur, the group can transparently handle it.
- Cooperative caching. Members of a group can share lists of data they have in their caches. This way, if one process needs an object that some other process has a copy of, the group members can help one another out and avoid fetching the object from a server that might be distant, overloaded or expensive.
- Other peer-to-peer mechanisms. A group can implement the functions of a distributed hash table (DHT), since every member knows the identity of every other member. Groups can also be a useful infrastructure for implementing swarm algorithms, like the ones used in BitTorrent.
Performance
Among the three models, virtual synchrony achieves the highest levels of performance, but this comes at a cost: to gain higher performance the programmer must relax ordering and employ optimistic early delivery features that expose the service to some risk of inconsistency. Virtual synchrony implementations employ a primitive called flush to force the service back into a consistent state before interactions with external clients or storage systems. The effect is to offer a very strong model, but only if the various features are employed correctly.
The Paxos and transactional models guarantee a higher degree of durability in the presence of crashes, and are sometimes perceived as easier to use, but at the price of sharply reduced performance and scalability. Both models need to first ensure that an update is recorded in a write-ahead log before any process can actually perform the update. This introduces a form of two-phase commit into the protocol, and hence slows things down: first the update is sent and logged, and all members confirm that they have it, and only then is it performed. In contrast, virtual synchrony implementations with in-memory data replication can generally update a replicated variable as soon as a message describing the update reaches the relevant group members. They can stream high rates of updates by packing multiple updates into a single message.
To give some sense of the relative speed, experiments with 4-node replicated variables undertaken on the Isis and Horus systems in the 1980s suggested that virtual synchrony implementations in typical networks were about 100 times faster than state-machine replication using Paxos, and about 1000 to 10,000 times faster than full-fledged transactional one-copy-serializability. Of course, these sorts of order of magnitude numbers are highly sensitive to the implementation and choice of platform, but they also reflect underlying obligations within the protocols used to implement the models. Modern systems like the Spread Toolkit, Quicksilver, and Corosync can achieve data rates of 10,000 multicasts per second or more, and can scale to large networks with huge numbers of groups or processes.
Most distributed computing platforms support one or more of these models. For example, the widely supported object-oriented CORBA platforms all support transactions and some CORBA products support transactional replication in the one-copy-serializability model. The "CORBA Fault Tolerant Objects standard" is based on the virtual synchrony model. Virtual synchrony was also used in developing the New York Stock Exchange fault-tolerance architecture, the French Air Traffic Control System, the US Navy AEGIS system, IBM's Business Process replication architecture for WebSphere and Microsoft's Windows Clustering architecture for Windows Longhorn enterprise servers.[1]
Essential features of the virtual synchrony model
Virtual synchrony is usually presented to programmers through a simple distributed programming library that supports at least three basic interfaces. First, a process (an executing program) can join a process group. Each group has a name (a bit like a file name, although these names are interpreted within a network, not relative to a disk), and each has a list of members. The join primitive returns some form of handle on the group. The process can then register a handler for incoming events, and can send multicasts to the group.
The basic guarantee associated with the model is that all processes belonging to a group see the same events, in the same order. The platform senses failures (using timeouts) but reports them in a consistent manner to all group members. Multicast messages may be initiated concurrently by multiple senders, but will be delivered in some fixed order selected by the protocols implementing the model.
Notice that the guarantee just described embodies what may seem to be a contradiction. We know that timeout cannot be used to detect failures accurately. Yet virtual synchrony lets the user treat failure notifications (view changes) as trustworthy, infallible events. The key insight is that virtual synchrony is implemented by a software system that creates an abstraction within which the user's code is executed. Thus, failure detection by the platform (using timeouts) triggers an internal agreement protocol (within the platform). Only when this protocol terminates is a fault event delivered to the application. The application is spared from needing to implement the agreement mechanism, and sees a simple and seemingly accurate fault notification event.
Events are of several types. First, each received multicast is delivered as an event. But membership changes in the group are also reported through events; these are called new views of the group. Moreover, when a process joins a group, some existing member is asked to create a checkpoint: a message describing the state of the group at the time the process joined. This is reported to the new member as a state transfer event, and is used to initialize the joining process.
For example, suppose that an air traffic control system maintains some group associated with the airplanes flying in sector XYZ over Paris. Each air traffic controller who monitors that sector would have a process running on his or her machine, and these processes would join the XYZ group as they start up. The members would replicate the list of air traffic control plans and tracks associated with sector XYZ. Upon joining, a process would obtain a copy of the state of the sector as of the moment it joined, delivered as a checkpoint through a state transfer event. Loading such a checkpoint is analogous to reading a file that lists the current state of the sector. Later, as events occur that impact the status of the sector, they would be multicast so that all members of the group can see those events. Since each member is in the same state, and receives the same updates, each air traffic controller sees the same sector status and they see it evolve in the same manner. If a failure occurs, the surviving systems can take over roles that were previously held by the crashed one.
A Time-Space Illustration of the Virtual Synchrony Concept
-
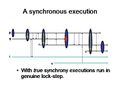 Figure 1 (True synchrony)
Figure 1 (True synchrony) -
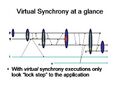 Figure 2 (Relaxed timing)
Figure 2 (Relaxed timing) -
 Figure 3 (Virtual synchrony)
Figure 3 (Virtual synchrony)



The three executions shown above illustrate the type of event reordering used in virtual synchrony systems. Each shows a set of processes (named p, q, etc.) executing as time elapses, from left to right. They interact by exchanging messages, which are shown as arrows from process to process. Notice that the three figures are quite similar but differ in seemingly small ways: in the first figure, the message-passing arrows are vertical, as if the sending of a message was an instantaneous event. In the second figure, the sending of a message takes "time", and we see this because the arrows are now slanted forward. In the third figure, some of the message sending arrows cross one another.
We will start by looking closely at figure 1 (you may wish to enlarge it so that you can see the arrows clearly). Consider the sequence of events that occur as time elapses, from left to right.
At the start, p creates a process group and is its only member. Then q joins and with p's help, initializes itself. The heavy arrow denotes the creation of a checkpoint by p, which is copied to q, and then loaded by q. Perhaps this group lists air traffic control state for some sector over Paris. Now t, a non-member, asks the group some question. It sends a message, and the group members cooperate to respond (perhaps they each search half of an ATC database—after all, each knows that the group has two members and each knows its own rank, so parallel computing becomes easy! Next we see some update messages—multicasts—exchanged by p and q. Process r joins the group, but q either crashes or fails. Notice that each event is seen in the identical order by all the members. This makes it easy to track the evolving group state. Some would call this a state machine execution.
What makes a virtually synchronous system virtual rather than real is that the synchronous event ordering is actually an illusion. If the timing in the system isn't perfectly synchronized, messages may be delivered with some delays (Figure 2). Now, the delays in question may not be significant to human perception. But how can the application know what order to process the events in? We can't use true clock time for this: even with GPS clocks, synchronization won't be better than a few milliseconds.
In a worst-case scenario, events genuinely happen out of order (Figure 3). The point this figure is intended to make is that sometimes, a system can deliver events out of order—and yet the application might not notice. We'll discuss cases in which this occurs momentarily. By deviating from the synchronous order, virtual synchrony systems gain speed and improve fault-tolerance (they are less likely to experience correlated crashes where some message causes all the members to crash simultaneously).
In virtual synchrony systems, the application programmer signals to the platform what form of ordering is really needed. For example, the programmer might indicate that multicast m updates different data than multicast n. Virtual synchrony software systems make it easy to do this sort of thing, although we won't delve into the details here. Basically, the programmer says "you can deliver messages m and n in any order you like, because my application won't notice". When permitted to do so, the communication system can now save time by not delaying messages under conditions where providing identical delivery order for n and m would have introduced extra cost and thereby slowed down the data rate.
When could we get away with this sort of thing? The answer usually depends on the application. But one good example arises if a group is maintaining data about some collection of objects that tend to be accessed independently. For example, perhaps the group represents the rooms in a multi-user role-playing game. Users are only in one room at a time, hence multicasts that update data in different rooms can be delivered in different orders. If a user sees one such multicast (e.g. that user happens to be in Sarah's Ice Cream shop when the a message is delivered that causes the telephone to ring), they won't see the other one (because it affected the state of some other room). Returning to our air traffic control example, different groups might represent different sectors of the sky, at which point the same kinds of options arise. A programmer designing such an application will often have simple ways to realize that this is the case, and can then signal this through an appropriate system-call.
Why bother? The key question relates to the speed of the application: a communication system gains performance as its ordering obligations are relaxed. Thus, virtual synchrony is motivated by a performance objective. The system seeks to be as fast as an unreliable UDP multicast and yet to have strong fault-tolerance and ordering guarantees, similar to those of Paxos.
Failure semantics
We mentioned that there is a sense in which virtual synchrony is a weaker model than transactional one-copy serializability or state machine consensus in the style of Paxos. Partly this relates to ordering: virtual synchrony often weakens the message delivery ordering to gain performance. As mentioned above, doing so can sometimes increase robustness too. If different copies sometimes process events in different orders (doing so only when this won't have any impact on the ultimate state of the object), the copies may still be somewhat more robust against messages that cause exceptions. After all, many bugs are exquisitely sensitive to the exact sequence of events that a process experiences, so processes that see the same things but in different orders can often survive problems that would be fatal in some specific ordering.
But the other sense in which virtual synchrony is a weaker model relates to exactly what happens when some process crashes. Suppose that process p sends a multicast to a group G, and then p and some member of the group, say q, both crash. No process that remains operational has a copy of the multicast. What should the platform do?
In virtual synchrony, the group continues executing as if no message was ever sent. After all, there is no evidence to the contrary. P and q have both crashed, so they won't behave in a manner inconsistent with the model. Yet it is possible that q received p's message and delivered it to the application right before the crash. So there is a case in which virtual synchrony seems to lie: it behaves as if no message was sent, and yet the crashed processes might actually have exchanged a message.
This never happens in Paxos or transactional systems, which makes them a good match for updating database files on a disk. In both systems, if q later recovers and rejoins the group, any data it collected prior to crashing will still be valid, except to the extent that it missed updates delivered to the other group members while it was down. The cost of this guarantee is, however, quite high. Asynchronous Paxos, and transactional systems, impose a long delay before any process can deliver a message. First, these platforms make sure that the message reaches all of its destinations, asking them to delay the incoming message before delivering it. Only after the first step is completed are recipients told that it is safe to deliver the message to the application. (In one variant on these models, the platform only makes sure that a quorum (a majority) receive the message, but the delay is comparable).
The delay associated with this extra round of communication can have a big impact on performance.
Experience with virtual synchrony shows that for most applications, the weak but fast form of delivery is just fine. For rare cases where stronger guarantees are needed, the application programmer can request that a slower delivery be performed, paying an infrequent higher price, but only when necessary. The resulting performance will be much higher than if the slower, more conservative delivery property was used for every message.
Systems that support virtual synchrony
Virtual synchrony was first supported by the Cornell University and was called the "Isis Toolkit". Cornell's most current version, Vsync was released in 2013 under the name Isis2 (the name was changed from Isis2 to Vsync in 2015 in the wake of a terrorist attack in Paris by an extremist organization called ISIS), with periodic updates and revisions since that time. The most current stable release is V2.2.2020; it was released on November 14, 2015; the V2.2.2048 release is currently available in Beta form.[2] Vsync aims at the massive data centers that support cloud computing.
Other such systems include the "Horus system", the Transis system, the Totem system, an IBM system called Phoenix, a distributed security key management system called Rampart, the "Ensemble system", the Quicksilver system, "The OpenAIS project", its derivative the Corosync Cluster Engine and a number of products (including the IBM and Microsoft ones mentioned earlier). At the time of this writing,[when?] virtual synchrony toolkits that programmers can use to implement new virtually synchronous applications include the Spread Toolkit, JGroups, the C-Ensemble system, Appia, Quicksilver, and the Corosync Cluster Engine.
Cited References
- ↑ K. P. Birman (July 1999). A Review of Experiences with Reliable Multicast. 29. Software Practice and Experience. pp. 741–774. http://portal.acm.org/citation.cfm?id=326136.
- ↑ "Vsync Cloud Computing Library". http://vsync.codeplex.com.
Additional References
Reliable Distributed Systems: Technologies, Web Services and Applications. K.P. Birman. Springer Verlag (1997). Textbook, covers a broad spectrum of distributed computing concepts, including virtual synchrony.
Distributed Systems: Principles and Paradigms (2nd Edition). Andrew S. Tanenbaum, Maarten van Steen (2002). Textbook, covers a broad spectrum of distributed computing concepts, including virtual synchrony.
"The process group approach to reliable distributed computing". K.P. Birman, Communications of the ACM (CACM) 16:12 (Dec. 1993). Written for non-experts.
"Group communication specifications: a comprehensive study" Gregory V. Chockler, Idit Keidar, Roman Vitenberg. ACM Computing Surveys 33:4 (2001). Introduces a mathematical formalism for these kinds of models, then uses it to compare their expressive power and their failure detection assumptions.
"Practical Impact of Group Communication Theory." Andre Schiper. Future Directions in Distributed Computing. Springer Verlag Lecture Notes in Computer Science 2584 (July 2005). A history of the area, assumes familiarity with the general topic.
"The part-time parliament". Leslie Lamport. ACM Transactions on Computing Systems (TOCS), 16:2 (1998). Introduces the Paxos implementation of replicated state machines.
"Exploiting virtual synchrony in distributed systems". K.P. Birman and T. Joseph. Proceedings of the 11th ACM Symposium on Operating systems principles (SOSP), Austin Texas, Nov. 1987. Earliest use of the term, but probably not the best exposition of the topic.
"Reflections on the History of Operating Systems Research in Fault Tolerance". K.P. Birman. Essay accompanying a lecture delivered at the ACM SIGOPS History Day Workshop in November 2015, associated with the 25th ACM Symposium on Operating systems principles (SOSP), Monterey California, Nov. 2015. A broad overview of research on fault-tolerance by the distributed computing community, with discussion of the evolution of the virtual synchrony and Paxos protocols and comparison of their characteristics, as well as on the so-called CATOCS controversy of the 1993 period and the CAP conjecture, which is in many ways a more contemporary revisiting of CATOCS.
 |
