State observer
In control theory, a state observer or state estimator is a system that provides an estimate of the internal state of a given real system, from measurements of the input and output of the real system. It is typically computer-implemented, and provides the basis of many practical applications.
Knowing the system state is necessary to solve many control theory problems; for example, stabilizing a system using state feedback. In most practical cases, the physical state of the system cannot be determined by direct observation. Instead, indirect effects of the internal state are observed by way of the system outputs. A simple example is that of vehicles in a tunnel: the rates and velocities at which vehicles enter and leave the tunnel can be observed directly, but the exact state inside the tunnel can only be estimated. If a system is observable, it is possible to fully reconstruct the system state from its output measurements using the state observer.
Typical observer model

Linear, delayed, sliding mode, high gain, Tau, homogeneity-based, extended and cubic observers are among several observer structures used for state estimation of linear and nonlinear systems. A linear observer structure is described in the following sections.
Discrete-time case
The state of a linear, time-invariant discrete-time system is assumed to satisfy
- [math]\displaystyle{ x(k+1) = A x(k) + B u(k) }[/math]
- [math]\displaystyle{ y(k) = C x(k) + D u(k) }[/math]
where, at time [math]\displaystyle{ k }[/math], [math]\displaystyle{ x(k) }[/math] is the plant's state; [math]\displaystyle{ u(k) }[/math] is its inputs; and [math]\displaystyle{ y(k) }[/math] is its outputs. These equations simply say that the plant's current outputs and its future state are both determined solely by its current states and the current inputs. (Although these equations are expressed in terms of discrete time steps, very similar equations hold for continuous systems). If this system is observable then the output of the plant, [math]\displaystyle{ y(k) }[/math], can be used to steer the state of the state observer.
The observer model of the physical system is then typically derived from the above equations. Additional terms may be included in order to ensure that, on receiving successive measured values of the plant's inputs and outputs, the model's state converges to that of the plant. In particular, the output of the observer may be subtracted from the output of the plant and then multiplied by a matrix [math]\displaystyle{ L }[/math]; this is then added to the equations for the state of the observer to produce a so-called Luenberger observer, defined by the equations below. Note that the variables of a state observer are commonly denoted by a "hat": [math]\displaystyle{ \hat{x}(k) }[/math] and [math]\displaystyle{ \hat{y}(k) }[/math] to distinguish them from the variables of the equations satisfied by the physical system.
- [math]\displaystyle{ \hat{x}(k+1) = A \hat{x}(k) + L \left[y(k) - \hat{y}(k)\right] + B u(k) }[/math]
- [math]\displaystyle{ \hat{y}(k) = C \hat{x}(k) + D u(k) }[/math]
The observer is called asymptotically stable if the observer error [math]\displaystyle{ e(k) = \hat{x}(k) - x(k) }[/math] converges to zero when [math]\displaystyle{ k \to \infty }[/math]. For a Luenberger observer, the observer error satisfies [math]\displaystyle{ e(k+1) = (A - LC) e(k) }[/math]. The Luenberger observer for this discrete-time system is therefore asymptotically stable when the matrix [math]\displaystyle{ A - LC }[/math] has all the eigenvalues inside the unit circle.
For control purposes the output of the observer system is fed back to the input of both the observer and the plant through the gains matrix [math]\displaystyle{ K }[/math].
- [math]\displaystyle{ u(k)= -K \hat{x}(k) }[/math]
The observer equations then become:
- [math]\displaystyle{ \hat{x}(k+1) = A \hat{x}(k) + L \left(y(k) - \hat{y}(k)\right) - B K \hat{x}(k) }[/math]
- [math]\displaystyle{ \hat{y}(k) = C \hat{x}(k) - D K \hat{x}(k) }[/math]
or, more simply,
- [math]\displaystyle{ \hat{x}(k+1) = \left(A - B K \right) \hat{x}(k) + L \left(y(k) - \hat{y}(k)\right) }[/math]
- [math]\displaystyle{ \hat{y}(k) = \left(C - D K\right) \hat{x}(k) }[/math]
Due to the separation principle we know that we can choose [math]\displaystyle{ K }[/math] and [math]\displaystyle{ L }[/math] independently without harm to the overall stability of the systems. As a rule of thumb, the poles of the observer [math]\displaystyle{ A-LC }[/math] are usually chosen to converge 10 times faster than the poles of the system [math]\displaystyle{ A-BK }[/math].
Continuous-time case
The previous example was for an observer implemented in a discrete-time LTI system. However, the process is similar for the continuous-time case; the observer gains [math]\displaystyle{ L }[/math] are chosen to make the continuous-time error dynamics converge to zero asymptotically (i.e., when [math]\displaystyle{ A-LC }[/math] is a Hurwitz matrix).
For a continuous-time linear system
- [math]\displaystyle{ \dot{x} = A x + B u, }[/math]
- [math]\displaystyle{ y = C x + D u, }[/math]
where [math]\displaystyle{ x \in \mathbb{R}^n, u \in \mathbb{R}^m ,y \in \mathbb{R}^r }[/math], the observer looks similar to discrete-time case described above:
- [math]\displaystyle{ \dot{\hat{x}} = A \hat{x}+ B u + L \left(y - \hat{y}\right) }[/math].
- [math]\displaystyle{ \hat{y} = C \hat{x} + D u, }[/math]
The observer error [math]\displaystyle{ e=x-\hat{x} }[/math] satisfies the equation
- [math]\displaystyle{ \dot{e} = (A - LC) e }[/math].
The eigenvalues of the matrix [math]\displaystyle{ A-LC }[/math] can be chosen arbitrarily by appropriate choice of the observer gain [math]\displaystyle{ L }[/math] when the pair [math]\displaystyle{ [A,C] }[/math] is observable, i.e. observability condition holds. In particular, it can be made Hurwitz, so the observer error [math]\displaystyle{ e(t) \to 0 }[/math] when [math]\displaystyle{ t \to \infty }[/math].
Peaking and other observer methods
When the observer gain [math]\displaystyle{ L }[/math] is high, the linear Luenberger observer converges to the system states very quickly. However, high observer gain leads to a peaking phenomenon in which initial estimator error can be prohibitively large (i.e., impractical or unsafe to use).[1] As a consequence, nonlinear high-gain observer methods are available that converge quickly without the peaking phenomenon. For example, sliding mode control can be used to design an observer that brings one estimated state's error to zero in finite time even in the presence of measurement error; the other states have error that behaves similarly to the error in a Luenberger observer after peaking has subsided. Sliding mode observers also have attractive noise resilience properties that are similar to a Kalman filter.[2][3] Another approach is to apply multi observer, that significantly improves transients and reduces observer overshoot. Multi-observer can be adapted to every system where high-gain observer is applicable.[4]
State observers for nonlinear systems
High gain, sliding mode and extended observers are the most common observers for nonlinear systems. To illustrate the application of sliding mode observers for nonlinear systems, first consider the no-input non-linear system:
- [math]\displaystyle{ \dot{x} = f(x) }[/math]
where [math]\displaystyle{ x \in \mathbb{R}^n }[/math]. Also assume that there is a measurable output [math]\displaystyle{ y \in \mathbb{R} }[/math] given by
- [math]\displaystyle{ y = h(x). }[/math]
There are several non-approximate approaches for designing an observer. The two observers given below also apply to the case when the system has an input. That is,
- [math]\displaystyle{ \dot{x} = f(x) + B(x) u }[/math]
- [math]\displaystyle{ y = h(x). }[/math]
Linearizable error dynamics
One suggestion by Krener and Isidori[5] and Krener and Respondek[6] can be applied in a situation when there exists a linearizing transformation (i.e., a diffeomorphism, like the one used in feedback linearization) [math]\displaystyle{ z=\Phi(x) }[/math] such that in new variables the system equations read
- [math]\displaystyle{ \dot{z} = A z+ \phi(y), }[/math]
- [math]\displaystyle{ y = Cz. }[/math]
The Luenberger observer is then designed as
- [math]\displaystyle{ \dot{\hat{z}} = A \hat{z}+ \phi(y) - L \left(C \hat{z}-y \right) }[/math].
The observer error for the transformed variable [math]\displaystyle{ e=\hat{z}-z }[/math] satisfies the same equation as in classical linear case.
- [math]\displaystyle{ \dot{e} = (A - LC) e }[/math].
As shown by Gauthier, Hammouri, and Othman[7] and Hammouri and Kinnaert,[8] if there exists transformation [math]\displaystyle{ z=\Phi(x) }[/math] such that the system can be transformed into the form
- [math]\displaystyle{ \dot{z} = A(u(t)) z+ \phi(y,u(t) ), }[/math]
- [math]\displaystyle{ y = Cz, }[/math]
then the observer is designed as
- [math]\displaystyle{ \dot{\hat{z}} = A(u(t)) \hat{z}+ \phi(y,u(t) ) - L(t) \left(C \hat{z}-y \right) }[/math],
where [math]\displaystyle{ L(t) }[/math] is a time-varying observer gain.
Ciccarella, Dalla Mora, and Germani[9] obtained more advanced and general results, removing the need for a nonlinear transform and proving global asymptotic convergence of the estimated state to the true state using only simple assumptions on regularity.
Switched observers
As discussed for the linear case above, the peaking phenomenon present in Luenberger observers justifies the use of switched observers. A switched observer encompasses a relay or binary switch that acts upon detecting minute changes in the measured output. Some common types of switched observers include the sliding mode observer, nonlinear extended state observer,[10] fixed time observer,[11] switched high gain observer[12] and uniting observer.[13] The sliding mode observer uses non-linear high-gain feedback to drive estimated states to a hypersurface where there is no difference between the estimated output and the measured output. The non-linear gain used in the observer is typically implemented with a scaled switching function, like the signum (i.e., sgn) of the estimated – measured output error. Hence, due to this high-gain feedback, the vector field of the observer has a crease in it so that observer trajectories slide along a curve where the estimated output matches the measured output exactly. So, if the system is observable from its output, the observer states will all be driven to the actual system states. Additionally, by using the sign of the error to drive the sliding mode observer, the observer trajectories become insensitive to many forms of noise. Hence, some sliding mode observers have attractive properties similar to the Kalman filter but with simpler implementation.[2][3]
As suggested by Drakunov,[14] a sliding mode observer can also be designed for a class of non-linear systems. Such an observer can be written in terms of original variable estimate [math]\displaystyle{ \hat{x} }[/math] and has the form
- [math]\displaystyle{ \dot{\hat{x}} = \left [ \frac{\partial H(\hat{x})}{\partial x}\right]^{-1} M(\hat{x}) \sgn( V(t) - H(\hat{x}) ) }[/math]
where:
- The [math]\displaystyle{ \sgn(\mathord{\cdot}) }[/math] vector extends the scalar signum function to [math]\displaystyle{ n }[/math] dimensions. That is,
- [math]\displaystyle{ \sgn(z) = \begin{bmatrix} \sgn(z_1)\\ \sgn(z_2)\\ \vdots\\ \sgn(z_i)\\ \vdots\\ \sgn(z_n) \end{bmatrix} }[/math]
- for the vector [math]\displaystyle{ z \in \mathbb{R}^n }[/math].
- The vector [math]\displaystyle{ H(x) }[/math] has components that are the output function [math]\displaystyle{ h(x) }[/math] and its repeated Lie derivatives. In particular,
- [math]\displaystyle{ H(x) \triangleq \begin{bmatrix} h_1(x)\\ h_2(x)\\ h_3(x)\\ \vdots\\ h_n(x) \end{bmatrix} \triangleq \begin{bmatrix} h(x)\\ L_{f}h(x)\\ L_{f}^2 h(x)\\ \vdots\\ L_{f}^{n-1}h(x) \end{bmatrix} }[/math]
- where [math]\displaystyle{ L^i_f h }[/math] is the ith Lie derivative of output function [math]\displaystyle{ h }[/math] along the vector field [math]\displaystyle{ f }[/math] (i.e., along [math]\displaystyle{ x }[/math] trajectories of the non-linear system). In the special case where the system has no input or has a relative degree of n, [math]\displaystyle{ H(x(t)) }[/math] is a collection of the output [math]\displaystyle{ y(t)=h(x(t)) }[/math] and its [math]\displaystyle{ n-1 }[/math] derivatives. Because the inverse of the Jacobian linearization of [math]\displaystyle{ H(x) }[/math] must exist for this observer to be well defined, the transformation [math]\displaystyle{ H(x) }[/math] is guaranteed to be a local diffeomorphism.
- The diagonal matrix [math]\displaystyle{ M(\hat{x}) }[/math] of gains is such that
- [math]\displaystyle{ M(\hat{x}) \triangleq \operatorname{diag}( m_1(\hat{x}), m_2(\hat{x}), \ldots, m_n(\hat{x}) ) = \begin{bmatrix} m_1(\hat{x}) & & & & & \\ & m_2(\hat{x}) & & & & \\ & & \ddots & & & \\ & & & m_i(\hat{x}) & &\\ & & & & \ddots &\\ & & & & & m_n(\hat{x}) \end{bmatrix} }[/math]
- where, for each [math]\displaystyle{ i \in \{1,2,\dots,n\} }[/math], element [math]\displaystyle{ m_i(\hat{x}) \gt 0 }[/math] and suitably large to ensure reachability of the sliding mode.
- The observer vector [math]\displaystyle{ V(t) }[/math] is such that
- [math]\displaystyle{ V(t) \triangleq \begin{bmatrix}v_{1}(t)\\ v_2(t)\\ v_3(t)\\ \vdots\\ v_i(t)\\ \vdots\\ v_{n}(t) \end{bmatrix} \triangleq \begin{bmatrix} y(t)\\ \{ m_1(\hat{x}) \sgn( v_1(t) - h_1(\hat{x}(t)) ) \}_{\text{eq}}\\ \{ m_2(\hat{x}) \sgn( v_2(t) - h_2(\hat{x}(t)) ) \}_{\text{eq}}\\ \vdots\\ \{ m_{i-1}(\hat{x}) \sgn( v_{i-1}(t) - h_{i-1}(\hat{x}(t)) ) \}_{\text{eq}}\\ \vdots\\ \{ m_{n-1}(\hat{x}) \sgn( v_{n-1}(t) - h_{n-1}(\hat{x}(t)) ) \}_{\text{eq}} \end{bmatrix} }[/math]
- where [math]\displaystyle{ \sgn(\mathord{\cdot}) }[/math] here is the normal signum function defined for scalars, and [math]\displaystyle{ \{ \ldots \}_{\text{eq}} }[/math] denotes an "equivalent value operator" of a discontinuous function in sliding mode.
The idea can be briefly explained as follows. According to the theory of sliding modes, in order to describe the system behavior, once sliding mode starts, the function [math]\displaystyle{ \sgn( v_{i}(t)\!-\! h_{i}(\hat{x}(t)) ) }[/math] should be replaced by equivalent values (see equivalent control in the theory of sliding modes). In practice, it switches (chatters) with high frequency with slow component being equal to the equivalent value. Applying appropriate lowpass filter to get rid of the high frequency component on can obtain the value of the equivalent control, which contains more information about the state of the estimated system. The observer described above uses this method several times to obtain the state of the nonlinear system ideally in finite time.
The modified observation error can be written in the transformed states [math]\displaystyle{ e=H(x)-H(\hat{x}) }[/math]. In particular,
- [math]\displaystyle{ \begin{align} \dot{e} &= \frac{\mathrm{d}}{\mathrm{d}t} H(x) - \frac{\mathrm{d}}{\mathrm{d}t} H(\hat{x})\\ &= \frac{\mathrm{d}}{\mathrm{d}t} H(x) - M(\hat{x}) \, \sgn( V(t) - H(\hat{x}(t)) ), \end{align} }[/math]
and so
- [math]\displaystyle{ \begin{align} \begin{bmatrix} \dot{e}_1\\ \dot{e}_2\\ \vdots\\ \dot{e}_i\\ \vdots\\ \dot{e}_{n-1}\\ \dot{e}_n \end{bmatrix} &= \mathord{\overbrace{ \begin{bmatrix} \dot{h}_1(x)\\ \dot{h}_2(x)\\ \vdots\\ \dot{h}_i(x)\\ \vdots\\ \dot{h}_{n-1}(x)\\ \dot{h}_n(x) \end{bmatrix} }^{\tfrac{\mathrm{d}}{\mathrm{d}t} H(x)}} - \mathord{\overbrace{ M(\hat{x}) \, \sgn( V(t) - H(\hat{x}(t)) ) }^{\tfrac{\mathrm{d}}{\mathrm{d}t} H(\hat{x})}} = \begin{bmatrix} h_2(x)\\ h_3(x)\\ \vdots\\ h_{i+1}(x)\\ \vdots\\ h_n(x)\\ L_f^n h(x) \end{bmatrix} - \begin{bmatrix} m_1 \sgn( v_1(t) - h_1(\hat{x}(t)) )\\ m_2 \sgn( v_2(t) - h_2(\hat{x}(t)) )\\ \vdots\\ m_i \sgn( v_i(t) - h_i(\hat{x}(t)) )\\ \vdots\\ m_{n-1} \sgn( v_{n-1}(t) - h_{n-1}(\hat{x}(t)) )\\ m_n \sgn( v_n(t) - h_n(\hat{x}(t)) ) \end{bmatrix}\\ &= \begin{bmatrix} h_2(x) - m_1(\hat{x}) \sgn( \mathord{\overbrace{ \mathord{\overbrace{v_1(t)}^{v_1(t) = y(t) = h_1(x)}} - h_1(\hat{x}(t)) }^{e_1}} )\\ h_3(x) - m_2(\hat{x}) \sgn( v_2(t) - h_2(\hat{x}(t)) )\\ \vdots\\ h_{i+1}(x) - m_i(\hat{x}) \sgn( v_i(t) - h_i(\hat{x}(t)) )\\ \vdots\\ h_n(x) - m_{n-1}(\hat{x}) \sgn( v_{n-1}(t) - h_{n-1}(\hat{x}(t)) )\\ L_f^n h(x) - m_n(\hat{x}) \sgn( v_n(t) - h_n(\hat{x}(t)) ) \end{bmatrix}. \end{align} }[/math]
So:
- As long as [math]\displaystyle{ m_1(\hat{x}) \geq |h_2(x(t))| }[/math], the first row of the error dynamics, [math]\displaystyle{ \dot{e}_1 = h_2(\hat{x}) - m_1(\hat{x}) \sgn( e_1 ) }[/math], will meet sufficient conditions to enter the [math]\displaystyle{ e_1 = 0 }[/math] sliding mode in finite time.
- Along the [math]\displaystyle{ e_1 = 0 }[/math] surface, the corresponding [math]\displaystyle{ v_2(t) = \{m_1(\hat{x}) \sgn( e_1 )\}_{\text{eq}} }[/math] equivalent control will be equal to [math]\displaystyle{ h_2(x) }[/math], and so [math]\displaystyle{ v_2(t) - h_2(\hat{x}) = h_2(x) - h_2(\hat{x}) = e_2 }[/math]. Hence, so long as [math]\displaystyle{ m_2(\hat{x}) \geq |h_3(x(t))| }[/math], the second row of the error dynamics, [math]\displaystyle{ \dot{e}_2 = h_3(\hat{x}) - m_2(\hat{x}) \sgn( e_2 ) }[/math], will enter the [math]\displaystyle{ e_2 = 0 }[/math] sliding mode in finite time.
- Along the [math]\displaystyle{ e_i = 0 }[/math] surface, the corresponding [math]\displaystyle{ v_{i+1}(t) = \{\ldots\}_{\text{eq}} }[/math] equivalent control will be equal to [math]\displaystyle{ h_{i+1}(x) }[/math]. Hence, so long as [math]\displaystyle{ m_{i+1}(\hat{x}) \geq |h_{i+2}(x(t))| }[/math], the [math]\displaystyle{ (i+1) }[/math]th row of the error dynamics, [math]\displaystyle{ \dot{e}_{i+1} = h_{i+2}(\hat{x}) - m_{i+1}(\hat{x}) \sgn( e_{i+1} ) }[/math], will enter the [math]\displaystyle{ e_{i+1} = 0 }[/math] sliding mode in finite time.
So, for sufficiently large [math]\displaystyle{ m_i }[/math] gains, all observer estimated states reach the actual states in finite time. In fact, increasing [math]\displaystyle{ m_i }[/math] allows for convergence in any desired finite time so long as each [math]\displaystyle{ |h_i(x(0))| }[/math] function can be bounded with certainty. Hence, the requirement that the map [math]\displaystyle{ H:\mathbb{R}^n \to \mathbb{R}^n }[/math] is a diffeomorphism (i.e., that its Jacobian linearization is invertible) asserts that convergence of the estimated output implies convergence of the estimated state. That is, the requirement is an observability condition.
In the case of the sliding mode observer for the system with the input, additional conditions are needed for the observation error to be independent of the input. For example, that
- [math]\displaystyle{ \frac{\partial H(x)}{\partial x} B(x) }[/math]
does not depend on time. The observer is then
- [math]\displaystyle{ \dot{\hat{x}} = \left[ \frac{\partial H(\hat{x})}{\partial x} \right]^{-1} M(\hat{x}) \sgn(V(t) - H(\hat{x}))+B(\hat{x})u. }[/math]
Multi-observer
Multi-observer extends the high-gain observer structure from single to multi observer, with many models working simultaneously. This has two layers: the first consists of multiple high-gain observers with different estimation states, and the second determines the importance weights of the first layer observers. The algorithm is simple to implement and does not contain any risky operations like differentiation.[4] The idea of multiple models was previously applied to obtain information in adaptive control.[15]
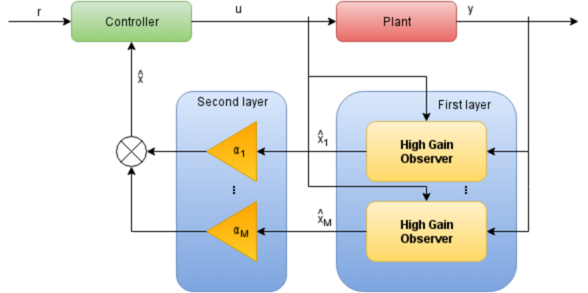
Multi-observer schema

Assuming that the number of high-gain observers equals [math]\displaystyle{ n+1 }[/math],
- [math]\displaystyle{ \dot{\hat{x}}_k(t) = A \hat{x_k}(t)+ B \phi_0(\hat{x}(t), u(t)) - L (\hat{y_k}(t)-y(t)) }[/math]
- [math]\displaystyle{ \hat{y_k}(t) = C \hat{x_k}(t) }[/math]
where [math]\displaystyle{ k = 1, \dots, n + 1 }[/math] is the observer index. The first layer observers consists of the same gain [math]\displaystyle{ L }[/math] but they differ with the initial state [math]\displaystyle{ x_k(0) }[/math]. In the second layer all [math]\displaystyle{ x_k(t) }[/math] from [math]\displaystyle{ k = 1...n + 1 }[/math] observers are combined into one to obtain single state vector estimation
- [math]\displaystyle{ \hat{y_k}(t) = \sum\limits_{k=1}^{n+1} \alpha_k(t) \hat{x_k}(t) }[/math]
where [math]\displaystyle{ \alpha_k \in \mathbb{R} }[/math] are weight factors. These factors are changed to provide the estimation in the second layer and to improve the observation process.
Let assume that
- [math]\displaystyle{ \sum\limits_{k=1}^{n+1} \alpha_k(t) \xi_k(t) = 0 }[/math]
and
- [math]\displaystyle{ \sum\limits_{k=1}^{n+1} \alpha_k(t) = 1 }[/math]
where [math]\displaystyle{ \xi_k \in \mathbb{R}^{n \times 1} }[/math] is some vector that depends on [math]\displaystyle{ kth }[/math] observer error [math]\displaystyle{ e_k(t) }[/math].
Some transformation yields to linear regression problem
- [math]\displaystyle{ [- \xi_{n + 1} (t)] = [\xi_{1}(t) - \xi_{n + 1}(t)\dots \xi_{k}(t) - \xi_{n + 1}(t)\dots \xi_{n}(t) - \xi_{n + 1}(t)]^T \begin{bmatrix} \alpha_1(t)\\ \vdots \\ \alpha_k(t)\\ \vdots\\ \alpha_n(t) \end{bmatrix} }[/math]
This formula gives possibility to estimate [math]\displaystyle{ \alpha_k (t) }[/math]. To construct manifold we need mapping [math]\displaystyle{ m: \mathbb{R}^{n} \to \mathbb{R}^{n} }[/math] between [math]\displaystyle{ \xi_k (t) = m(e_k(t)) }[/math] and ensurance that [math]\displaystyle{ \xi_k (t) }[/math] is calculable relying on measurable signals. First thing is to eliminate parking phenomenon for [math]\displaystyle{ \alpha_k(t) }[/math] from observer error
- [math]\displaystyle{ e_{\sigma}(t) = \sum\limits_{k=1}^{n+1} \alpha_k(t) e_k(t) }[/math].
Calculate [math]\displaystyle{ n }[/math] times derivative on [math]\displaystyle{ \eta_k(t)=\hat y_k (t) - y(t) }[/math] to find mapping m lead to [math]\displaystyle{ \xi_k(t) }[/math] defined as
- [math]\displaystyle{ \xi_k (t) = \begin{bmatrix} 1 & 0 & 0 & \cdots & 0 \\ CL & 1 & 0 & \cdots & 0 \\ CAL & CL & 1 & \cdots & 0 \\ CA^{2}L & CAL & CL & \cdots & 0 \\ \vdots & \vdots & \vdots & \ddots \\ CA^{n-2}L & CA^{n-3}L & CA^{n-4}L & \cdots & 1 \end{bmatrix} \begin{bmatrix} \int\limits^t_{t-t_d} {{n-1} \atop \cdots} \int\limits^t_{t-t_d} \eta_k(\tau) d\tau\\ \vdots \\ \eta(t) - \eta(t-(n-1)t_d) \end{bmatrix} }[/math]
where [math]\displaystyle{ t_d \gt 0 }[/math] is some time constant. Note that [math]\displaystyle{ \xi_k(t) }[/math] relays on both [math]\displaystyle{ \eta_k(t) }[/math] and its integrals hence it is easily available in the control system. Further [math]\displaystyle{ \alpha_k(t) }[/math] is specified by estimation law; and thus it proves that manifold is measurable. In the second layer [math]\displaystyle{ \hat\alpha_k(t) }[/math] for [math]\displaystyle{ k = 1 \dots n + 1 }[/math] is introduced as estimates of [math]\displaystyle{ \alpha_k(t) }[/math] coefficients. The mapping error is specified as
- [math]\displaystyle{ e_\xi(t) = \sum\limits_{k=1}^{n+1} \hat\alpha_k(t) \xi_k(t) }[/math]
where [math]\displaystyle{ e_\xi(t) \in \mathbb{R}^{n \times 1}, \hat\alpha_k(t) \in \mathbb{R} }[/math]. If coefficients [math]\displaystyle{ \hat\alpha(t) }[/math] are equal to [math]\displaystyle{ \alpha_k(t) }[/math] , then mapping error [math]\displaystyle{ e_\xi(t) = 0 }[/math] Now it is possible to calculate [math]\displaystyle{ \hat x }[/math] from above equation and hence the peaking phenomenon is reduced thanks to properties of manifold. The created mapping gives a lot of flexibility in the estimation process. Even it is possible to estimate the value of [math]\displaystyle{ x(t) }[/math] in the second layer and to calculate the state [math]\displaystyle{ x }[/math].[4]
Bounding observers
Bounding[16] or interval observers[17][18] constitute a class of observers that provide two estimations of the state simultaneously: one of the estimations provides an upper bound on the real value of the state, whereas the second one provides a lower bound. The real value of the state is then known to be always within these two estimations.
These bounds are very important in practical applications,[19][20] as they make possible to know at each time the precision of the estimation.
Mathematically, two Luenberger observers can be used, if [math]\displaystyle{ L }[/math] is properly selected, using, for example, positive systems properties:[21] one for the upper bound [math]\displaystyle{ \hat{x}_U(k) }[/math] (that ensures that [math]\displaystyle{ e(k) = \hat{x}_U(k) - x(k) }[/math] converges to zero from above when [math]\displaystyle{ k \to \infty }[/math], in the absence of noise and uncertainty), and a lower bound [math]\displaystyle{ \hat{x}_L(k) }[/math] (that ensures that [math]\displaystyle{ e(k) = \hat{x}_L(k) - x(k) }[/math] converges to zero from below). That is, always [math]\displaystyle{ \hat{x}_U(k) \ge x(k) \ge \hat{x}_L(k) }[/math]
See also
References
- In-line references
- ↑ Khalil, H.K. (2002), Nonlinear Systems (3rd ed.), Upper Saddle River, NJ: Prentice Hall, ISBN 978-0-13-067389-3, http://www.egr.msu.edu/~khalil/NonlinearSystems/
- ↑ 2.0 2.1 Utkin, Vadim; Guldner, Jürgen; Shi, Jingxin (1999), Sliding Mode Control in Electromechanical Systems, Philadelphia, PA: Taylor & Francis, Inc., ISBN 978-0-7484-0116-1
- ↑ 3.0 3.1 Drakunov, S.V. (1983), "An adaptive quasioptimal filter with discontinuous parameters", Automation and Remote Control 44 (9): 1167–1175
- ↑ 4.0 4.1 4.2 Bernat, J.; Stepien, S. (2015), "Multi modelling as new estimation schema for High Gain Observers", International Journal of Control 88 (6): 1209–1222, doi:10.1080/00207179.2014.1000380, Bibcode: 2015IJC....88.1209B
- ↑ Krener, A.J.; Isidori, Alberto (1983), "Linearization by output injection and nonlinear observers", System and Control Letters 3: 47–52, doi:10.1016/0167-6911(83)90037-3
- ↑ Krener, A.J.; Respondek, W. (1985), "Nonlinear observers with linearizable error dynamics", SIAM Journal on Control and Optimization 23 (2): 197–216, doi:10.1137/0323016
- ↑ Gauthier, J.P.; Hammouri, H.; Othman, S. (1992), "A simple observer for nonlinear systems applications to bioreactors", IEEE Transactions on Automatic Control 37 (6): 875–880, doi:10.1109/9.256352
- ↑ Hammouri, H.; Kinnaert, M. (1996), "A New Procedure for Time-Varying Linearization up to Output Injection", System and Control Letters 28 (3): 151–157, doi:10.1016/0167-6911(96)00022-9
- ↑ Ciccarella, G.; Dalla Mora, M.; Germani, A. (1993), "A Luenberger-like observer for nonlinear systems", International Journal of Control 57 (3): 537–556, doi:10.1080/00207179308934406
- ↑ Guo, Bao-Zhu; Zhao, Zhi-Liang (January 2011). "Extended State Observer for Nonlinear Systems with Uncertainty" (in en). IFAC Proceedings Volumes (International Federation of Automatic Control) 44 (1): 1855–1860. doi:10.3182/20110828-6-IT-1002.00399. https://www.sciencedirect.com/science/article/pii/S1474667016438802. Retrieved 8 August 2023.
- ↑ "The Wayback Machine has not archived that URL.". https://www.sciencedirect.com/science/article/pii/S240589632.Template:Dead Link
- ↑ Kumar, Sunil; Kumar Pal, Anil; Kamal, Shyam; Xiong, Xiaogang (19 May 2023). "Design of switched high-gain observer for nonlinear systems" (in en). International Journal of Systems Science (Science Publishing Group) 54 (7): 1471–1483. doi:10.1080/00207721.2023.2178863. Bibcode: 2023IJSS...54.1471K. https://www.tandfonline.com/doi/abs/10.1080/00207721.2023.2178863. Retrieved 8 August 2023.
- ↑ "Registration" (in en). https://ieeexplore.ieee.org/docum.
- ↑ Drakunov, S.V. (1992). "Sliding-mode observers based on equivalent control method". [1992] Proceedings of the 31st IEEE Conference on Decision and Control. pp. 2368–2370. doi:10.1109/CDC.1992.371368. ISBN 978-0-7803-0872-5. https://archive.org/details/proceedingsofthe0003unse/page/2368.
- ↑ Narendra, K.S.; Han, Z. (August 2012). "A new approach to adaptive control using multiple models". International Journal of Adaptive Control and Signal Processing 26 (8): 778–799. doi:10.1002/acs.2269. ISSN 1099-1115.
- ↑ Combastel, C. (2003). "A state bounding observer based on zonotopes". 2003 European Control Conference (ECC). pp. 2589–2594. doi:10.23919/ECC.2003.7085991. ISBN 978-3-9524173-7-9. http://www.nt.ntnu.no/users/skoge/prost/proceedings/ecc03/pdfs/437.pdf.
- ↑ Rami, M. Ait; Cheng, C. H.; De Prada, C. (2008). "Tight robust interval observers: An LP approach". 2008 47th IEEE Conference on Decision and Control. pp. 2967–2972. doi:10.1109/CDC.2008.4739280. ISBN 978-1-4244-3123-6. http://www.nt.ntnu.no/users/skoge/prost/proceedings/cdc-2008/data/papers/1446.pdf.
- ↑ Efimov, D.; Raïssi, T. (2016). "Design of interval observers for uncertain dynamical systems". Automation and Remote Control 77 (2): 191–225. doi:10.1134/S0005117916020016. https://hal.archives-ouvertes.fr/hal-01276439/.
- ↑ http://www.iaeng.org/publication/WCE2010/WCE2010_pp656-661.pdf[bare URL PDF]
- ↑ Hadj-Sadok, M.Z.; Gouzé, J.L. (2001). "Estimation of uncertain models of activated sludge processes with interval observers". Journal of Process Control 11 (3): 299–310. doi:10.1016/S0959-1524(99)00074-8.
- ↑ Rami, Mustapha Ait; Tadeo, Fernando; Helmke, Uwe (2011). "Positive observers for linear positive systems, and their implications". International Journal of Control 84 (4): 716–725. doi:10.1080/00207179.2011.573000. Bibcode: 2011IJC....84..716A.
- General references
- Sontag, Eduardo (1998), Mathematical Control Theory: Deterministic Finite Dimensional Systems. Second Edition, Springer, ISBN 978-0-387-98489-6
External links
- Kalman Filter Explained Simply, Step-by-Step Tutorial of the Kalman Filter with Equations
 |  |

