Biology:ABI Solid Sequencing

SOLiD (Sequencing by Oligonucleotide Ligation and Detection) is a next-generation DNA sequencing technology developed by Life Technologies and has been commercially available since 2006. This next generation technology generates 108 - 109 small sequence reads at one time. It uses 2 base encoding to decode the raw data generated by the sequencing platform into sequence data.
This method should not be confused with "sequencing by synthesis," a principle used by Roche-454 pyrosequencing (introduced in 2005, generating millions of 200-400bp reads in 2009), and the Solexa system (now owned by Illumina) (introduced in 2006, generating hundreds of millions of 50-100bp reads in 2009)
These methods have reduced the cost from $0.01/base in 2004 to nearly $0.0001/base in 2006 and increased the sequencing capacity from 1,000,000 bases/machine/day in 2004 to more than 5,000,000,000 bases/machine/day in 2009. Over 30 publications exist describing its use first for nucleosome positioning from Valouev et al.,[1] transcriptional profiling or strand sensitive RNA-Seq with Cloonan et al.,[2] single cell transcriptional profiling with Tang et al.[3] and ultimately human resequencing with McKernan et al.[4]
The method used by this machine (sequencing-by-ligation) has been reported to have some issue sequencing palindromic sequences.[5]
Chemistry
A library of DNA fragments is prepared from the sample to be sequenced, and is used to prepare clonal bead populations. That is, only one species of fragment will be present on the surface of each magnetic bead. The fragments attached to the magnetic beads will have a universal P1 adapter sequence attached so that the starting sequence of every fragment is both known and identical. Emulsion PCR takes place in microreactors containing all the necessary reagents for PCR. The beads with the resulting PCR products are deposited to a glass slide.
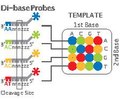
Primers hybridize to the P1 adapter sequence within the library template. A set of four fluorescently labelled di-base probes compete for ligation to the sequencing primer. Specificity of the di-base probe is achieved by interrogating every 1st and 2nd base in each ligation reaction. Multiple cycles of ligation, detection and cleavage are performed with the number of cycles determining the eventual read length. Following a series of ligation cycles, the extension product is removed and the template is reset with a primer complementary to the n-1 position for a second round of ligation cycles.
Five rounds of primer reset are completed for each sequence tag. Through the primer reset process, each base is interrogated in two independent ligation reactions by two different primers. For example, the base at read position 5 is assayed by primer number 2 in ligation cycle 2 and by primer number 3 in ligation cycle 1.
Throughput & Accuracy
According to ABI, the SOLiD 3plus platform yields 60 gigabases of usable DNA data per run. Due to the two base encoding system, an inherent accuracy check is built into the technology and offers 99.94% accuracy. The chemistry of the systems also means that it is not hindered by homopolymers unlike the Roche 454 FLX system and so large and difficult homopolymer repeat regions are no longer a problem to sequence.
Applications
Naturally the technology will be used to sequence DNA, but because of the high parallel nature of all next generation technologies they also have applications in transcriptomics and epigenomics.
Microarrays was once the mainstay of the transcriptomics the last ten years and array based technology has subsequently branched out to other areas. However, they are limited in that only information can be obtained for probes that are on the chip. Only information for organisms for which chips are available can obtained, and they come with all the problems of hybridizing large numbers of molecules (differing hybridizing temperatures). RNA-Seq transcriptomics by next gen sequencing will mean these barriers no longer hold true. Any organism's entire transcriptome could be potentially sequenced in one run (for very small bacterial genomes) and not only would the identification of each transcript be available but expression profiling is possible as quantitative reads can also be achieved.
Chromatin immunoprecipitation (ChIP) is a method for determining transcription factor binding sites and DNA-protein interactions. It has in the past been combined with array technology (ChIP-chip) with some success. Next gen sequencing can also be applied in this area. Methylation immunoprecipitation (MeDIP) can also be performed and also on arrays.
The ability to learn more about methylation and TF binding sites on a genome wide scale is a valuable resource and could teach us much about disease and molecular biology in general.
See also
- 2 Base Encoding
- Next-generation sequencing
- Applied Biosystems
- Illumina
- 454 Life Sciences
References
- ↑ "A high-resolution, nucleosome position map of C. elegans reveals a lack of universal sequence-dictated positioning". Genome Research 18 (7): 1051–63. July 2008. doi:10.1101/gr.076463.108. PMID 18477713.
- ↑ "Stem cell transcriptome profiling via massive-scale mRNA sequencing". Nature Methods 5 (7): 613–9. July 2008. doi:10.1038/nmeth.1223. PMID 18516046.
- ↑ "mRNA-Seq whole-transcriptome analysis of a single cell". Nature Methods 6 (5): 377–82. May 2009. doi:10.1038/nmeth.1315. PMID 19349980.
- ↑ "Sequence and structural variation in a human genome uncovered by short-read, massively parallel ligation sequencing using two-base encoding". Genome Research 19 (9): 1527–41. September 2009. doi:10.1101/gr.091868.109. PMID 19546169.
- ↑ Yu-Feng Huang; Sheng-Chung Chen; Yih-Shien Chiang; Tzu-Han Chen (2012). "Palindromic sequence impedes sequencing-by-ligation mechanism". BMC Systems Biology 6 (Suppl 2): S10. doi:10.1186/1752-0509-6-S2-S10. PMID 23281822.
Further reading
- Mardis ER (2008). "Next-generation DNA sequencing methods". Annual Review of Genomics and Human Genetics 9: 387–402. doi:10.1146/annurev.genom.9.081307.164359. PMID 18576944.
- Mardis ER (2009). "New strategies and emerging technologies for massively parallel sequencing: applications in medical research". Genome Medicine 1 (4): 40. doi:10.1186/gm40. PMID 19435481.
 |  |
