Perfect phylogeny
Perfect phylogeny is a term used in computational phylogenetics to denote a phylogenetic tree in which all internal nodes may be labeled such that all characters evolve down the tree without homoplasy. That is, characteristics do not hold to evolutionary convergence, and do not have analogous structures. Statistically, this can be represented as an ancestor having state "0" in all characteristics where 0 represents a lack of that characteristic. Each of these characteristics changes from 0 to 1 exactly once and never reverts to state 0. It is rare that actual data adheres to the concept of perfect phylogeny.[1][2]
Building
In general there are two different data types that are used in the construction of a phylogenetic tree. In distance-based computations a phylogenetic tree is created by analyzing relationships among the distance between species and the edge lengths of a corresponding tree. Using a character-based approach employs character states across species as an input in an attempt to find the most "perfect" phylogenetic tree.[3][4]
The statistical components of a perfect phylogenetic tree can best be described as follows:[3]
A perfect phylogeny for an n x m character state matrix M is a rooted tree T with n leaves satisfying:
i. Each row of M labels exactly one leaf of T
ii. Each column of M labels exactly one edge of T
iii. Every interior edge of T is labeled by at least one column of M
iv. The characters associated with the edges along the unique path from root to a leaf v exactly specify the character vector of v, i.e. the character vector has a 1 entry in all columns corresponding to characters associated to path edges and a 0 entry otherwise.
It is worth noting that it is very rare to find actual phylogenetic data that adheres to the concepts and limitations detailed here. Therefore, it is often the case that researchers are forced to compromise by developing trees that simply try to minimize homoplasy, finding a maximum-cardinality set of compatible characters, or constructing phylogenies that match as closely as possible to the partitions implied by the characters.
Example
Both of these data sets illustrate examples of character state matrices. Using matrix M'1 one is able to observe that the resulting phylogenetic tree can be created such that each of the characters label exactly one edge of the tree. In contrast, when observing matrix M'2, one can see that there is no way to set up the phylogenetic tree such that each character labels only one edge length.[3] If the samples come from variant allelic frequency (VAF) data of a population of cells under study, the entries in the character matrix are frequencies of mutations, and take a value between 0 and 1. Namely, if represents a position in the genome, then the entry corresponding to and sample will hold the frequencies of genomes in sample with a mutation in position .[5][6][7][8][9]
- Character state matrices
-
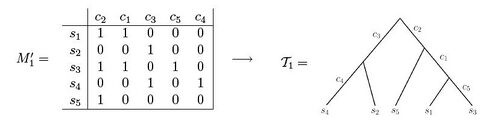 An example of a character matrix that can be depicted as a perfect phylogeny
An example of a character matrix that can be depicted as a perfect phylogeny

Usage
Perfect phylogeny is a theoretical framework that can also be used in more practical methods. One such example is that of Incomplete Directed Perfect Phylogeny. This concept involves utilizing perfect phylogenies with real, and therefore incomplete and imperfect, datasets. Such a method utilizes SINEs to determine evolutionary similarity. These Short Interspersed Elements are present across many genomes and can be identified by their flanking sequences. SINEs provide information on the inheritance of certain traits across different species. Unfortunately, if a SINE is missing it is difficult to know whether those SINEs were present prior to the deletion. By utilizing algorithms derived from perfect phylogeny data we are able to attempt to reconstruct a phylogenetic tree in spite of these limitations.[10]
Perfect phylogeny is also used in the construction of haplotype maps. By utilizing the concepts and algorithms described in perfect phylogeny one can determine information regarding missing and unavailable haplotype data.[11] By assuming that the set of haplotypes that result from genotype mapping corresponds and adheres to the concept of perfect phylogeny (as well as other assumptions such as perfect Mendelian inheritance and the fact that there is only one mutation per SNP), one is able to infer missing haplotype data.[12][13][14] [15]
Inferring a phylogeny from noisy VAF data under the PPM is a hard problem.[5] Most inference tools include some heuristic step to make inference computationally tractable. Examples of tools that infer phylogenies from noisy VAF data include AncesTree, Canopy, CITUP, EXACT, and PhyloWGS.[5][6][7][8][9] In particular, EXACT performs exact inference by using GPUs to compute a posterior probability on all possible trees for small size problems. Extensions to the PPM have been made with accompanying tools.[16][17] For example, tools such as MEDICC, TuMult, and FISHtrees allow the number of copies of a given genetic element, or ploidy, to both increase, or decrease, thus effectively allowing the removal of mutations.[18][19][20]
See also
References
- ↑ Fernandez-Baca, David. "The Perfect Phylogeny Problem". Kluwer Academic Publishers. http://www.cs.iastate.edu/~fernande/PAPERS/survey.pdf.
- ↑ "Perfect Phylogenetic Networks: A New Methodology for Reconstructing the Evolutionary History of Natural Languages". http://www.cs.rice.edu/~nakhleh/Papers/81.2nakhleh.pdf.
- ↑ 3.0 3.1 3.2 Uhler, Caroline. "Finding a Perfect Phylogeny". http://www.carolineuhler.com/paperCS.pdf.
- ↑ "Phylogenetic relationships among cetartiodactyls based on insertions of short and long interpersed elements: hippopotamuses are the closest extant relatives of whales". Proceedings of the National Academy of Sciences of the United States of America 96 (18): 10261–6. August 1999. doi:10.1073/pnas.96.18.10261. PMID 10468596. Bibcode: 1999PNAS...9610261N.
- ↑ 5.0 5.1 5.2 "Reconstruction of clonal trees and tumor composition from multi-sample sequencing data". Bioinformatics 31 (12): i62-70. June 2015. doi:10.1093/bioinformatics/btv261. PMID 26072510.
- ↑ 6.0 6.1 "Tumor phylogeny inference using tree-constrained importance sampling". Bioinformatics 33 (14): i152–i160. July 2017. doi:10.1093/bioinformatics/btx270. PMID 28882002.
- ↑ 7.0 7.1 "Clonality inference in multiple tumor samples using phylogeny". Bioinformatics 31 (9): 1349–56. May 2015. doi:10.1093/bioinformatics/btv003. PMID 25568283.
- ↑ 8.0 8.1 Ray S, Jia B, Safavi S, van Opijnen T, Isberg R, Rosch J, Bento J (2019-08-22). "Exact inference under the perfect phylogeny model". arXiv:1908.08623 [q-bio.QM].
- ↑ 9.0 9.1 "PhyloWGS: reconstructing subclonal composition and evolution from whole-genome sequencing of tumors". Genome Biology 16 (1). February 2015. doi:10.1186/s13059-015-0602-8. PMID 25786235.
- ↑ "Incomplete Directed Perfect Phylogeny". Tel-Aviv University. http://www.cs.tau.ac.il/~roded/sines.ps.
- ↑ "Efficient reconstruction of haplotype structure via perfect phylogeny". Journal of Bioinformatics and Computational Biology (University of California, Berkeley) 1 (1): 1–20. April 2003. doi:10.1142/S0219720003000174. PMID 15290779. http://www.eecs.berkeley.edu/Pubs/TechRpts/2002/CSD-02-1196.pdf. Retrieved 30 October 2012.
- ↑ Gusfield, Dan. "An Overview of Computational Methods for Haplotype Inference". University of California, Davis. http://csiflabs.cs.ucdavis.edu/~gusfield/hapreview.pdf.
- ↑ "A Linear Time Algorithm for the Perfect Phylogeny Haplotyping Problem". University of California, Davis. http://csiflabs.cs.ucdavis.edu/~gusfield/LPPH_RECOMB05.ppt.
- ↑ "Haplotyping as perfect phylogeny: a direct approach". Journal of Computational Biology 10 (3–4): 323–40. 2003. doi:10.1089/10665270360688048. PMID 12935331.
- ↑ Seyalioglu, Hakan. "Haplotyping as Perfect Phylogeny". https://www.math.ucla.edu/~roch/285k.1.10s/HakanS.pdf.
- ↑ "Explaining evolution via constrained persistent perfect phylogeny". BMC Genomics 15 Suppl 6 (S6). October 2014. doi:10.1186/1471-2164-15-S6-S10. PMID 25572381.
- ↑ Hajirasouliha, Iman; Raphael, Benjamin J. (2014), Brown, Dan; Morgenstern, Burkhard, eds., "Reconstructing Mutational History in Multiply Sampled Tumors Using Perfect Phylogeny Mixtures", Algorithms in Bioinformatics, Lecture Notes in Computer Science (Springer Berlin Heidelberg) 8701: pp. 354–367, doi:10.1007/978-3-662-44753-6_27, ISBN 978-3-662-44752-9
- ↑ Beerenwinkel, Niko, ed (April 2014). "Phylogenetic quantification of intra-tumour heterogeneity". PLOS Computational Biology 10 (4). doi:10.1371/journal.pcbi.1003535. PMID 24743184. Bibcode: 2014PLSCB..10E3535S.
- ↑ "Analysis of the copy number profiles of several tumor samples from the same patient reveals the successive steps in tumorigenesis". Genome Biology 11 (7). 2010. doi:10.1186/gb-2010-11-7-r76. PMID 20649963.
- ↑ "FISHtrees 3.0: Tumor Phylogenetics Using a Ploidy Probe". PLOS ONE 11 (6). 2016-06-30. doi:10.1371/journal.pone.0158569. PMID 27362268. Bibcode: 2016PLoSO..1158569G.
External links
- One of several programs available for analysis and creation of phylogenetic trees
- Another such program for phylogenetic tree analysis
- Additional program for tree analysis
- A paper detailing an example of how perfect phylogeny can be utilized outside of the field of genetics, as in language association
- Github for "Algorithm for clonal tree reconstruction from multi-sample cancer sequencing data" (AncesTree)
- Github for "Accessing Intra-Tumor Heterogeneity and Tracking Longitudinal and Spatial Clonal Evolutionary History by Next-Generation Sequencing" (Canopy)
- Github for "Clonality Inference in Tumors Using Phylogeny" (CITUP)
- Github for "Exact inference under the perfect phylogeny model" (EXACT)
- Github for "Reconstructing subclonal composition and evolution from whole-genome sequencing of tumors" (PhyloWGS)
 |  |
