k-medoids
The k-medoids method is a classical partitioning technique of clustering that splits a data set of n objects into k clusters, where the number k of clusters is assumed to be known a priori (which implies that the programmer must specify k before the execution of a k-medoids algorithm). The "goodness" of the given value of k can be assessed with methods such as the silhouette method. The name of the clustering method was coined by Leonard Kaufman and Peter J. Rousseeuw with their PAM (Partitioning Around Medoids) algorithm.[1]
The medoid of a cluster is defined as the object in the cluster whose sum (and, equivalently, the average) of dissimilarities to all the objects in the cluster is minimal, that is, it is a most centrally located point in the cluster. Unlike certain objects used by other algorithms, the medoid is an actual point in the cluster.
As every point is typically assigned to its nearest medoid, the method (similar to k-means) does not work well if clusters vary significantly in diameter. If clusters vary in diameter or shape, other clustering method such as Gaussian mixture modeling or density-based clustering may work better.
Algorithms

In general, the k-medoids problem is NP-hard to solve exactly.[2] As such, multiple heuristics to optimize this problem exist.
Partitioning Around Medoids (PAM)
PAM[1] uses a greedy search method which may not find the optimum solution, but is faster than exhaustive search. It works as follows:
- (BUILD) Initialize: greedily select k of the n data points as the medoids to minimize the cost
- Associate each data point to the closest medoid.
- (SWAP) While the cost of the configuration decreases:
- For each medoid m, and for each non-medoid data point o:
- Consider the swap of m and o, and compute the cost change
- If the cost change is the current best, remember this m and o combination
- Perform the best swap of and , if it decreases the cost function. Otherwise, the algorithm terminates.
- For each medoid m, and for each non-medoid data point o:
The runtime complexity of the original PAM algorithm per iteration of (3) is , by only computing the change in cost. A naive implementation recomputing the entire cost function every time will be in . This runtime can be further reduced to , by splitting the cost change into three parts such that computations can be shared or avoided (FastPAM). The runtime can further be reduced by eagerly performing swaps (FasterPAM),[3] at which point a random initialization becomes a viable alternative to BUILD.
Alternating optimization
Algorithms other than PAM have also been suggested in the literature, including the following Voronoi iteration method known as the "Alternating" heuristic in literature, as it alternates between two optimization steps:[4][5][6]
- Select initial medoids randomly
- Iterate while the cost decreases:
- In each cluster, make the point that minimizes the sum of distances within the cluster the medoid
- Reassign each point to the cluster defined by the closest medoid determined in the previous step
k-means-style Voronoi iteration tends to produce worse results, and exhibit "erratic behavior".[7]: 957 Because it does not allow reassigning points to other clusters while updating means it only explores a smaller search space. It can be shown that even in simple cases this heuristic finds inferior solutions the swap based methods can solve.[3]
Hierarchical clustering
Multiple variants of hierarchical clustering with a "medoid linkage" have been proposed. The Minimum Sum linkage criterion[8] directly uses the objective of medoids, but the Minimum Sum Increase linkage was shown to produce better results (similar to how Ward linkage uses the increase in squared error). Earlier approaches simply used the distance of the cluster medoids of the previous medoids as linkage measure,[9][10] but which tends to result in worse solutions, as the distance of two medoids does not ensure there exists a good medoid for the combination. These approaches have a run time complexity of , and when the dendrogram is cut at a particular number of clusters k, the results will typically be worse than the results found by PAM.[8] Hence these methods are primarily of interest when a hierarchical tree structure is desired.
Other algorithms
Other approximate algorithms such as CLARA and CLARANS trade quality for runtime. CLARA applies PAM on multiple subsamples, keeping the best result. By setting the sample size to , a linear runtime (just as to k-means) can be achieved. CLARANS works on the entire data set, but only explores a subset of the possible swaps of medoids and non-medoids using sampling. BanditPAM uses the concept of multi-armed bandits to choose candidate swaps instead of uniform sampling as in CLARANS.[11]
Visualization of the medoid-based clustering process
Purpose
Visualization of medoid-based clustering can be helpful when trying to understand how medoid-based clustering work. Studies have shown that people learn better with visual information.[12] In medoid-based clustering, the medoid is the center of the cluster. This is different from k-means clustering, where the center isn't a real data point, but instead can lie between data points. We use the medoid to group “clusters” of data, which is obtained by finding the element with minimal average dissimilarity to all other objects in the cluster.[13] Although the visualization example used utilizes k-medoids clustering, the visualization can be applied to k-means clustering as well by swapping out average dissimilarity with the mean of the dataset being used.
Visualization using one-dimensional data
Distance matrix

A distance matrix is required for medoid-based clustering, which is generated using Jaccard Dissimilarity (which is 1 - the Jaccard Index). This distance matrix is used to calculate the distance between two points on a one-dimensional graph. The above image shows an example of a Jaccard Dissimilarity graph.
Clustering
- Step 1
Medoid-based clustering is used to find clusters within a dataset. An initial one-dimensional dataset which contains clusters that need to be discovered is used for the process of medoid-based clustering. In the image below, there are twelve different objects in the dataset at varying x-positions.

- Step 2
K random points are chosen to be the initial centers. The value chosen for K is known as the K-value. In the image below, 3 has been chosen as the K-value. The process for finding the optimal K-value will be discussed in step 7.

- Step 3
Each non-center object is assigned to its nearest center. This is done using a distance matrix. The lower the dissimilarity, the closer the points are. In the image below, there are 5 objects in cluster 1, 3 in cluster 2, and 4 in cluster 3.

- Step 4
The new center for each cluster is found by finding the object whose average dissimilarity to all other objects in the cluster is minimal. The center selected during this step is called the medoid. The image below shows the results of medoid selection.

- Step 5
Steps 3-4 are repeated until the centers no longer move, as in the images below.
- Repeating Steps 3-4 (from left to right)
-
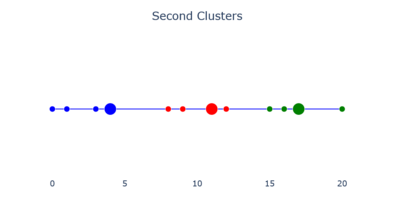 The second clusters.
The second clusters. -
 Medoid selection.
Medoid selection. -
 The third clusters.
The third clusters. -
Final medoid selection.



- Step 6
The final clusters are obtained when the centers no longer move between steps. The image below shows what a final cluster can look like.

- Step 7
The variation[clarification needed (variation of what?)] is added up within each cluster to see how accurate the centers are. By running this test with different K-values, an "elbow" of the variation graph can be acquired, where the graph's variation levels out. The "elbow" of the graph is the optimal K-value for the dataset.
Comparison to k-means clustering
This section may require copy editing for being a bit informal ("lack consistency because the results may vary"), language issues ("performing the algorithm") and poorly sourced claims.. (October 2025) (Learn how and when to remove this template message) |
The k-medoids problem is a clustering problem similar to k-means. Both the k-means and k-medoids algorithms are partitional (breaking the dataset up into groups) and attempt to minimize the distance between points labeled to be in a cluster and a point designated as the center of that cluster. In contrast to the k-means algorithm, k-medoids chooses actual data points as centers (medoids or exemplars), and thereby allows for greater interpretability of the cluster centers than in k-means, where the center of a cluster is not necessarily one of the input data points (it is the average between the points in the cluster known as the centroid). Furthermore, k-medoids can be used with arbitrary dissimilarity measures, whereas k-means generally requires Euclidean distance for efficient solutions. Because k-medoids minimizes a sum of pairwise dissimilarities instead of a sum of squared Euclidean distances, it is more robust to noise and outliers than k-means.
Despite these advantages, the results of k-medoids lack consistency since the results of the algorithm may vary. This is because the initial medoids are chosen at random during the performance of the algorithm. k-medoids is also not suitable for clustering objects that are not spherical and may work inefficiently when dealing with large datasets depending on how it is implemented. Meanwhile, k-means is suitable for well-distributed and isotropic clusters and can handle larger datasets.[14] Similarly to k-medoids however, k-means also uses random initial points which varies the results the algorithm finds.
| K-medoids | K-means | |
|---|---|---|
| Cluster Representation | Uses medoids to represent clusters. | Uses centroids to represent clusters. |
| Distance Metrics | Can use any distance metric. | Only optimizes squared Euclidean distance. |
| Computational Efficiency | Runtime of most algorithms is quadratic in the size of the dataset. | Linear in the size of the data set if the number of iterations is fixed. |
| Outlier Sensitivity | Less sensitive to outliers and noise.[15] | Highly sensitive to noise and outliers.[14] |
| Cluster Shape | Not suitable for clusters of arbitrary shape.[15] | Best if clusters are normally distributed and isotropic.[16] |
K-medoids in high dimensions
A common problem with k-medoids clustering and other medoid-based clustering algorithms is the "curse of dimensionality," in which the data points contain too many dimensions or features. As dimensions are added to the data, the distance between them becomes sparse,[17] and it becomes difficult to characterize clustering by Euclidean distance alone. As a result, distance based similarity measures converge to a constant [18] and we have a characterization of distance between points which may not be reflect our data set in meaningful ways.
One way to mitigate the effects of the curse of dimensionality is by using spectral clustering. Spectral clustering achieves a more appropriate analysis by reducing the dimensionality of then data using principal component analysis, projecting the data points into the lower dimensional subspace, and then running the chosen clustering algorithm as before. One thing to note, however, is that as with any dimension reduction we lose information,[19] so it must be weighed against clustering in advanced how much reduction is necessary before too much data is lost.
High dimensionality doesn't only affect distance metrics however, as the time complexity also increases with the number of features. k-medoids is sensitive to initial choice of medoids, as they are usually selected randomly. Depending on how such medoids are initialized, k-medoids may converge to different local optima, resulting in different clusters and quality measures,[20] meaning k-medoids might need to run multiple times with different initializations, resulting in a much higher run time. One way to counterbalance this is to use k-medoids++,[21] an alternative to k-medoids similar to its k-means counterpart, k-means++ which chooses initial medoids to begin with based on a probability distribution, as a sort of "informed randomness" or educated guess if you will. If such medoids are chosen with this rationale, the result is an improved runtime and better performance in clustering. The k-medoids++ algorithm is described as follows:[21]
- The initial medoid is chosen randomly among all of the spatial points.
- For each spatial point 𝑝, compute the distance between 𝑝 and the nearest medoids which is termed as D(𝑝) and sum all the distances to 𝑆 .
- The next medoid is determined by using weighted probability distribution. Specifically, a random number 𝑅 between zero and the summed distance 𝑆 is chosen and the corresponding spatial point is the next medoid.
- Step (2) and Step (3) are repeated until 𝑘 medoids have been chosen.
Now that we have appropriate first selections for medoids, the normal variation of k-medoids can be run.
Packages
 | This section may lend undue weight to Python and scikit-learn-extra. (April 2025) (Learn how and when to remove this template message) |
Several software packages provide implementations of k-medoids clustering algorithms. These implementations vary in their algorithmic approaches and computational efficiency.
scikit-learn-extra
The scikit-learn-extra[22] package includes a KMedoids class that implements k-medoids clustering with a Scikit-learn compatible interface. It offers two algorithm choices:
- The original PAM algorithm
- An alternate optimization method that is faster but less accurate
Parameters include:
- n_clusters: The number of clusters to form (default is 8)
- metric: The distance metric to use (default is Euclidean distance)
- method: The algorithm to use ('pam' or 'alternate')
- init: The medoid initialization method (options include 'random', 'heuristic', 'k-medoids++', and 'build')
- max_iter: The maximum number of iterations (default is 300)
Example Python usage:
from sklearn_extra.cluster import KMedoids
kmedoids = KMedoids(n_clusters=2, method="pam").fit(X)
print(kmedoids.labels_)
kmedoids
The Python kmedoids[23] package provides optimized implementations of PAM and related algorithms:
- FasterPAM: An improved version with better time complexity
- FastPAM1: An earlier optimization of PAM
- DynMSC: A method for automatic cluster number selection
This package expects precomputed dissimilarity matrices and includes silhouette-based methods for evaluating clusters.
Example Python usage:
import kmedoids
from sklearn.metrics import pairwise_distances
dissimilarity_matrix = pairwise_distances(X, metric="euclidean")
fp = kmedoids.fasterpam(dissimilarity_matrix, n_clusters=2)
print(fp.medoids)
Alternatively, the scikit-learn compatible API can be used, which can compute the distance matrix:
from kmedoids import KMedoids
kmedoids = KMedoids(n_clusters=2, metric="euclidean").fit(X)
print(kmedoids.labels_)
print("Selected medoids: ", kmedoids.medoid_indices_)
Comparison
| Feature | scikit-learn-extra | kmedoids |
|---|---|---|
| Algorithms | PAM, Alternating | FasterPAM, PAM, FastPAM1, Alternating |
| Distance metrics | Various | Precomputed, various in scikit-learn API |
| Automatic selection | No | Yes |
| API style | scikit-learn | Standalone and scikit-learn |
Software
- ELKI provides several k-medoid variants, including a Voronoi-iteration k-medoids, the original PAM algorithm, Reynolds' improvements, the O(n²) FastPAM and FasterPAM algorithms, CLARA, CLARANS, FastCLARA and FastCLARANS.
- Julia contains a k-medoid implementation of the k-means style algorithm (fast, but much worse result quality) in the JuliaStats/Clustering.jl package.
- KNIME includes a basic k-medoid implementation supporting multiple distance measures. The exact algorithm is not documented besides using "exhaustive search".
- MATLAB implements PAM, CLARA and two algorithms named "small" and "large" based on k-means style iterations to solve the k-medoid clustering problem.
- Python contains FasterPAM and other variants in the "kmedoids" package, additional implementations can be found in, e.g., scikit-learn-extra and pyclustering.
- R contains PAM in the "cluster" package, including the FasterPAM improvements via the options
variant = "faster"andmedoids = "random". There also exists a "fastkmedoids" package. - RapidMiner has an operator named KMedoids, but it does not implement any of above KMedoids algorithms. Instead, it is a k-means variant, that substitutes the mean with the closest data point (which is not the medoid), which combines the drawbacks of k-means (limited to coordinate data) with the additional cost of finding the nearest point to the mean.
- Rust has a "kmedoids" crate that also includes the FasterPAM variant.
References
- ↑ 1.0 1.1 Kaufman, Leonard; Rousseeuw, Peter J. (1990-03-08), "Partitioning Around Medoids (Program PAM)" (in en), Wiley Series in Probability and Statistics (Hoboken, NJ, USA: John Wiley & Sons, Inc.): pp. 68–125, doi:10.1002/9780470316801.ch2, ISBN 978-0-470-31680-1, http://doi.wiley.com/10.1002/9780470316801.ch2, retrieved 2021-06-13
- ↑ Hsu, Wen-Lian; Nemhauser, George L. (1979). "Easy and hard bottleneck location problems". Discrete Applied Mathematics 1 (3): 209–215. doi:10.1016/0166-218X(79)90044-1. https://dx.doi.org/10.1016/0166-218X%2879%2990044-1.
- ↑ 3.0 3.1 Schubert, Erich; Rousseeuw, Peter J. (2021). "Fast and eager k -medoids clustering: O(k) runtime improvement of the PAM, CLARA, and CLARANS algorithms" (in en). Information Systems 101. doi:10.1016/j.is.2021.101804. https://linkinghub.elsevier.com/retrieve/pii/S0306437921000557.
- ↑ Maranzana, F. E. (1963). "On the location of supply points to minimize transportation costs". IBM Systems Journal 2 (2): 129–135. doi:10.1147/sj.22.0129.
- ↑ T. Hastie, R. Tibshirani, and J. Friedman. The Elements of Statistical Learning, Springer (2001), 468–469.
- ↑ Park, Hae-Sang; Jun, Chi-Hyuck (2009). "A simple and fast algorithm for K-medoids clustering" (in en). Expert Systems with Applications 36 (2): 3336–3341. doi:10.1016/j.eswa.2008.01.039.
- ↑ Teitz, Michael B.; Bart, Polly (1968-10-01). "Heuristic Methods for Estimating the Generalized Vertex Median of a Weighted Graph". Operations Research 16 (5): 955–961. doi:10.1287/opre.16.5.955. ISSN 0030-364X.
- ↑ 8.0 8.1 Schubert, Erich (2021). "HACAM: Hierarchical Agglomerative Clustering Around Medoids – and its Limitations". LWDA'21: Lernen, Wissen, Daten, Analysen September 01–03, 2021, Munich, Germany. pp. 191–204. http://star.informatik.rwth-aachen.de/Publications/CEUR-WS/Vol-2993/paper-19.pdf.
- ↑ Miyamoto, Sadaaki; Kaizu, Yousuke; Endo, Yasunori (2016). "Hierarchical and Non-Hierarchical Medoid Clustering Using Asymmetric Similarity Measures". 2016 Joint 8th International Conference on Soft Computing and Intelligent Systems (SCIS) and 17th International Symposium on Advanced Intelligent Systems (ISIS). pp. 400–403. doi:10.1109/SCIS-ISIS.2016.0091.
- ↑ Herr, Dominik; Han, Qi; Lohmann, Steffen; Ertl, Thomas (2016). "Visual Clutter Reduction through Hierarchy-based Projection of High-dimensional Labeled Data" (in en-CA). Graphics Interface. doi:10.20380/gi2016.14. https://graphicsinterface.org/wp-content/uploads/gi2016-14.pdf. Retrieved 2022-11-04.
- ↑ Tiwari, Mo; Zhang, Martin J.; Mayclin, James; Thrun, Sebastian; Piech, Chris; Shomorony, Ilan (2020). "BanditPAM: Almost Linear Time k-Medoids Clustering via Multi-Armed Bandits" (in en). Advances in Neural Information Processing Systems 33. https://proceedings.neurips.cc/paper/2020/hash/73b817090081cef1bca77232f4532c5d-Abstract.html.
- ↑ Midway, Stephen R. (December 2020). "Principles of Effective Data Visualization". Patterns 1 (9). doi:10.1016/j.patter.2020.100141. PMID 33336199.
- ↑ "Clustering by Means of Medoids". https://www.researchgate.net/publication/243777819.
- ↑ 14.0 14.1 "Advantages and disadvantages of k-means | Machine Learning" (in en). https://developers.google.com/machine-learning/clustering/kmeans/advantages-disadvantages.
- ↑ 15.0 15.1 "The K-Medoids Clustering Algorithm From "means" to "medoids"". https://www2.seas.gwu.edu/~bell/csci243/lectures/K_medoids.pdf.
- ↑ "Demonstration of k-means assumptions" (in en). https://scikit-learn.org/stable/auto_examples/cluster/plot_kmeans_assumptions.html.
- ↑ "Curse of Dimensionality". 17 May 2019. https://deepai.org/machine-learning-glossary-and-terms/curse-of-dimensionality.
- ↑ "K-Means Advantages and Disadvantages | Machine Learning". https://developers.google.com/machine-learning/clustering/algorithm/advantages-disadvantages.
- ↑ Singh, Shivangi (10 April 2022). "K Means Clustering on High Dimensional Data". Medium. https://medium.com/swlh/k-means-clustering-on-high-dimensional-data-d2151e1a4240.
- ↑ "What are the main drawbacks of using k-means for high-dimensional data?". https://www.linkedin.com/advice/3/what-main-drawbacks-using-k-means-high-dimensional.[self-published source?]
- ↑ 21.0 21.1 Yue, Xia (2015). "Parallel K-Medoids++ Spatial Clustering Algorithm Based on MapReduce". arXiv:1608.06861 [cs.DC].
- ↑ "sklearn_extra.cluster.KMedoids — scikit-learn-extra 0.3.0 documentation". https://scikit-learn-extra.readthedocs.io/en/stable/generated/sklearn_extra.cluster.KMedoids.html.
- ↑ kmedoids: k-Medoids Clustering in Python with FasterPAM, https://pypi.org/project/kmedoids/, retrieved 2025-04-29
 |  |
