Randomised decision rule
In statistical decision theory, a randomised decision rule or mixed decision rule is a decision rule that associates probabilities with deterministic decision rules. In finite decision problems, randomised decision rules define a risk set which is the convex hull of the risk points of the nonrandomised decision rules.
As nonrandomised alternatives always exist to randomised Bayes rules, randomisation is not needed in Bayesian statistics, although frequentist statistical theory sometimes requires the use of randomised rules to satisfy optimality conditions such as minimax, most notably when deriving confidence intervals and hypothesis tests about discrete probability distributions.
A statistical test making use of a randomized decision rule is called a randomized test.
Definition and interpretation
Let be a set of non-randomised decision rules with associated probabilities . Then the randomised decision rule is defined as and its associated risk function is .[1] This rule can be treated as a random experiment in which the decision rules are selected with probabilities respectively.[2]
Alternatively, a randomised decision rule may assign probabilities directly on elements of the actions space for each member of the sample space. More formally, denotes the probability that an action is chosen. Under this approach, its loss function is also defined directly as: .[3]
The introduction of randomised decision rules thus creates a larger decision space from which the statistician may choose his decision. As non-randomised decision rules are a special case of randomised decision rules where one decision or action has probability 1, the original decision space is a proper subset of the new decision space .[4]
Selection of randomised decision rules

As with nonrandomised decision rules, randomised decision rules may satisfy favourable properties such as admissibility, minimaxity and Bayes. This shall be illustrated in the case of a finite decision problem, i.e. a problem where the parameter space is a finite set of, say, elements. The risk set, henceforth denoted as , is the set of all vectors in which each entry is the value of the risk function associated with a randomised decision rule under a certain parameter: it contains all vectors of the form . Note that by the definition of the randomised decision rule, the risk set is the convex hull of the risks .[5]
In the case where the parameter space has only two elements and , this constitutes a subset of , so it may be drawn with respect to the coordinate axes and corresponding to the risks under and respectively.[6] An example is shown on the right.
Admissibility
An admissible decision rule is one that is not dominated by any other decision rule, i.e. there is no decision rule that has equal risk as or lower risk than it for all parameters and strictly lower risk than it for some parameter. In a finite decision problem, the risk point of an admissible decision rule has either lower x-coordinates or y-coordinates than all other risk points or, more formally, it is the set of rules with risk points of the form such that . Thus the left side of the lower boundary of the risk set is the set of admissible decision rules.[6][7]
Minimax
A minimax Bayes rule is one that minimises the supremum risk among all decision rules in . Sometimes, a randomised decision rule may perform better than all other nonrandomised decision rules in this regard.[1]
In a finite decision problem with two possible parameters, the minimax rule can be found by considering the family of squares .[8] The value of for the smallest of such squares that touches is the minimax risk and the corresponding point or points on the risk set is the minimax rule.
If the risk set intersects the line , then the admissible decision rule lying on the line is minimax. If or holds for every point in the risk set, then the minimax rule can either be an extreme point (i.e. a nonrandomised decision rule) or a line connecting two extreme points (nonrandomised decision rules).[9][6]
-
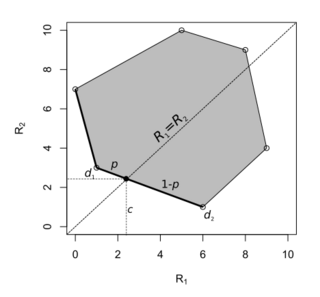 The minimax rule is the randomised decision rule .
The minimax rule is the randomised decision rule . -
 The minimax rule is .
The minimax rule is . -
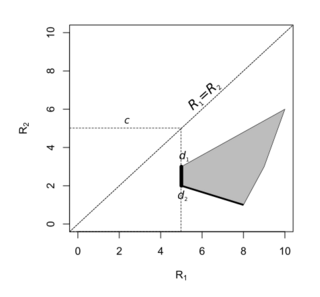 The minimax rules are all rules of the form , .
The minimax rules are all rules of the form , .



Bayes
A randomised Bayes rule is one that has infimum Bayes risk among all decision rules. In the special case where the parameter space has two elements, the line , where and denote the prior probabilities of and respectively, is a family of points with Bayes risk . The minimum Bayes risk for the decision problem is therefore the smallest such that the line touches the risk set.[10][11] This line may either touch only one extreme point of the risk set, i.e. correspond to a nonrandomised decision rule, or overlap with an entire side of the risk set, i.e. correspond to two nonrandomised decision rules and randomised decision rules combining the two. This is illustrated by the three situations below:
-
 The Bayes rules are the set of decision rules of the form , .
The Bayes rules are the set of decision rules of the form , . -
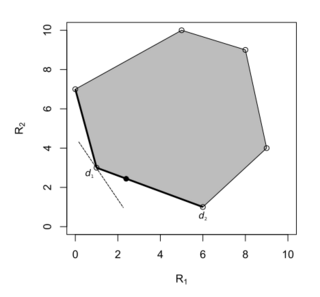 The Bayes rule is .
The Bayes rule is . -
 The Bayes rule is .
The Bayes rule is .



As different priors result in different slopes, the set of all rules that are Bayes with respect to some prior are the same as the set of admissible rules.[12]
Note that no situation is possible where a nonrandomised Bayes rule does not exist but a randomised Bayes rule does. The existence of a randomised Bayes rule implies the existence of a nonrandomised Bayes rule. This is also true in the general case, even with infinite parameter space, infinite Bayes risk, and regardless of whether the infimum Bayes risk can be attained.[3][12] This supports the intuitive notion that the statistician need not utilise randomisation to arrive at statistical decisions.[4]
In practice
As randomised Bayes rules always have nonrandomised alternatives, they are unnecessary in Bayesian statistics. However, in frequentist statistics, randomised rules are theoretically necessary under certain situations,[13] and were thought to be useful in practice when they were first invented: Egon Pearson forecast that they 'will not meet with strong objection'.[14] However, few statisticians actually implement them nowadays.[14][15]
Randomised test
Randomized tests should not be confused with permutation tests.[16]
In the usual formulation of the likelihood ratio test, the null hypothesis is rejected whenever the likelihood ratio is smaller than some constant , and accepted otherwise. However, this is sometimes problematic when is discrete under the null hypothesis, when is possible.
A solution is to define a test function , whose value is the probability at which the null hypothesis is accepted:[17][18]
This can be interpreted as flipping a biased coin with a probability of returning heads whenever and rejecting the null hypothesis if a heads turns up.[15]
A generalised form of the Neyman–Pearson lemma states that this test has maximum power among all tests at the same significance level , that such a test must exist for any significance level , and that the test is unique under normal situations.[19]
As an example, consider the case where the underlying distribution is Bernoulli with probability , and we would like to test the null hypothesis against the alternative hypothesis . It is natural to choose some such that , and reject the null whenever , where is the test statistic. However, to take into account cases where , we define the test function:
where is chosen such that .
Randomised confidence intervals
An analogous problem arises in the construction of confidence intervals. For instance, the Clopper-Pearson interval is always conservative because of the discrete nature of the binomial distribution. An alternative is to find the upper and lower confidence limits and by solving the following equations:[14]
where is a uniform random variable on (0, 1).
See also
- Mixed strategy
- Linear programming
Footnotes
- ↑ 1.0 1.1 Young and Smith, p. 11
- ↑ Bickel and Doksum, p. 28
- ↑ 3.0 3.1 Parmigiani, p. 132
- ↑ 4.0 4.1 DeGroot, p.128-129
- ↑ Bickel and Doksum, p.29
- ↑ 6.0 6.1 6.2 Young and Smith, p.12
- ↑ Bickel and Doksum, p. 32
- ↑ Bickel and Doksum, p.30
- ↑ Young and Smith, pp.14–16
- ↑ Young and Smith, p. 13
- ↑ Bickel and Doksum, pp. 29–30
- ↑ 12.0 12.1 Bickel and Doksum, p.31
- ↑ Robert, p.66
- ↑ 14.0 14.1 14.2 Agresti and Gottard, p.367
- ↑ 15.0 15.1 Bickel and Doksum, p.224
- ↑ Onghena, Patrick (2017-10-30), Berger, Vance W., ed., "Randomization Tests or Permutation Tests? A Historical and Terminological Clarification" (in en), Randomization, Masking, and Allocation Concealment (Boca Raton, FL: Chapman and Hall/CRC): pp. 209–228, doi:10.1201/9781315305110-14, ISBN 978-1-315-30511-0, https://www.taylorfrancis.com/books/9781315305103/chapters/10.1201/9781315305110-14, retrieved 2021-10-08
- ↑ Young and Smith, p.68
- ↑ Robert, p.243
- ↑ Young and Smith, p.68
Bibliography
- Agresti, Alan; Gottard, Anna (2005). "Comment: Randomized Confidence Intervals and the Mid-P Approach". Statistical Science 5 (4): 367–371. doi:10.1214/088342305000000403. http://users.stat.ufl.edu/~aa/articles/agresti_gottard_2005.pdf.
- Bickel, Peter J.; Doksum, Kjell A. (2001). Mathematical statistics : basic ideas and selected topics (2nd ed.). Upper Saddle River, NJ: Prentice-Hall. ISBN 978-0138503635.
- DeGroot, Morris H. (2004). Optimal statistical decisions. Hoboken, N.J: Wiley-Interscience. ISBN 978-0471680291.
- Parmigiani, Giovanni; Inoue, Lurdes Y T (2009). Decision theory : principles and approaches. Chichester, West Sussex: John Wiley and Sons. ISBN 9780470746684.
- Robert, Christian P (2007). The Bayesian choice : from decision-theoretic foundations to computational implementation. New York: Springer. ISBN 9780387715988.
- Young, G.A.; Smith, R.L. (2005). Essentials of Statistical Inference. Cambridge: Cambridge University Press. ISBN 9780521548663.
 |  |
