Roofline model

The roofline model is an intuitive visual performance model used to provide performance estimates of a given compute kernel or application running on multi-core, many-core, or accelerator processor architectures, by showing inherent hardware limitations, and potential benefit and priority of optimizations. By combining locality, bandwidth, and different parallelization paradigms into a single performance figure, the model can be an effective alternative to assess the quality of attained performance instead of using simple percent-of-peak estimates, as it provides insights on both the implementation and inherent performance limitations.
The most basic roofline model can be visualized by plotting floating-point performance as a function of machine peak performance[vague][clarification needed], machine peak bandwidth, and arithmetic intensity. The resultant curve is effectively a performance bound under which kernel or application performance exists, and includes two platform-specific performance ceilings[clarification needed]: a ceiling derived from the memory bandwidth and one derived from the processor's peak performance (see figure on the right).
Related terms and performance metrics
Work
The work denotes the number of operations performed by a given kernel or application.[1] This metric may refer to any type of operation, from number of array points updated, to number of integer operations, to number of floating point operations (FLOPs),[2] and the choice of one or another is driven by convenience. In the majority of the cases however, is expressed as FLOPs.[1][3][4][5][6]
Note that the work is a property of the given kernel or application and thus depend just partially on the platform characteristics.
Memory traffic
The memory traffic denotes the number of bytes of memory transfers incurred during the execution of the kernel or application.[1] In contrast to , is heavily dependent on the properties of the chosen platform, such as for instance the structure of the cache hierarchy.[1]
Arithmetic intensity
The arithmetic intensity , also referred to as operational intensity,[3][7] is the ratio of the work to the memory traffic :[1]and denotes the number of operations per byte of memory traffic. When the work is expressed as FLOPs, the resulting arithmetic intensity will be the ratio of floating point operations to total data movement (FLOPs/byte).
Naive Roofline

The naïve roofline[3] is obtained by applying simple bound and bottleneck analysis.[8] In this formulation of the roofline model, there are only two parameters, the peak performance and the peak bandwidth of the specific architecture, and one variable, the arithmetic intensity. The peak performance, in general expressed as GFLOPS, can be usually derived from benchmarking, while the peak bandwidth, that references to peak DRAM bandwidth to be specific, is instead obtained via architectural manuals.[1][3] The resulting plot, in general with both axes in logarithmic scale, is then derived by the following formula:[1]where is the attainable performance, is the peak performance, is the peak bandwidth and is the arithmetic intensity. The point at which the performance saturates at the peak performance level , that is where the diagonal and horizontal roof meet, is defined as ridge point.[4] The ridge point offers insight on the machine's overall performance, by providing the minimum arithmetic intensity required to be able to achieve peak performance, and by suggesting at a glance the amount of effort required by the programmer to achieve peak performance.[4]
A given kernel or application is then characterized by a point given by its arithmetic intensity (on the x-axis). The attainable performance is then computed by drawing a vertical line that hits the roofline curve. Hence. the kernel or application is said to be memory-bound if . Conversely, if , the computation is said to be compute-bound.[1]
Adding ceilings to the model
The naive roofline provides just an upper bound (the theoretical maximum) to performance. Although it can still give useful insights on the attainable performance, it does not provide a complete picture of what is actually limiting it. If, for instance, the considered kernel or application performs far below the roofline, it might be useful to capture other performance ceilings, other than simple peak bandwidth and performance, to better guide the programmer on which optimization to implement, or even to assess the suitability of the architecture used with respect to the analyzed kernel or application.[3] The added ceilings impose then a limit on the attainable performance that is below the actual roofline, and indicate that the kernel or application cannot break through anyone of these ceilings without first performing the associated optimization.[3][4]
The roofline plot can be expanded upon three different aspects: communication, adding the bandwidth ceilings; computation, adding the so-called in-core ceilings; and locality, adding the locality walls.
-
 An example of a roofline model with added bandwidth ceilings. In this model, the two additional ceilings represent the absence of software prefetching and NUMA organization of memory.
An example of a roofline model with added bandwidth ceilings. In this model, the two additional ceilings represent the absence of software prefetching and NUMA organization of memory. -
 An example roofline model with added in-core ceilings, where the two added ceilings represent the lack of instruction level parallelism and task level parallelism.
An example roofline model with added in-core ceilings, where the two added ceilings represent the lack of instruction level parallelism and task level parallelism. -
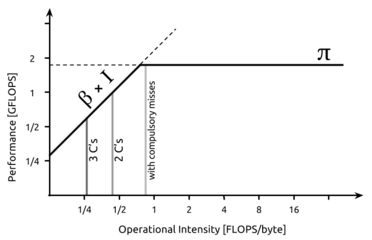 An example roofline model with locality walls. The wall labeled as 3 C's denotes the presence all three types of cache misses: compulsory, capacity and conflict misses. The wall labeled as 2 C's represent the presence of either compulsory and capacity or compulsory and conflict misses. The last wall denotes the presence of just compulsory misses.
An example roofline model with locality walls. The wall labeled as 3 C's denotes the presence all three types of cache misses: compulsory, capacity and conflict misses. The wall labeled as 2 C's represent the presence of either compulsory and capacity or compulsory and conflict misses. The last wall denotes the presence of just compulsory misses.



Bandwidth ceilings
The bandwidth ceilings are bandwidth diagonals placed below the idealized peak bandwidth diagonal. Their existence is due to the lack of some kind of memory related architectural optimization, such as cache coherence, or software optimization, such as poor exposure of concurrency (that in turn limit bandwidth usage).[3][4]
In-core ceilings
The in-core ceilings are roofline-like curve beneath the actual roofline that may be present due to the lack of some form of parallelism. These ceilings effectively limit how high performance can reach. Performance cannot exceed an in-core ceiling until the underlying lack of parallelism is expressed and exploited. The ceilings can be also derived from architectural optimization manuals other than benchmarks.[3][4]
Locality walls
If the ideal assumption that arithmetic intensity is solely a function of the kernel is removed, and the cache topology - and therefore cache misses - is taken into account, the arithmetic intensity clearly becomes dependent on a combination of kernel and architecture. This may result in a degradation in performance depending on the balance between the resultant arithmetic intensity and the ridge point. Unlike "proper" ceilings, the resulting lines on the roofline plot are vertical barriers through which arithmetic intensity cannot pass without optimization. For this reason, they are referenced to as locality walls or arithmetic intensity walls.[3][4]
Extension of the model
Since its introduction,[3][4] the model has been further extended to account for a broader set of metrics and hardware-related bottlenecks. Already available in literature there are extensions that take into account the impact of NUMA organization of memory,[6] of out-of-order execution,[9] of memory latencies,[9][10] and to model at a finer grain the cache hierarchy[5][9] in order to better understand what is actually limiting performance and drive the optimization process.
Also, the model has been extended to better suit specific architectures and the related characteristics, such as FPGAs.[11]
See also
References
- ↑ 1.0 1.1 1.2 1.3 1.4 1.5 1.6 1.7 Ofenbeck, G.; Steinmann, R.; Caparros, V.; Spampinato, D. G.; Püschel, M. (2014-03-01). "Applying the roofline model". 2014 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS). pp. 76–85. doi:10.1109/ISPASS.2014.6844463. ISBN 978-1-4799-3606-9.
- ↑ David A.Patterson, John L. Hennessy. Computer Organisation and Design. p. 543.
- ↑ 3.00 3.01 3.02 3.03 3.04 3.05 3.06 3.07 3.08 3.09 Williams, Samuel W. (2008). Auto-tuning Performance on Multicore Computers (Ph.D.). University of California at Berkeley.
- ↑ 4.0 4.1 4.2 4.3 4.4 4.5 4.6 4.7 Williams, Samuel; Waterman, Andrew; Patterson, David (2009-04-01). "Roofline: An Insightful Visual Performance Model for Multicore Architectures". Commun. ACM 52 (4): 65–76. doi:10.1145/1498765.1498785. ISSN 0001-0782. https://zenodo.org/record/1236156.
- ↑ 5.0 5.1 Ilic, A.; Pratas, F.; Sousa, L. (2014-01-01). "Cache-aware Roofline model: Upgrading the loft". IEEE Computer Architecture Letters 13 (1): 21–24. doi:10.1109/L-CA.2013.6. ISSN 1556-6056.
- ↑ 6.0 6.1 Lorenzo, Oscar G.; Pena, Tomás F.; Cabaleiro, José C.; Pichel, Juan C.; Rivera, Francisco F. (2014-03-31). "Using an extended Roofline Model to understand data and thread affinities on NUMA systems" (in en). Annals of Multicore and GPU Programming 1 (1): 56–67. ISSN 2341-3158. http://revistaseug.ugr.es/index.php/amgp/article/view/1992.
- ↑ "Roofline Performance Model". Lawrence Berkeley National Laboratory. https://crd.lbl.gov/departments/computer-science/PAR/research/roofline/.
- ↑ Kourtis, Kornilios; Goumas, Georgios; Koziris, Nectarios (2008-01-01). "Optimizing sparse matrix-vector multiplication using index and value compression". Proceedings of the 5th conference on Computing frontiers. CF '08. New York, NY, USA: ACM. pp. 87–96. doi:10.1145/1366230.1366244. ISBN 9781605580777.
- ↑ 9.0 9.1 9.2 Cabezas, V. C.; Püschel, M. (2014-10-01). "Extending the roofline model: Bottleneck analysis with microarchitectural constraints". 2014 IEEE International Symposium on Workload Characterization (IISWC). pp. 222–231. doi:10.1109/IISWC.2014.6983061. ISBN 978-1-4799-6454-3.
- ↑ Lorenzo, O. G.; Pena, T. F.; Cabaleiro, J. C.; Pichel, J. C.; Rivera, F. F. (2014-03-26). "3DyRM: a dynamic roofline model including memory latency information" (in en). The Journal of Supercomputing 70 (2): 696–708. doi:10.1007/s11227-014-1163-4. ISSN 0920-8542.
- ↑ da Silva, Bruno; Braeken, An; D'Hollander, Erik H.; Touhafi, Abdellah (2013-01-01). "Performance Modeling for FPGAs: Extending the Roofline Model with High-level Synthesis Tools". International Journal of Reconfigurable Computing 2013: 1–10. doi:10.1155/2013/428078. ISSN 1687-7195.
External links
- The Roofline Model: A Pedagogical Tool for Auto-tuning Kernels on Multicore Architectures
- Applying the Roofline model
- Extending the Roofline Model: Bottleneck Analysis with Microarchitectural Constraints
- Roofline Model Toolkit
- Roofline Model Toolkit: A Practical Tool for Architectural and Program Analysis - publication related to the tool.
- Perfplot
- Extended Roofline Model
- Intel Advisor - Roofline model automation
- Youtube Video on how to use Intel Advisor Roofline
 |  |
