Biology:Metabolic network modelling


Metabolic network modelling, also known as metabolic network reconstruction or metabolic pathway analysis, allows for an in-depth insight into the molecular mechanisms of a particular organism. In particular, these models correlate the genome with molecular physiology.[1] A reconstruction breaks down metabolic pathways (such as glycolysis and the citric acid cycle) into their respective reactions and enzymes, and analyzes them within the perspective of the entire network. In simplified terms, a reconstruction collects all of the relevant metabolic information of an organism and compiles it in a mathematical model. Validation and analysis of reconstructions can allow identification of key features of metabolism such as growth yield, resource distribution, network robustness, and gene essentiality. This knowledge can then be applied to create novel biotechnology.
In general, the process to build a reconstruction is as follows:
- Draft a reconstruction
- Refine the model
- Convert model into a mathematical/computational representation
- Evaluate and debug model through experimentation
The related method of flux balance analysis seeks to mathematically simulate metabolism in genome-scale reconstructions of metabolic networks.
Genome-scale metabolic reconstruction
A metabolic reconstruction provides a highly mathematical, structured platform on which to understand the systems biology of metabolic pathways within an organism.[2] The integration of biochemical metabolic pathways with rapidly available, annotated genome sequences has developed what are called genome-scale metabolic models. Simply put, these models correlate metabolic genes with metabolic pathways. In general, the more information about physiology, biochemistry and genetics is available for the target organism, the better the predictive capacity of the reconstructed models. Mechanically speaking, the process of reconstructing prokaryotic and eukaryotic metabolic networks is essentially the same. Having said this, eukaryote reconstructions are typically more challenging because of the size of genomes, coverage of knowledge, and the multitude of cellular compartments.[2] The first genome-scale metabolic model was generated in 1995 for Haemophilus influenzae.[3] The first multicellular organism, C. elegans, was reconstructed in 1998.[4] Since then, many reconstructions have been formed. For a list of reconstructions that have been converted into a model and experimentally validated, see http://sbrg.ucsd.edu/InSilicoOrganisms/OtherOrganisms.
| Organism | Genes in Genome | Genes in Model | Reactions | Metabolites | Date of reconstruction | Reference |
|---|---|---|---|---|---|---|
| Haemophilus influenzae | 1,775 | 296 | 488 | 343 | June 1999 | [3] |
| Escherichia coli | 4,405 | 660 | 627 | 438 | May 2000 | [5] |
| Saccharomyces cerevisiae | 6,183 | 708 | 1,175 | 584 | February 2003 | [6] |
| Mus musculus | 28,287 | 473 | 1220 | 872 | January 2005 | [7] |
| Homo sapiens | 21,090[8] | 3,623 | 3,673 | -- | January 2007 | [9] |
| Mycobacterium tuberculosis | 4,402 | 661 | 939 | 828 | June 2007 | [10] |
| Bacillus subtilis | 4,114 | 844 | 1,020 | 988 | September 2007 | [11] |
| Synechocystis sp. PCC6803 | 3,221 | 633 | 831 | 704 | October 2008 | [12] |
| Salmonella typhimurium | 4,489 | 1,083 | 1,087 | 774 | April 2009 | [13] |
| Arabidopsis thaliana | 27,379 | 1,419 | 1,567 | 1,748 | February 2010 | [14] |
Drafting a reconstruction
Resources
Because the timescale for the development of reconstructions is so recent, most reconstructions have been built manually. However, now, there are quite a few resources that allow for the semi-automatic assembly of these reconstructions that are utilized due to the time and effort necessary for a reconstruction. An initial fast reconstruction can be developed automatically using resources like PathoLogic or ERGO in combination with encyclopedias like MetaCyc, and then manually updated by using resources like PathwayTools. These semi-automatic methods allow for a fast draft to be created while allowing the fine tune adjustments required once new experimental data is found. It is only in this manner that the field of metabolic reconstructions will keep up with the ever-increasing numbers of annotated genomes.
Databases
- Kyoto Encyclopedia of Genes and Genomes (KEGG): a bioinformatics database containing information on genes, proteins, reactions, and pathways. The 'KEGG Organisms' section, which is divided into eukaryotes and prokaryotes, encompasses many organisms for which gene and DNA information can be searched by typing in the enzyme of choice.
- BioCyc, EcoCyc, and MetaCyc: BioCyc Is a collection of 3,000 pathway/genome databases (as of Oct 2013), with each database dedicated to one organism. For example, EcoCyc is a highly detailed bioinformatics database on the genome and metabolic reconstruction of Escherichia coli, including thorough descriptions of E. coli signaling pathways and regulatory network. The EcoCyc database can serve as a paradigm and model for any reconstruction. Additionally, MetaCyc, an encyclopedia of experimentally defined metabolic pathways and enzymes, contains 2,100 metabolic pathways and 11,400 metabolic reactions (Oct 2013).
- ENZYME: An enzyme nomenclature database (part of the ExPASy proteonomics server of the Swiss Institute of Bioinformatics). After searching for a particular enzyme on the database, this resource gives you the reaction that is catalyzed. ENZYME has direct links to other gene/enzyme/literature databases such as KEGG, BRENDA, and PUBMED.
- BRENDA: A comprehensive enzyme database that allows for an enzyme to be searched by name, EC number, or organism.
- BiGG: A knowledge base of biochemically, genetically, and genomically structured genome-scale metabolic network reconstructions.[15]
- metaTIGER: Is a collection of metabolic profiles and phylogenomic information on a taxonomically diverse range of eukaryotes which provides novel facilities for viewing and comparing the metabolic profiles between organisms.
| Database | Scope | ||||
|---|---|---|---|---|---|
| Enzymes | Genes | Reactions | Pathways | Metabolites | |
| KEGG | X | X | X | X | X |
| BioCyc | X | X | X | X | X |
| MetaCyc | X | X | X | X | |
| ENZYME | X | X | X | ||
| BRENDA | X | X | X | ||
| BiGG | X | X | X | ||
Tools for metabolic modeling
- Pathway Tools: A bioinformatics software package that assists in the construction of pathway/genome databases such as EcoCyc.[16] Developed by Peter Karp and associates at the SRI International Bioinformatics Research Group, Pathway Tools has several components. Its PathoLogic module takes an annotated genome for an organism and infers probable metabolic reactions and pathways to produce a new pathway/genome database. Its MetaFlux component can generate a quantitative metabolic model from that pathway/genome database using flux-balance analysis. Its Navigator component provides extensive query and visualization tools, such as visualization of metabolites, pathways, and the complete metabolic network.
- ERGO: A subscription-based service developed by Integrated Genomics. It integrates data from every level including genomic, biochemical data, literature, and high-throughput analysis into a comprehensive user friendly network of metabolic and nonmetabolic pathways.
- KEGGtranslator:[17][18] an easy-to-use stand-alone application that can visualize and convert KEGG files (KGML formatted XML-files) into multiple output formats. Unlike other translators, KEGGtranslator supports a plethora of output formats, is able to augment the information in translated documents (e.g., MIRIAM annotations) beyond the scope of the KGML document, and amends missing components to fragmentary reactions within the pathway to allow simulations on those. KEGGtranslator converts these files to SBML, BioPAX, SIF, SBGN, SBML with qualitative modeling extension,[19] GML, GraphML, JPG, GIF, LaTeX, etc.
- ModelSEED: An online resource for the analysis, comparison, reconstruction, and curation of genome-scale metabolic models.[20] Users can submit genome sequences to the RAST annotation system, and the resulting annotation can be automatically piped into the ModelSEED to produce a draft metabolic model. The ModelSEED automatically constructs a network of metabolic reactions, gene-protein-reaction associations for each reaction, and a biomass composition reaction for each genome to produce a model of microbial metabolism that can be simulated using Flux Balance Analysis.
- MetaMerge: algorithm for semi-automatically reconciling a pair of existing metabolic network reconstructions into a single metabolic network model.[21]
- CoReCo:[22][23] algorithm for automatic reconstruction of metabolic models of related species. The first version of the software used KEGG as reaction database to link with the EC number predictions from CoReCo. Its automatic gap filling using atom map of all the reactions produce functional models ready for simulation.
Tools for literature
- PUBMED: This is an online library developed by the National Center for Biotechnology Information, which contains a massive collection of medical journals. Using the link provided by ENZYME, the search can be directed towards the organism of interest, thus recovering literature on the enzyme and its use inside of the organism.
Methodology to draft a reconstruction
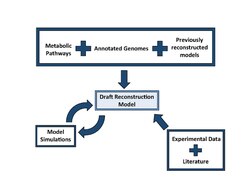
A reconstruction is built by compiling data from the resources above. Database tools such as KEGG and BioCyc can be used in conjunction with each other to find all the metabolic genes in the organism of interest. These genes will be compared to closely related organisms that have already developed reconstructions to find homologous genes and reactions. These homologous genes and reactions are carried over from the known reconstructions to form the draft reconstruction of the organism of interest. Tools such as ERGO, Pathway Tools and Model SEED can compile data into pathways to form a network of metabolic and non-metabolic pathways. These networks are then verified and refined before being made into a mathematical simulation.[2]
The predictive aspect of a metabolic reconstruction hinges on the ability to predict the biochemical reaction catalyzed by a protein using that protein's amino acid sequence as an input, and to infer the structure of a metabolic network based on the predicted set of reactions. A network of enzymes and metabolites is drafted to relate sequences and function. When an uncharacterized protein is found in the genome, its amino acid sequence is first compared to those of previously characterized proteins to search for homology. When a homologous protein is found, the proteins are considered to have a common ancestor and their functions are inferred as being similar. However, the quality of a reconstruction model is dependent on its ability to accurately infer phenotype directly from sequence, so this rough estimation of protein function will not be sufficient. A number of algorithms and bioinformatics resources have been developed for refinement of sequence homology-based assignments of protein functions:
- InParanoid: Identifies eukaryotic orthologs by looking only at in-paralogs.
- CDD: Resource for the annotation of functional units in proteins. Its collection of domain models utilizes 3D structure to provide insights into sequence/structure/function relationships.
- InterPro: Provides functional analysis of proteins by classifying them into families and predicting domains and important sites.
- STRING: Database of known and predicted protein interactions.
Once proteins have been established, more information about the enzyme structure, reactions catalyzed, substrates and products, mechanisms, and more can be acquired from databases such as KEGG, MetaCyc and NC-IUBMB. Accurate metabolic reconstructions require additional information about the reversibility and preferred physiological direction of an enzyme-catalyzed reaction which can come from databases such as BRENDA or MetaCyc database.[24]
Model refinement
An initial metabolic reconstruction of a genome is typically far from perfect due to the high variability and diversity of microorganisms. Often, metabolic pathway databases such as KEGG and MetaCyc will have "holes", meaning that there is a conversion from a substrate to a product (i.e., an enzymatic activity) for which there is no known protein in the genome that encodes the enzyme that facilitates the catalysis. What can also happen in semi-automatically drafted reconstructions is that some pathways are falsely predicted and don't actually occur in the predicted manner.[24] Because of this, a systematic verification is made in order to make sure no inconsistencies are present and that all the entries listed are correct and accurate.[1] Furthermore, previous literature can be researched in order to support any information obtained from one of the many metabolic reaction and genome databases. This provides an added level of assurance for the reconstruction that the enzyme and the reaction it catalyzes do actually occur in the organism.
Enzyme promiscuity and spontaneous chemical reactions can damage metabolites. This metabolite damage, and its repair or pre-emption, create energy costs that need to be incorporated into models. It is likely that many genes of unknown function encode proteins that repair or pre-empt metabolite damage, but most genome-scale metabolic reconstructions only include a fraction of all genes.[25][26]
Any new reaction not present in the databases needs to be added to the reconstruction. This is an iterative process that cycles between the experimental phase and the coding phase. As new information is found about the target organism, the model will be adjusted to predict the metabolic and phenotypical output of the cell. The presence or absence of certain reactions of the metabolism will affect the amount of reactants/products that are present for other reactions within the particular pathway. This is because products in one reaction go on to become the reactants for another reaction, i.e. products of one reaction can combine with other proteins or compounds to form new proteins/compounds in the presence of different enzymes or catalysts.[1]
Francke et al. [1] provide an excellent example as to why the verification step of the project needs to be performed in significant detail. During a metabolic network reconstruction of Lactobacillus plantarum, the model showed that succinyl-CoA was one of the reactants for a reaction that was a part of the biosynthesis of methionine. However, an understanding of the physiology of the organism would have revealed that due to an incomplete tricarboxylic acid pathway, Lactobacillus plantarum does not actually produce succinyl-CoA, and the correct reactant for that part of the reaction was acetyl-CoA.
Therefore, systematic verification of the initial reconstruction will bring to light several inconsistencies that can adversely affect the final interpretation of the reconstruction, which is to accurately comprehend the molecular mechanisms of the organism. Furthermore, the simulation step also ensures that all the reactions present in the reconstruction are properly balanced. To sum up, a reconstruction that is fully accurate can lead to greater insight about understanding the functioning of the organism of interest.[1]
Metabolic stoichiometric analysis
A metabolic network can be broken down into a stoichiometric matrix where the rows represent the compounds of the reactions, while the columns of the matrix correspond to the reactions themselves. Stoichiometry is a quantitative relationship between substrates of a chemical reaction. In order to deduce what the metabolic network suggests, recent research has centered on a few approaches, such as extreme pathways, elementary mode analysis,[27] flux balance analysis, and a number of other constraint-based modeling methods.[28][29]
Extreme pathways
Price, Reed, and Papin,[30] from the Palsson lab, use a method of singular value decomposition (SVD) of extreme pathways in order to understand regulation of a human red blood cell metabolism. Extreme pathways are convex basis vectors that consist of steady state functions of a metabolic network.[31] For any particular metabolic network, there is always a unique set of extreme pathways available.[27] Furthermore, Price, Reed, and Papin,[30] define a constraint-based approach, where through the help of constraints like mass balance and maximum reaction rates, it is possible to develop a 'solution space' where all the feasible options fall within. Then, using a kinetic model approach, a single solution that falls within the extreme pathway solution space can be determined.[30] Therefore, in their study, Price, Reed, and Papin,[30] use both constraint and kinetic approaches to understand the human red blood cell metabolism. In conclusion, using extreme pathways, the regulatory mechanisms of a metabolic network can be studied in further detail.
Elementary mode analysis
Elementary mode analysis closely matches the approach used by extreme pathways. Similar to extreme pathways, there is always a unique set of elementary modes available for a particular metabolic network.[27] These are the smallest sub-networks that allow a metabolic reconstruction network to function in steady state.[32][33][34] According to Stelling (2002),[33] elementary modes can be used to understand cellular objectives for the overall metabolic network. Furthermore, elementary mode analysis takes into account stoichiometrics and thermodynamics when evaluating whether a particular metabolic route or network is feasible and likely for a set of proteins/enzymes.[32]
Minimal metabolic behaviors (MMBs)
In 2009, Larhlimi and Bockmayr presented a new approach called "minimal metabolic behaviors" for the analysis of metabolic networks.[35] Like elementary modes or extreme pathways, these are uniquely determined by the network, and yield a complete description of the flux cone. However, the new description is much more compact. In contrast with elementary modes and extreme pathways, which use an inner description based on generating vectors of the flux cone, MMBs are using an outer description of the flux cone. This approach is based on sets of non-negativity constraints. These can be identified with irreversible reactions, and thus have a direct biochemical interpretation. One can characterize a metabolic network by MMBs and the reversible metabolic space.
Flux balance analysis
A different technique to simulate the metabolic network is to perform flux balance analysis. This method uses linear programming, but in contrast to elementary mode analysis and extreme pathways, only a single solution results in the end. Linear programming is usually used to obtain the maximum potential of the objective function that you are looking at, and therefore, when using flux balance analysis, a single solution is found to the optimization problem.[33] In a flux balance analysis approach, exchange fluxes are assigned to those metabolites that enter or leave the particular network only. Those metabolites that are consumed within the network are not assigned any exchange flux value. Also, the exchange fluxes along with the enzymes can have constraints ranging from a negative to positive value (ex: -10 to 10).
Furthermore, this particular approach can accurately define if the reaction stoichiometry is in line with predictions by providing fluxes for the balanced reactions. Also, flux balance analysis can highlight the most effective and efficient pathway through the network in order to achieve a particular objective function. In addition, gene knockout studies can be performed using flux balance analysis. The enzyme that correlates to the gene that needs to be removed is given a constraint value of 0. Then, the reaction that the particular enzyme catalyzes is completely removed from the analysis.
Dynamic simulation and parameter estimation
In order to perform a dynamic simulation with such a network it is necessary to construct an ordinary differential equation system that describes the rates of change in each metabolite's concentration or amount. To this end, a rate law, i.e., a kinetic equation that determines the rate of reaction based on the concentrations of all reactants is required for each reaction. Software packages that include numerical integrators, such as COPASI or SBMLsimulator, are then able to simulate the system dynamics given an initial condition. Often these rate laws contain kinetic parameters with uncertain values. In many cases it is desired to estimate these parameter values with respect to given time-series data of metabolite concentrations. The system is then supposed to reproduce the given data. For this purpose the distance between the given data set and the result of the simulation, i.e., the numerically or in few cases analytically obtained solution of the differential equation system is computed. The values of the parameters are then estimated to minimize this distance.[36] One step further, it may be desired to estimate the mathematical structure of the differential equation system because the real rate laws are not known for the reactions within the system under study. To this end, the program SBMLsqueezer allows automatic creation of appropriate rate laws for all reactions with the network. [37]
Synthetic accessibility
Synthetic accessibility is a simple approach to network simulation whose goal is to predict which metabolic gene knockouts are lethal. The synthetic accessibility approach uses the topology of the metabolic network to calculate the sum of the minimum number of steps needed to traverse the metabolic network graph from the inputs, those metabolites available to the organism from the environment, to the outputs, metabolites needed by the organism to survive. To simulate a gene knockout, the reactions enabled by the gene are removed from the network and the synthetic accessibility metric is recalculated. An increase in the total number of steps is predicted to cause lethality. Wunderlich and Mirny showed this simple, parameter-free approach predicted knockout lethality in E. coli and S. cerevisiae as well as elementary mode analysis and flux balance analysis in a variety of media.[38]
Applications of a reconstruction
- Several inconsistencies exist between gene, enzyme, reaction databases, and published literature sources regarding the metabolic information of an organism. A reconstruction is a systematic verification and compilation of data from various sources that takes into account all of the discrepancies.
- The combination of relevant metabolic and genomic information of an organism.
- Metabolic comparisons can be performed between various organisms of the same species as well as between different organisms.
- Analysis of synthetic lethality[39]
- Predict adaptive evolution outcomes[40]
- Use in metabolic engineering for high value outputs
Reconstructions and their corresponding models allow the formulation of hypotheses about the presence of certain enzymatic activities and the production of metabolites that can be experimentally tested, complementing the primarily discovery-based approach of traditional microbial biochemistry with hypothesis-driven research.[41] The results these experiments can uncover novel pathways and metabolic activities and decipher between discrepancies in previous experimental data. Information about the chemical reactions of metabolism and the genetic background of various metabolic properties (sequence to structure to function) can be utilized by genetic engineers to modify organisms to produce high value outputs whether those products be medically relevant like pharmaceuticals; high value chemical intermediates such as terpenoids and isoprenoids; or biotechnological outputs like biofuels,[42] or polyhydroxybutyrates also known as bioplastics.[43]
Metabolic network reconstructions and models are used to understand how an organism or parasite functions inside of the host cell. For example, if the parasite serves to compromise the immune system by lysing macrophages, then the goal of metabolic reconstruction/simulation would be to determine the metabolites that are essential to the organism's proliferation inside of macrophages. If the proliferation cycle is inhibited, then the parasite would not continue to evade the host's immune system. A reconstruction model serves as a first step to deciphering the complicated mechanisms surrounding disease. These models can also look at the minimal genes necessary for a cell to maintain virulence. The next step would be to use the predictions and postulates generated from a reconstruction model and apply it to discover novel biological functions such as drug-engineering and drug delivery techniques.
See also
- Cellular model
- Computational systems biology
- Computer simulation
- Flux balance analysis
- Fluxomics
- Metabolic control analysis
- Metabolic flux analysis
- Metabolic network
- Metabolic pathway
- Biochemical systems equation
- Metagenomics
References
- ↑ 1.0 1.1 1.2 1.3 1.4 "Reconstructing the metabolic network of a bacterium from its genome". Trends in Microbiology 13 (11): 550–558. November 2005. doi:10.1016/j.tim.2005.09.001. PMID 16169729.
- ↑ 2.0 2.1 2.2 "A protocol for generating a high-quality genome-scale metabolic reconstruction". Nature Protocols 5 (1): 93–121. January 2010. doi:10.1038/nprot.2009.203. PMID 20057383.
- ↑ 3.0 3.1 "Whole-genome random sequencing and assembly of Haemophilus influenzae Rd". Science 269 (5223): 496–512. July 1995. doi:10.1126/science.7542800. PMID 7542800. Bibcode: 1995Sci...269..496F.
- ↑ "Genome sequence of the nematode C. elegans: a platform for investigating biology". Science 282 (5396): 2012–2018. December 1998. doi:10.1126/science.282.5396.2012. PMID 9851916. Bibcode: 1998Sci...282.2012..
- ↑ "The Escherichia coli MG1655 in silico metabolic genotype: its definition, characteristics, and capabilities". Proceedings of the National Academy of Sciences of the United States of America 97 (10): 5528–5533. May 2000. doi:10.1073/pnas.97.10.5528. PMID 10805808. Bibcode: 2000PNAS...97.5528E.
- ↑ "Genome-scale reconstruction of the Saccharomyces cerevisiae metabolic network". Genome Research 13 (2): 244–253. February 2003. doi:10.1101/gr.234503. PMID 12566402.
- ↑ "Modeling hybridoma cell metabolism using a generic genome-scale metabolic model of Mus musculus". Biotechnology Progress 21 (1): 112–121. January 2005. doi:10.1021/bp0498138. PMID 15903248.
- ↑ "Computational prediction of human metabolic pathways from the complete human genome". Genome Biology 6 (1): R2. June 2004. doi:10.1186/gb-2004-6-1-r2. PMID 15642094.
- ↑ "Global reconstruction of the human metabolic network based on genomic and bibliomic data". Proceedings of the National Academy of Sciences of the United States of America 104 (6): 1777–1782. February 2007. doi:10.1073/pnas.0610772104. PMID 17267599. Bibcode: 2007PNAS..104.1777D.
- ↑ "Investigating the metabolic capabilities of Mycobacterium tuberculosis H37Rv using the in silico strain iNJ661 and proposing alternative drug targets". BMC Systems Biology 1: 26. June 2007. doi:10.1186/1752-0509-1-26. PMID 17555602.
- ↑ "Genome-scale reconstruction of metabolic network in Bacillus subtilis based on high-throughput phenotyping and gene essentiality data". The Journal of Biological Chemistry 282 (39): 28791–28799. September 2007. doi:10.1074/jbc.M703759200. PMID 17573341.
- ↑ "Genome-scale modeling of Synechocystis sp. PCC 6803 and prediction of pathway insertion". Journal of Chemical Technology and Biotechnology 84 (4): 473–483. October 2008. doi:10.1002/jctb.2065.
- ↑ "Constraint-based analysis of metabolic capacity of Salmonella typhimurium during host-pathogen interaction". BMC Systems Biology 3: 38. April 2009. doi:10.1186/1752-0509-3-38. PMID 19356237.
- ↑ "AraGEM, a genome-scale reconstruction of the primary metabolic network in Arabidopsis". Plant Physiology 152 (2): 579–589. February 2010. doi:10.1104/pp.109.148817. PMID 20044452.
- ↑ "BiGG Models 2020: multi-strain genome-scale models and expansion across the phylogenetic tree". Nucleic Acids Research 48 (D1): D402–D406. January 2020. doi:10.1093/nar/gkz1054. PMID 31696234.
- ↑ "Pathway Tools version 13.0: integrated software for pathway/genome informatics and systems biology". Briefings in Bioinformatics 11 (1): 40–79. January 2010. doi:10.1093/bib/bbp043. PMID 19955237.
- ↑ "Precise generation of systems biology models from KEGG pathways". BMC Systems Biology 7 (1): 15. February 2013. doi:10.1186/1752-0509-7-15. PMID 23433509.
- ↑ "KEGGtranslator: visualizing and converting the KEGG PATHWAY database to various formats". Bioinformatics 27 (16): 2314–2315. August 2011. doi:10.1093/bioinformatics/btr377. PMID 21700675.
- ↑ "SBML qualitative models: a model representation format and infrastructure to foster interactions between qualitative modelling formalisms and tools". BMC Systems Biology 7 (1): 135. December 2013. doi:10.1186/1752-0509-7-135. PMID 24321545. Bibcode: 2013arXiv1309.1910C.
- ↑ "High-throughput generation, optimization and analysis of genome-scale metabolic models". Nature Biotechnology 28 (9): 977–982. September 2010. doi:10.1038/nbt.1672. PMID 20802497.
- ↑ "MetaMerge: scaling up genome-scale metabolic reconstructions with application to Mycobacterium tuberculosis". Genome Biology 13 (1): r6. January 2012. doi:10.1186/gb-2012-13-1-r6. PMID 22292986.
- ↑ "Comparative genome-scale reconstruction of gapless metabolic networks for present and ancestral species". PLOS Computational Biology 10 (2). February 2014. doi:10.1371/journal.pcbi.1003465. PMID 24516375. Bibcode: 2014PLSCB..10E3465P.
- ↑ "Whole-genome metabolic model of Trichoderma reesei built by comparative reconstruction". Biotechnology for Biofuels 9: 252. November 2016. doi:10.1186/s13068-016-0665-0. PMID 27895706.
- ↑ 24.0 24.1 "Metabolic Reconstruction" (3rd ed.). 2009. 607–621. doi:10.1016/B978-012373944-5.00010-9. ISBN 978-0-12-373944-5.
- ↑ "Metabolite damage and its repair or pre-emption". Nature Chemical Biology 9 (2): 72–80. February 2013. doi:10.1038/nchembio.1141. PMID 23334546.
- ↑ "Metabolite Damage and Metabolite Damage Control in Plants". Annual Review of Plant Biology 67: 131–152. April 2016. doi:10.1146/annurev-arplant-043015-111648. PMID 26667673.
- ↑ 27.0 27.1 27.2 "Comparison of network-based pathway analysis methods". Trends in Biotechnology 22 (8): 400–405. August 2004. doi:10.1016/j.tibtech.2004.06.010. PMID 15283984.
- ↑ "Constraining the metabolic genotype-phenotype relationship using a phylogeny of in silico methods". Nature Reviews. Microbiology 10 (4): 291–305. February 2012. doi:10.1038/nrmicro2737. PMID 22367118.
- ↑ CoBRA Methods - Constraint-based analysis
- ↑ 30.0 30.1 30.2 30.3 "Network-based analysis of metabolic regulation in the human red blood cell". Journal of Theoretical Biology 225 (2): 185–194. November 2003. doi:10.1016/s0022-5193(03)00237-6. PMID 14575652. Bibcode: 2003JThBi.225..185P.
- ↑ "Extreme pathway lengths and reaction participation in genome-scale metabolic networks". Genome Research 12 (12): 1889–1900. December 2002. doi:10.1101/gr.327702. PMID 12466293.
- ↑ 32.0 32.1 "A general definition of metabolic pathways useful for systematic organization and analysis of complex metabolic networks". Nature Biotechnology 18 (3): 326–332. March 2000. doi:10.1038/73786. PMID 10700151.
- ↑ 33.0 33.1 33.2 "Metabolic network structure determines key aspects of functionality and regulation". Nature 420 (6912): 190–193. November 2002. doi:10.1038/nature01166. PMID 12432396. Bibcode: 2002Natur.420..190S.
- ↑ "gEFM: An Algorithm for Computing Elementary Flux Modes Using Graph Traversal". IEEE/ACM Transactions on Computational Biology and Bioinformatics 13 (1): 122–134. 2015. doi:10.1109/TCBB.2015.2430344. PMID 26886737.
- ↑ "A new constraint-based description of the steady-state flux cone of metabolic networks". Discrete Applied Mathematics 157 (10): 2257–2266. 2009. doi:10.1016/j.dam.2008.06.039.
- ↑ "Modeling metabolic networks in C. glutamicum: a comparison of rate laws in combination with various parameter optimization strategies". BMC Systems Biology 3 (5): 5. January 2009. doi:10.1186/1752-0509-3-5. PMID 19144170.
- ↑ "SBMLsqueezer: a CellDesigner plug-in to generate kinetic rate equations for biochemical networks". BMC Systems Biology 2 (1): 39. April 2008. doi:10.1186/1752-0509-2-39. PMID 18447902.
- ↑ "Using the topology of metabolic networks to predict viability of mutant strains". Biophysical Journal 91 (6): 2304–2311. September 2006. doi:10.1529/biophysj.105.080572. PMID 16782788. Bibcode: 2006BpJ....91.2304W.
- ↑ "The genetic landscape of a cell". Science 327 (5964): 425–431. January 2010. doi:10.1126/science.1180823. PMID 20093466. Bibcode: 2010Sci...327..425C.
- ↑ "Description and interpretation of adaptive evolution of Escherichia coli K-12 MG1655 by using a genome-scale in silico metabolic model". Journal of Bacteriology 185 (21): 6400–6408. November 2003. doi:10.1128/JB.185.21.6400-6408.2003. PMID 14563875.
- ↑ "Metabolic Reconstruction". Encyclopedia of Microbiology. 2009. 607–621. doi:10.1016/B978-012373944-5.00010-9. ISBN 978-0-12-373944-5.
- ↑ "RetSynth: determining all optimal and sub-optimal synthetic pathways that facilitate synthesis of target compounds in chassis organisms". BMC Bioinformatics 20 (1): 461. September 2019. doi:10.1186/s12859-019-3025-9. PMID 31500573.
- ↑ "Whole-genome sequencing and genome-scale metabolic modeling of Chromohalobacter canadensis 85B to explore its salt tolerance and biotechnological use". MicrobiologyOpen 11 (5). October 2022. doi:10.1002/mbo3.1328. PMID 36314754.
Further reading
- Overbeek R, Larsen N, Walunas T, D'Souza M, Pusch G, Selkov Jr, Liolios K, Joukov V, Kaznadzey D, Anderson I, Bhattacharyya A, Burd H, Gardner W, Hanke P, Kapatral V, Mikhailova N, Vasieva O, Osterman A, Vonstein V, Fonstein M, Ivanova N, Kyrpides N. (2003) The ERGO genome analysis and discovery system. Nucleic Acids Res. 31(1):164-71
- Whitaker, J.W., Letunic, I., McConkey, G.A. and Westhead, D.R. metaTIGER: a metabolic evolution resource. Nucleic Acids Res. 2009 37: D531-8.
External links
- ERGO
- GeneDB
- KEGG
- PathCase Case Western Reserve University
- BRENDA
- BioCyc and Cyclone - provides an open source Java API to the pathway tool BioCyc to extract Metabolic graphs.
- EcoCyc
- MetaCyc
- SEED
- ModelSEED
- ENZYME
- SBRI Bioinformatics Tools and Software
- TIGR
- Pathway Tools
- metaTIGER
- Stanford Genomic Resources
- Pathway Hunter Tool
- IMG The Integrated Microbial Genomes system, for genome analysis by the DOE-JGI.
- Systems Analysis, Modelling and Prediction Group at the University of Oxford, Biochemical reaction pathway inference techniques.
- efmtool provided by Marco Terzer
- SBMLsqueezer
- Cellnet analyzer from Klamt and von Kamp
- Copasi
- gEFM A graph-based tool for EFM computation
 |  |
