where <math>\beta</math> can be constant (usually set to 1) or trainable and "sigmoid" refers to the [[Logistic function|logistic function]].
where <math>\beta</math> can be constant (usually set to 1) or trainable and "sigmoid" refers to the [[Logistic function|logistic function]].
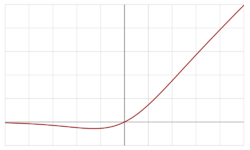
The swish family was designed to smoothly [[Interpolation|interpolate]] between a linear function and the ReLU function.
The swish family was designed to smoothly [[Interpolation|interpolate]] between a linear function and the [[Rectified linear unit]] (ReLU) function.
When considering positive values, Swish is a particular case of doubly parameterized sigmoid shrinkage function defined in <ref>{{Cite book |last1=Atto |first1=Abdourrahmane M. |last2=Pastor |first2=Dominique |last3=Mercier |first3=Gregoire |title=2008 IEEE International Conference on Acoustics, Speech and Signal Processing |chapter=Smooth sigmoid wavelet shrinkage for non-parametric estimation |date=March 2008 |chapter-url=https://ieeexplore.ieee.org/document/4518347 |pages=3265–3268 |doi=10.1109/ICASSP.2008.4518347|isbn=978-1-4244-1483-3 |s2cid=9959057 |url=https://hal.archives-ouvertes.fr/hal-02136546/file/ICASSP_ATTO_2008.pdf }}</ref>{{Pg|location=Eq 3}}. Variants of the swish function include Mish.<ref>{{cite arXiv |eprint=1908.08681 |class=cs.LG |first=Diganta |last=Misra |title=Mish: A Self Regularized Non-Monotonic Neural Activation Function |date=2019}}</ref>
When considering positive values, Swish is a particular case of doubly parameterized sigmoid shrinkage function defined in <ref>{{Cite book |last1=Atto |first1=Abdourrahmane M. |last2=Pastor |first2=Dominique |last3=Mercier |first3=Gregoire |title=2008 IEEE International Conference on Acoustics, Speech and Signal Processing |chapter=Smooth sigmoid wavelet shrinkage for non-parametric estimation |date=March 2008 |chapter-url=https://ieeexplore.ieee.org/document/4518347 |pages=3265–3268 |doi=10.1109/ICASSP.2008.4518347|isbn=978-1-4244-1483-3 |s2cid=9959057 |url=https://hal.archives-ouvertes.fr/hal-02136546/file/ICASSP_ATTO_2008.pdf }}</ref>{{Pg|location=Eq 3}}. Variants of the swish function include Mish.<ref>{{cite arXiv |eprint=1908.08681 |class=cs.LG |first=Diganta |last=Misra |title=Mish: A Self Regularized Non-Monotonic Neural Activation Function |date=2019}}</ref>
Line 14:
Line 14:
For β = 1, the function is the '''Sigmoid Linear Unit''' (SiLU).
For β = 1, the function is the '''Sigmoid Linear Unit''' (SiLU).
For β = 1.702, the function approximates [[Rectified linear unit#Gaussian-error linear unit (GELU)|GeLU]].<ref name="Hendrycks-Gimpel_2016" />
With β → ∞, the function converges to ReLU.
With β → ∞, the function converges to ReLU.
Line 40:
Line 42:
* [[Activation function]]
* [[Activation function]]
* Gating mechanism
* [[Gating mechanism]]
==References==
==References==
{{reflist|refs=
<references>
<ref name="Hendrycks-Gimpel_2016">{{cite arXiv |eprint = 1606.08415 |title = Gaussian Error Linear Units (GELUs) |last1 = Hendrycks |first1 = Dan |last2 = Gimpel |first2 = Kevin |year = 2016 |class = cs.LG}}</ref>
<ref name="Hendrycks-Gimpel_2016">{{cite arXiv |eprint = 1606.08415 |title = Gaussian Error Linear Units (GELUs) |last1 = Hendrycks |first1 = Dan |last2 = Gimpel |first2 = Kevin |year = 2016 |class = cs.LG}}</ref>
<ref name="Elfwing-Uchibe-Doya_2017">{{cite arXiv |first1=Stefan |last1=Elfwing |first2=Eiji |last2=Uchibe |first3=Kenji |last3=Doya |title=Sigmoid-Weighted Linear Units for Neural Network Function Approximation in Reinforcement Learning |date=2017-11-02 |class=cs.LG |eprint=1702.03118v3}}</ref>
<ref name="Elfwing-Uchibe-Doya_2017">{{cite arXiv |first1=Stefan |last1=Elfwing |first2=Eiji |last2=Uchibe |first3=Kenji |last3=Doya |title=Sigmoid-Weighted Linear Units for Neural Network Function Approximation in Reinforcement Learning |date=2017-11-02 |class=cs.LG |eprint=1702.03118v3}}</ref>
<ref name="Sefiks_2018">{{cite web |title=Swish as Neural Networks Activation Function |first=Sefik Ilkin |last=Serengil |series=Machine Learning, Math |date=2018-08-21 |url=https://sefiks.com/2018/08/21/swish-as-neural-networks-activation-function/ |access-date=2020-06-18 |url-status=live |archive-url=https://web.archive.org/web/20200618093348/https://sefiks.com/2018/08/21/swish-as-neural-networks-activation-function/ |archive-date=2020-06-18}}</ref>
<ref name="Sefiks_2018">{{cite web |title=Swish as Neural Networks Activation Function |first=Sefik Ilkin |last=Serengil |series=Machine Learning, Math |date=2018-08-21 |url=https://sefiks.com/2018/08/21/swish-as-neural-networks-activation-function/ |access-date=2020-06-18 |url-status=live |archive-url=https://web.archive.org/web/20200618093348/https://sefiks.com/2018/08/21/swish-as-neural-networks-activation-function/ |archive-date=2020-06-18}}</ref>
}}{{Differentiable computing}}
</references>{{Differentiable computing}}
[[Category:Functions and mappings]]
[[Category:Functions and mappings]]
[[Category:Artificial neural networks]]
[[Category:Artificial neural networks]]
{{Sourceattribution|Swish function}}
{{Sourceattribution|Swish function}}
Latest revision as of 18:10, 14 April 2026
Short description: Mathematical activation function in data analysis
When considering positive values, Swish is a particular case of doubly parameterized sigmoid shrinkage function defined in [2]Template:Pg. Variants of the swish function include Mish.[3]
Thus, the swish family smoothly interpolates between a linear function and the ReLU function.[1]
Since , all instances of swish have the same shape as the default , zoomed by . One usually sets . When is trainable, this constraint can be enforced by , where is trainable.
Derivatives
Because , it suffices to calculate its derivatives for the default case.so is odd.so is even.
History
SiLU was first proposed alongside the GELU in 2016,[4] then again proposed in 2017 as the Sigmoid-weighted Linear Unit (SiL) in reinforcement learning.[5][1] The SiLU/SiL was then again proposed as the SWISH over a year after its initial discovery, originally proposed without the learnable parameter β, so that β implicitly equaled 1. The swish paper was then updated to propose the activation with the learnable parameter β.
↑ 4.04.1Hendrycks, Dan; Gimpel, Kevin (2016). "Gaussian Error Linear Units (GELUs)". arXiv:1606.08415 [cs.LG].
↑Elfwing, Stefan; Uchibe, Eiji; Doya, Kenji (2017-11-02). "Sigmoid-Weighted Linear Units for Neural Network Function Approximation in Reinforcement Learning". arXiv:1702.03118v3 [cs.LG].