Gradient descent
File:Gradient Descent in 2D.webm
| Machine learning and data mining |
|---|
 |
The idea is to take repeated steps in the opposite direction of the gradient (or approximate gradient) of the function at the current point, because this is the direction of steepest descent. Conversely, stepping in the direction of the gradient will lead to a trajectory that maximizes that function; the procedure is then known as gradient ascent. Gradient descent should not be confused with local search algorithms, although both are iterative methods for optimization.
Gradient descent is particularly useful in machine learning and artificial intelligence for minimizing the cost or loss function.[1]
Gradient descent is generally attributed to Augustin-Louis Cauchy, who first suggested it in 1847.[2] Jacques Hadamard independently proposed a similar method in 1907.[3][4] Its convergence properties for non-linear optimization problems were first studied by Haskell Curry in 1944,[5] with the method becoming increasingly well-studied and used in the following decades.[6][7]
A simple extension of gradient descent, stochastic gradient descent, serves as the most basic algorithm used for training most deep networks today.
Description

Gradient descent is based on the observation that if the multi-variable function is defined and differentiable in a neighborhood of a point , then decreases fastest if one goes from in the direction of the negative gradient of at . It follows that, if
for a small enough step size or learning rate , then . In other words, the term is subtracted from because we want to move against the gradient, toward the local minimum. With this observation in mind, one starts with a guess for a local minimum of , and considers the sequence such that
We have a monotonic sequence
so the sequence converges to the desired local minimum. Note that the value of the step size is allowed to change at every iteration.
It is possible to guarantee the convergence to a local minimum under certain assumptions on the function (for example, convex and Lipschitz) and particular choices of . Those include the sequence
as in the Barzilai-Borwein method,[8][9] or a sequence satisfying the Wolfe conditions (which can be found by using line search). When the function is convex, all local minima are also global minima, so in this case gradient descent can converge to the global solution.
This process is illustrated in the adjacent picture. Here, is assumed to be defined on the plane, and that its graph has a bowl shape. The blue curves are the contour lines, that is, the regions on which the value of is constant. A red arrow originating at a point shows the direction of the negative gradient at that point. Note that the (negative) gradient at a point is orthogonal to the contour line going through that point. We see that gradient descent leads us to the bottom of the bowl, that is, to the point where the value of the function is minimal.
An analogy for understanding gradient descent
.jpg)
The basic intuition behind gradient descent can be illustrated by a hypothetical scenario. People are stuck in the mountains and are trying to get down (i.e., trying to find the global minimum). There is heavy fog such that visibility is extremely low. Therefore, the path down the mountain is not visible, so they must use local information to find the minimum. They can use the method of gradient descent, which involves looking at the steepness of the hill at their current position, then proceeding in the direction with the steepest descent (i.e., downhill). If they were trying to find the top of the mountain (i.e., the maximum), then they would proceed in the direction of steepest ascent (i.e., uphill). Using this method, they would eventually find their way down the mountain or possibly get stuck in some hole (i.e., local minimum or saddle point), like a mountain lake. However, assume also that the steepness of the hill is not immediately obvious with simple observation, but rather it requires a sophisticated instrument to measure, which the people happen to have at that moment. It takes quite some time to measure the steepness of the hill with the instrument. Thus, they should minimize their use of the instrument if they want to get down the mountain before sunset. The difficulty then is choosing the frequency at which they should measure the steepness of the hill so as not to go off track.
In this analogy, the people represent the algorithm, and the path taken down the mountain represents the sequence of parameter settings that the algorithm will explore. The steepness of the hill represents the slope of the function at that point. The instrument used to measure steepness is differentiation. The direction they choose to travel in aligns with the gradient of the function at that point. The amount of time they travel before taking another measurement is the step size.
Choosing the step size and descent direction
Since using a step size that is too small would slow convergence, and a too large would lead to overshoot and divergence, finding a good setting of is an important practical problem. Philip Wolfe also advocated using "clever choices of the [descent] direction" in practice.[10] While using a direction that deviates from the steepest descent direction may seem counter-intuitive, the idea is that the smaller slope may be compensated for by being sustained over a much longer distance.
To reason about this mathematically, consider a direction and step size and consider the more general update:
- .
Finding good settings of and requires some thought. First of all, we would like the update direction to point downhill. Mathematically, letting denote the angle between and , this requires that To say more, we need more information about the objective function that we are optimising. Under the fairly weak assumption that is continuously differentiable, we may prove that:[11]
-
()
This inequality implies that the amount by which we can be sure the function is decreased depends on a trade off between the two terms in square brackets. The first term in square brackets measures the angle between the descent direction and the negative gradient. The second term measures how quickly the gradient changes along the descent direction.
In principle inequality (1) could be optimized over and to choose an optimal step size and direction. The problem is that evaluating the second term in square brackets requires evaluating , and extra gradient evaluations are generally expensive and undesirable. Some ways around this problem are:
- Forgo the benefits of a clever descent direction by setting , and use line search to find a suitable step-size , such as one that satisfies the Wolfe conditions. A more economic way of choosing learning rates is backtracking line search, a method that has both good theoretical guarantees and experimental results. Note that one does not need to choose to be the gradient; any direction that has positive inner product with the gradient will result in a reduction of the function value (for a sufficiently small value of ).
- Assuming that is twice-differentiable, use its Hessian to estimate Then choose and by optimising inequality (1).
- Assuming that is Lipschitz, use its Lipschitz constant to bound Then choose and by optimising inequality (1).
- Build a custom model of for . Then choose and by optimising inequality (1).
- Under stronger assumptions on the function such as convexity, more advanced techniques may be possible.
Usually by following one of the recipes above, convergence to a local minimum can be guaranteed. When the function is convex, all local minima are also global minima, so in this case gradient descent can converge to the global solution.
Solution of a linear system

Gradient descent can be used to solve a system of linear equations
reformulated as a quadratic minimization problem. If the system matrix is real symmetric and positive-definite, an objective function is defined as the quadratic function, with minimization of
so that
For a general real matrix , linear least squares define
In traditional linear least squares for real and the Euclidean norm is used, in which case
The line search minimization, finding the locally optimal step size on every iteration, can be performed analytically for quadratic functions, and explicit formulas for the locally optimal are known.[6][13]
For example, for real symmetric and positive-definite matrix , a simple algorithm can be as follows,[6]
To avoid multiplying by twice per iteration, we note that implies , which gives the traditional algorithm,[14]

Convergence path of steepest descent method for A = [[2, 2], [2, 3]]

The method is rarely used for solving linear equations, with the conjugate gradient method being one of the most popular alternatives. The number of gradient descent iterations is commonly proportional to the spectral condition number of the system matrix (the ratio of the maximum to minimum eigenvalues of ), while the convergence of conjugate gradient method is typically determined by a square root of the condition number, i.e., is much faster. Both methods can benefit from preconditioning, where gradient descent may require less assumptions on the preconditioner.[14]
Geometric behavior and residual orthogonality
In steepest descent applied to solving , where is symmetric positive-definite, the residual vectors are orthogonal across iterations:
Because each step is taken in the steepest direction, steepest-descent steps alternate between directions aligned with the extreme axes of the elongated level sets. When is large, this produces a characteristic zig–zag path. The poor conditioning of is the primary cause of the slow convergence, and orthogonality of successive residuals reinforces this alternation.
As shown in the image on the right, steepest descent converges slowly due to the high condition number of , and the orthogonality of residuals forces each new direction to undo the overshoot from the previous step. The result is a path that zigzags toward the solution. This inefficiency is one reason conjugate gradient or preconditioning methods are preferred.[15]
Solution of a non-linear system
Gradient descent can also be used to solve a system of nonlinear equations. Below is an example that shows how to use the gradient descent to solve for three unknown variables, x1, x2, and x3. This example shows one iteration of the gradient descent.
Consider the nonlinear system of equations
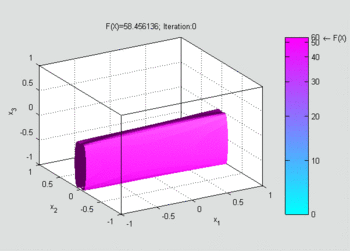
An animation showing the first 83 iterations of gradient descent applied to this example. Surfaces are isosurfaces of at current guess , and arrows show the direction of descent. Due to a small and constant step size, the convergence is slow.

Let us introduce the associated function
where
One might now define the objective function
which we will attempt to minimize. As an initial guess, let us use
We know that
where the Jacobian matrix is given by
We calculate:
Thus
and
Now, a suitable must be found such that
This can be done with any of a variety of line search algorithms. One might also simply guess which gives
Evaluating the objective function at this value, yields
The decrease from to the next step's value of
is a sizable decrease in the objective function. Further steps would reduce its value further until an approximate solution to the system was found.
Comments
Gradient descent works in spaces of any number of dimensions, even in infinite-dimensional ones. In the latter case, the search space is typically a function space, and one calculates the Fréchet derivative of the functional to be minimized to determine the descent direction.[7]
That gradient descent works in any number of dimensions (finite number at least) can be seen as a consequence of the Cauchy–Schwarz inequality, i.e. the magnitude of the inner (dot) product of two vectors of any dimension is maximized when they are colinear. In the case of gradient descent, that would be when the vector of independent variable adjustments is proportional to the gradient vector of partial derivatives.
The gradient descent can take many iterations to compute a local minimum with a required accuracy, if the curvature in different directions is very different for the given function. For such functions, preconditioning, which changes the geometry of the space to shape the function level sets like concentric circles, cures the slow convergence. Constructing and applying preconditioning can be computationally expensive, however.
The gradient descent can be modified via momentums[16] (Nesterov, Polyak,[17] and Frank–Wolfe[18]) and heavy-ball parameters (exponential moving averages[19] and positive-negative momentum[20]). The main examples of such optimizers are Adam, DiffGrad, Yogi, AdaBelief, etc.
Methods based on Newton's method and inversion of the Hessian using conjugate gradient techniques can be better alternatives.[21][22] Generally, such methods converge in fewer iterations, but the cost of each iteration is higher. An example is the BFGS method which consists in calculating on every step a matrix by which the gradient vector is multiplied to go into a "better" direction, combined with a more sophisticated line search algorithm, to find the "best" value of For extremely large problems, where the computer-memory issues dominate, a limited-memory method such as L-BFGS should be used instead of BFGS or the steepest descent.
While it is sometimes possible to substitute gradient descent for a local search algorithm, gradient descent is not in the same family: although it is an iterative method for local optimization, it relies on an objective function's gradient rather than an explicit exploration of a solution space.
Gradient descent can be viewed as applying Euler's method for solving ordinary differential equations to a gradient flow. In turn, this equation may be derived as an optimal controller[23] for the control system with given in feedback form .
Modifications
Gradient descent can converge to a local minimum and slow down in a neighborhood of a saddle point. Even for unconstrained quadratic minimization, gradient descent develops a zig–zag pattern of subsequent iterates as iterations progress, resulting in slow convergence. Multiple modifications of gradient descent have been proposed to address these deficiencies.
Fast gradient methods
Yurii Nesterov has proposed[24] a simple modification that enables faster convergence for convex problems and has been since further generalized. For unconstrained smooth problems, the method is called the fast gradient method (FGM) or the accelerated gradient method (AGM). Specifically, if the differentiable function is convex and is Lipschitz, and it is not assumed that is strongly convex, then the error in the objective value generated at each step by the gradient descent method will be bounded by . Using the Nesterov acceleration technique, the error decreases at .[25][26] It is known that the rate for the decrease of the cost function is optimal for first-order optimization methods. Nevertheless, there is the opportunity to improve the algorithm by reducing the constant factor. The optimized gradient method (OGM)[27] reduces that constant by a factor of two and is an optimal first-order method for large-scale problems.[28]
For constrained or non-smooth problems, Nesterov's FGM is called the fast proximal gradient method (FPGM), an acceleration of the proximal gradient method.
Momentum or heavy ball method
Trying to break the zig-zag pattern of gradient descent, the momentum or heavy ball method uses a momentum term in analogy to a heavy ball sliding on the surface of values of the function being minimized,[6] or to mass movement in Newtonian dynamics through a viscous medium in a conservative force field.[29] Gradient descent with momentum remembers the solution update at each iteration, and determines the next update as a linear combination of the gradient and the previous update. For unconstrained quadratic minimization, a theoretical convergence rate bound of the heavy ball method is asymptotically the same as that for the optimal conjugate gradient method.[6]
This technique is used in stochastic gradient descent and as an extension to the backpropagation algorithms used to train artificial neural networks.[30][31] In the direction of updating, stochastic gradient descent adds a stochastic property. The weights can be used to calculate the derivatives.
Extensions
Gradient descent can be extended to handle constraints by including a projection onto the set of constraints. This method is only feasible when the projection is efficiently computable on a computer. Under suitable assumptions, this method converges. This method is a specific case of the forward–backward algorithm for monotone inclusions (which includes convex programming and variational inequalities).[32]
Gradient descent is a special case of mirror descent using the squared Euclidean distance as the given Bregman divergence.[33]
Theoretical properties
The properties of gradient descent depend on the properties of the objective function and the variant of gradient descent used (for example, if a line search step is used). The assumptions made affect the convergence rate, and other properties, that can be proven for gradient descent.[34] For example, if the objective is assumed to be strongly convex and lipschitz smooth, then gradient descent converges linearly with a fixed step size.[1] Looser assumptions lead to either weaker convergence guarantees or require a more sophisticated step size selection.[34]
Examples
See also
- Backtracking line search
- Conjugate gradient method
- Stochastic gradient descent
- Rprop
- Delta rule
- Wolfe conditions
- Preconditioning
- Broyden–Fletcher–Goldfarb–Shanno algorithm
- Davidon–Fletcher–Powell formula
- Nelder–Mead method
- Gauss–Newton algorithm
- Hill climbing
- Quantum annealing
- CLS (continuous local search)
- Neuroevolution
References
- ↑ 1.0 1.1 Boyd, Stephen; Vandenberghe, Lieven (2004-03-08). Convex Optimization. Cambridge University Press. doi:10.1017/cbo9780511804441. ISBN 978-0-521-83378-3.
- ↑ Lemaréchal, C. (1 January 2012). "Cauchy and the gradient method". in Grötschel, M.. Optimization Stories. Documenta Mathematica Series. 6 (1st ed.). EMS Press. pp. 251–254. doi:10.4171/dms/6/27. ISBN 978-3-936609-58-5. https://www.math.uni-bielefeld.de/documenta/vol-ismp/40_lemarechal-claude.pdf. Retrieved 2020-01-26.
- ↑ Hadamard, Jacques (1908). "Mémoire sur le problème d'analyse relatif à l'équilibre des plaques élastiques encastrées". Mémoires présentés par divers savants éstrangers à l'Académie des Sciences de l'Institut de France 33.
- ↑ Courant, R. (1943). "Variational methods for the solution of problems of equilibrium and vibrations". Bulletin of the American Mathematical Society 49 (1): 1–23. doi:10.1090/S0002-9904-1943-07818-4.
- ↑ Curry, Haskell B. (1944). "The Method of Steepest Descent for Non-linear Minimization Problems". Quart. Appl. Math. 2 (3): 258–261. doi:10.1090/qam/10667.
- ↑ 6.0 6.1 6.2 6.3 6.4 Polyak, Boris (1987) (in en). Introduction to Optimization. https://www.researchgate.net/publication/342978480.
- ↑ 7.0 7.1 Akilov, G. P.; Kantorovich, L. V. (1982). Functional Analysis (2nd ed.). Pergamon Press. ISBN 0-08-023036-9.
- ↑ Barzilai, Jonathan; Borwein, Jonathan M. (1988). "Two-Point Step Size Gradient Methods". IMA Journal of Numerical Analysis 8 (1): 141–148. doi:10.1093/imanum/8.1.141.
- ↑ Fletcher, R. (2005). "On the Barzilai–Borwein Method". in Qi, L.; Teo, K.; Yang, X.. Optimization and Control with Applications. Applied Optimization. 96. Boston: Springer. pp. 235–256. ISBN 0-387-24254-6.
- ↑ Wolfe, Philip (April 1969). "Convergence Conditions for Ascent Methods". SIAM Review 11 (2): 226–235. doi:10.1137/1011036.
- ↑ Bernstein, Jeremy; Vahdat, Arash; Yue, Yisong; Liu, Ming-Yu (2020-06-12). "On the distance between two neural networks and the stability of learning". arXiv:2002.03432 [cs.LG].
- ↑ Haykin, Simon S. Adaptive filter theory. Pearson Education India, 2008. - p. 108-142, 217-242
- ↑ Saad, Yousef (2003). Iterative methods for sparse linear systems (2nd ed.). Philadelphia, Pa.: Society for Industrial and Applied Mathematics. pp. 195. ISBN 978-0-89871-534-7. https://archive.org/details/iterativemethods0000saad/page/195.
- ↑ 14.0 14.1 Bouwmeester, Henricus; Dougherty, Andrew; Knyazev, Andrew V. (2015). "Nonsymmetric Preconditioning for Conjugate Gradient and Steepest Descent Methods". Procedia Computer Science 51: 276–285. doi:10.1016/j.procs.2015.05.241.
- ↑ Holmes, M. (2023). Introduction to Scientific Computing and Data Analysis, 2nd Ed. Springer. ISBN 978-3-031-22429-4.
- ↑ Abdulkadirov, Ruslan; Lyakhov, Pavel; Nagornov, Nikolay (January 2023). "Survey of Optimization Algorithms in Modern Neural Networks" (in en). Mathematics 11 (11): 2466. doi:10.3390/math11112466. ISSN 2227-7390.
- ↑ Diakonikolas, Jelena; Jordan, Michael I. (January 2021). "Generalized Momentum-Based Methods: A Hamiltonian Perspective" (in en). SIAM Journal on Optimization 31 (1): 915–944. doi:10.1137/20M1322716. ISSN 1052-6234. https://epubs.siam.org/doi/10.1137/20M1322716.
- ↑ Meyer, Gerard G. L. (November 1974). "Accelerated Frank–Wolfe Algorithms" (in en). SIAM Journal on Control 12 (4): 655–663. doi:10.1137/0312050. ISSN 0036-1402. http://epubs.siam.org/doi/10.1137/0312050.
- ↑ Kingma, Diederik P.; Ba, Jimmy (2017-01-29), Adam: A Method for Stochastic Optimization
- ↑ Xie, Zeke; Yuan, Li; Zhu, Zhanxing; Sugiyama, Masashi (2021-07-01). "Positive-Negative Momentum: Manipulating Stochastic Gradient Noise to Improve Generalization" (in en). Proceedings of the 38th International Conference on Machine Learning (PMLR): 11448–11458. https://proceedings.mlr.press/v139/xie21h.html.
- ↑ Press, W. H.; Teukolsky, S. A.; Vetterling, W. T.; Flannery, B. P. (1992). Numerical Recipes in C: The Art of Scientific Computing (2nd ed.). New York: Cambridge University Press. ISBN 0-521-43108-5. https://archive.org/details/numericalrecipes00pres_0.
- ↑ Strutz, T. (2016). Data Fitting and Uncertainty: A Practical Introduction to Weighted Least Squares and Beyond (2nd ed.). Springer Vieweg. ISBN 978-3-658-11455-8.
- ↑ Ross, I.M. (July 2019). "An optimal control theory for nonlinear optimization". Journal of Computational and Applied Mathematics 354: 39–51. doi:10.1016/j.cam.2018.12.044.
- ↑ Nesterov, Yurii (2004). Introductory Lectures on Convex Optimization: A Basic Course. Springer. ISBN 1-4020-7553-7.
- ↑ Vandenberghe, Lieven (2019). "Fast Gradient Methods". Lecture notes for EE236C at UCLA. https://www.seas.ucla.edu/~vandenbe/236C/lectures/fgrad.pdf.
- ↑ Walkington, Noel J. (2023). "Nesterov's Method for Convex Optimization" (in en). SIAM Review 65 (2): 539–562. doi:10.1137/21M1390037. ISSN 0036-1445. https://epubs.siam.org/doi/10.1137/21M1390037.
- ↑ Kim, D.; Fessler, J. A. (2016). "Optimized First-order Methods for Smooth Convex Minimization". Mathematical Programming 151 (1–2): 81–107. doi:10.1007/s10107-015-0949-3. PMID 27765996.
- ↑ Drori, Yoel (2017). "The Exact Information-based Complexity of Smooth Convex Minimization". Journal of Complexity 39: 1–16. doi:10.1016/j.jco.2016.11.001.
- ↑ Qian, Ning (January 1999). "On the momentum term in gradient descent learning algorithms". Neural Networks 12 (1): 145–151. doi:10.1016/S0893-6080(98)00116-6. PMID 12662723.
- ↑ "Momentum and Learning Rate Adaptation". Willamette University. http://www.willamette.edu/~gorr/classes/cs449/momrate.html.
- ↑ "The momentum method". https://www.coursera.org/lecture/neural-networks/the-momentum-method-Oya9a. Part of a lecture series for the Coursera online course Neural Networks for Machine Learning .
- ↑ Combettes, P. L.; Pesquet, J.-C. (2011). "Proximal splitting methods in signal processing". in Bauschke, H. H.; Burachik, R. S.; Combettes, P. L. et al.. Fixed-Point Algorithms for Inverse Problems in Science and Engineering. New York: Springer. pp. 185–212. ISBN 978-1-4419-9568-1.
- ↑ "Mirror descent algorithm". https://tlienart.github.io/posts/2018/10/27-mirror-descent-algorithm/.
- ↑ 34.0 34.1 Bubeck, Sébastien (2015). "Convex Optimization: Algorithms and Complexity". arXiv:1405.4980 [math.OC].
Further reading
- Boyd, Stephen; Vandenberghe, Lieven (2004). "Unconstrained Minimization". Convex Optimization. New York: Cambridge University Press. pp. 457–520. ISBN 0-521-83378-7. https://web.stanford.edu/~boyd/cvxbook/bv_cvxbook.pdf#page=471.
- Chong, Edwin K. P.; Żak, Stanislaw H. (2013). "Gradient Methods". An Introduction to Optimization (Fourth ed.). Hoboken: Wiley. pp. 131–160. ISBN 978-1-118-27901-4. https://books.google.com/books?id=iD5s0iKXHP8C&pg=PA131.
- Himmelblau, David M. (1972). "Unconstrained Minimization Procedures Using Derivatives". Applied Nonlinear Programming. New York: McGraw-Hill. pp. 63–132. ISBN 0-07-028921-2.
External links
- Using gradient descent in C++, Boost, Ublas for linear regression
- Series of Khan Academy videos discusses gradient ascent
- Online book teaching gradient descent in deep neural network context
- Archived at Ghostarchive and the Wayback Machine{{cbignore} b |work=3Blue1Brown |title=Gradient Descent, How Neural Networks Learn |date=October 16, 2017 |url=https://www.youtube.com/watch?v=IHZwWFHWa-w&list=PLZHQObOWTQDNU6R1_67000Dx_ZCJB-3pi&index=2 |via=YouTube }} * Garrigos, Guillaume; Gower, Robert M. (2023). "Handbook of Convergence Theorems for (Stochastic) Gradient Methods". arXiv:2301.11235 [math.OC].
|  | |||||||||||||||||
| ||||||||||||||||||
| ||||||||||||||||||
| ||||||||||||||||||
 |  |

