Biology:DNA sequencing
| Part of a series on |
| Genetics |
|---|
 |
| Key components |
| History and topics |
| Research |
| Personalized medicine |
| Personalized medicine |
DNA sequencing is the process of determining the nucleic acid sequence – the order of nucleotides in DNA. It includes any method or technology that is used to determine the order of the four bases: adenine, guanine, cytosine, and thymine. The advent of rapid DNA sequencing methods has greatly accelerated biological and medical research and discovery.[1][2]
Knowledge of DNA sequences has become indispensable for basic biological research, DNA Genographic Projects and in numerous applied fields such as medical diagnosis, biotechnology, forensic biology, virology and biological systematics. Comparing healthy and mutated DNA sequences can diagnose different diseases including various cancers,[3] characterize antibody repertoire,[4] and can be used to guide patient treatment.[5] Having a quick way to sequence DNA allows for faster and more individualized medical care to be administered, and for more organisms to be identified and cataloged.[4]
The rapid speed of sequencing attained with modern DNA sequencing technology has been instrumental in the sequencing of complete DNA sequences, or genomes, of numerous types and species of life, including the human genome and other complete DNA sequences of many animal, plant, and microbial species.

The first DNA sequences were obtained in the early 1970s by academic researchers using laborious methods based on two-dimensional chromatography. Following the development of fluorescence-based sequencing methods with a DNA sequencer,[6] DNA sequencing has become easier and orders of magnitude faster.[7][8]
Applications
DNA sequencing may be used to determine the sequence of individual genes, larger genetic regions (i.e. clusters of genes or operons), full chromosomes, or entire genomes of any organism. DNA sequencing is also the most efficient way to indirectly sequence RNA or proteins (via their open reading frames). In fact, DNA sequencing has become a key technology in many areas of biology and other sciences such as medicine, forensics, and anthropology.
Molecular biology
Sequencing is used in molecular biology to study genomes and the proteins they encode. Information obtained using sequencing allows researchers to identify changes in genes and noncoding DNA (including regulatory sequences), associations with diseases and phenotypes, and identify potential drug targets.
Evolutionary biology
Since DNA is an informative macromolecule in terms of transmission from one generation to another, DNA sequencing is used in evolutionary biology to study how different organisms are related and how they evolved. In February 2021, scientists reported, for the first time, the sequencing of DNA from animal remains, a mammoth in this instance, over a million years old, the oldest DNA sequenced to date.[9][10]
Metagenomics
The field of metagenomics involves identification of organisms present in a body of water, sewage, dirt, debris filtered from the air, or swab samples from organisms. Knowing which organisms are present in a particular environment is critical to research in ecology, epidemiology, microbiology, and other fields. Sequencing enables researchers to determine which types of microbes may be present in a microbiome, for example.
Virology
As most viruses are too small to be seen by a light microscope, sequencing is one of the main tools in virology to identify and study the virus.[11] Viral genomes can be based in DNA or RNA. RNA viruses are more time-sensitive for genome sequencing, as they degrade faster in clinical samples.[12] Traditional Sanger sequencing and next-generation sequencing are used to sequence viruses in basic and clinical research, as well as for the diagnosis of emerging viral infections, molecular epidemiology of viral pathogens, and drug-resistance testing. There are more than 2.3 million unique viral sequences in GenBank.[11] Recently, NGS has surpassed traditional Sanger as the most popular approach for generating viral genomes.[11]
During the 1990 avian influenza outbreak, viral sequencing determined that the influenza sub-type originated through reassortment between quail and poultry. This led to legislation in Hong Kong that prohibited selling live quail and poultry together at market. Viral sequencing can also be used to estimate when a viral outbreak began by using a molecular clock technique.[12]
Medicine
Medical technicians may sequence genes (or, theoretically, full genomes) from patients to determine if there is risk of genetic diseases. This is a form of genetic testing, though some genetic tests may not involve DNA sequencing.
DNA sequencing is also being increasingly used to diagnose and treat rare diseases. As more and more genes are identified that cause rare genetic diseases, molecular diagnoses for patients becomes more mainstream. DNA sequencing allows clinicians to identify genetic diseases, improve disease management, provide reproductive counseling, and more effective therapies.[13]
Also, DNA sequencing may be useful for determining a specific bacteria, to allow for more precise antibiotics treatments, hereby reducing the risk of creating antimicrobial resistance in bacteria populations.[14][15][16][17][18][19]
Forensic investigation
DNA sequencing may be used along with DNA profiling methods for forensic identification[20] and paternity testing. DNA testing has evolved tremendously in the last few decades to ultimately link a DNA print to what is under investigation. The DNA patterns in fingerprint, saliva, hair follicles, etc. uniquely separate each living organism from another. Testing DNA is a technique which can detect specific genomes in a DNA strand to produce a unique and individualized pattern.
The four canonical bases
The canonical structure of DNA has four bases: thymine (T), adenine (A), cytosine (C), and guanine (G). DNA sequencing is the determination of the physical order of these bases in a molecule of DNA. However, there are many other bases that may be present in a molecule. In some viruses (specifically, bacteriophage), cytosine may be replaced by hydroxy methyl or hydroxy methyl glucose cytosine.[21] In mammalian DNA, variant bases with methyl groups or phosphosulfate may be found.[22][23] Depending on the sequencing technique, a particular modification, e.g., the 5mC (5 methyl cytosine) common in humans, may or may not be detected.[24]
In almost all organisms, DNA is synthesized in vivo using only the 4 canonical bases; modification that occurs post replication creates other bases like 5 methyl C. However, some bacteriophage can incorporate a non standard base directly.[25]
In addittion to modifications, DNA is under constant assault by environmental agents such as UV and Oxygen radicals. At the present time, the presence of such damaged bases is not detected by most DNA sequencing methods, although PacBio has published on this https://www.pacb.com/publications/direct-detection-and-sequencing-of-damaged-dna-bases/
History
Discovery of DNA structure and function
Deoxyribonucleic acid (DNA) was first discovered and isolated by Friedrich Miescher in 1869, but it remained under-studied for many decades because proteins, rather than DNA, were thought to hold the genetic blueprint to life. This situation changed after 1944 as a result of some experiments by Oswald Avery, Colin MacLeod, and Maclyn McCarty demonstrating that purified DNA could change one strain of bacteria into another. This was the first time that DNA was shown capable of transforming the properties of cells.
In 1953, James Watson and Francis Crick put forward their double-helix model of DNA, based on crystallized X-ray structures being studied by Rosalind Franklin. According to the model, DNA is composed of two strands of nucleotides coiled around each other, linked together by hydrogen bonds and running in opposite directions. Each strand is composed of four complementary nucleotides – adenine (A), cytosine (C), guanine (G) and thymine (T) – with an A on one strand always paired with T on the other, and C always paired with G. They proposed that such a structure allowed each strand to be used to reconstruct the other, an idea central to the passing on of hereditary information between generations.[26]

The foundation for sequencing proteins was first laid by the work of Frederick Sanger who by 1955 had completed the sequence of all the amino acids in insulin, a small protein secreted by the pancreas. This provided the first conclusive evidence that proteins were chemical entities with a specific molecular pattern rather than a random mixture of material suspended in fluid. Sanger's success in sequencing insulin spurred on x-ray crystallographers, including Watson and Crick, who by now were trying to understand how DNA directed the formation of proteins within a cell. Soon after attending a series of lectures given by Frederick Sanger in October 1954, Crick began developing a theory which argued that the arrangement of nucleotides in DNA determined the sequence of amino acids in proteins, which in turn helped determine the function of a protein. He published this theory in 1958.[27]
RNA sequencing
RNA sequencing was one of the earliest forms of nucleotide sequencing. The major landmark of RNA sequencing is the sequence of the first complete gene and the complete genome of Bacteriophage MS2, identified and published by Walter Fiers and his coworkers at the University of Ghent (Ghent, Belgium), in 1972[28] and 1976.[29] Traditional RNA sequencing methods require the creation of a cDNA molecule which must be sequenced.[30]
Early DNA sequencing methods
The first method for determining DNA sequences involved a location-specific primer extension strategy established by Ray Wu at Cornell University in 1970.[31] DNA polymerase catalysis and specific nucleotide labeling, both of which figure prominently in current sequencing schemes, were used to sequence the cohesive ends of lambda phage DNA.[32][33][34] Between 1970 and 1973, Wu, R Padmanabhan and colleagues demonstrated that this method can be employed to determine any DNA sequence using synthetic location-specific primers.[35][36][8] Frederick Sanger then adopted this primer-extension strategy to develop more rapid DNA sequencing methods at the MRC Centre, Cambridge, UK and published a method for "DNA sequencing with chain-terminating inhibitors" in 1977.[37] Walter Gilbert and Allan Maxam at Harvard also developed sequencing methods, including one for "DNA sequencing by chemical degradation".[38][39] In 1973, Gilbert and Maxam reported the sequence of 24 basepairs using a method known as wandering-spot analysis.[40] Advancements in sequencing were aided by the concurrent development of recombinant DNA technology, allowing DNA samples to be isolated from sources other than viruses.
Sequencing of full genomes

The first full DNA genome to be sequenced was that of bacteriophage φX174 in 1977.[41] Medical Research Council scientists deciphered the complete DNA sequence of the Epstein-Barr virus in 1984, finding it contained 172,282 nucleotides. Completion of the sequence marked a significant turning point in DNA sequencing because it was achieved with no prior genetic profile knowledge of the virus.[42][8]
A non-radioactive method for transferring the DNA molecules of sequencing reaction mixtures onto an immobilizing matrix during electrophoresis was developed by Herbert Pohl and co-workers in the early 1980s.[43][44] Followed by the commercialization of the DNA sequencer "Direct-Blotting-Electrophoresis-System GATC 1500" by GATC Biotech, which was intensively used in the framework of the EU genome-sequencing programme, the complete DNA sequence of the yeast Saccharomyces cerevisiae chromosome II.[45] Leroy E. Hood's laboratory at the California Institute of Technology announced the first semi-automated DNA sequencing machine in 1986.[46] This was followed by Applied Biosystems' marketing of the first fully automated sequencing machine, the ABI 370, in 1987 and by Dupont's Genesis 2000[47] which used a novel fluorescent labeling technique enabling all four dideoxynucleotides to be identified in a single lane. By 1990, the U.S. National Institutes of Health (NIH) had begun large-scale sequencing trials on Mycoplasma capricolum, Escherichia coli, Caenorhabditis elegans, and Saccharomyces cerevisiae at a cost of US$0.75 per base. Meanwhile, sequencing of human cDNA sequences called expressed sequence tags began in Craig Venter's lab, an attempt to capture the coding fraction of the human genome.[48] In 1995, Venter, Hamilton Smith, and colleagues at The Institute for Genomic Research (TIGR) published the first complete genome of a free-living organism, the bacterium Haemophilus influenzae. The circular chromosome contains 1,830,137 bases and its publication in the journal Science[49] marked the first published use of whole-genome shotgun sequencing, eliminating the need for initial mapping efforts.
By 2001, shotgun sequencing methods had been used to produce a draft sequence of the human genome.[50][51]
High-throughput sequencing (HTS) methods

Several new methods for DNA sequencing were developed in the mid to late 1990s and were implemented in commercial DNA sequencers by 2000. Together these were called the "next-generation" or "second-generation" sequencing (NGS) methods, in order to distinguish them from the earlier methods, including Sanger sequencing. In contrast to the first generation of sequencing, NGS technology is typically characterized by being highly scalable, allowing the entire genome to be sequenced at once. Usually, this is accomplished by fragmenting the genome into small pieces, randomly sampling for a fragment, and sequencing it using one of a variety of technologies, such as those described below. An entire genome is possible because multiple fragments are sequenced at once (giving it the name "massively parallel" sequencing) in an automated process.
NGS technology has tremendously empowered researchers to look for insights into health, anthropologists to investigate human origins, and is catalyzing the "Personalized Medicine" movement. However, it has also opened the door to more room for error. There are many software tools to carry out the computational analysis of NGS data, often compiled at online platforms such as CSI NGS Portal, each with its own algorithm. Even the parameters within one software package can change the outcome of the analysis. In addition, the large quantities of data produced by DNA sequencing have also required development of new methods and programs for sequence analysis. Several efforts to develop standards in the NGS field have been attempted to address these challenges, most of which have been small-scale efforts arising from individual labs. Most recently, a large, organized, FDA-funded effort has culminated in the BioCompute standard.
On 26 October 1990, Roger Tsien, Pepi Ross, Margaret Fahnestock and Allan J Johnston filed a patent describing stepwise ("base-by-base") sequencing with removable 3' blockers on DNA arrays (blots and single DNA molecules).[53] In 1996, Pål Nyrén and his student Mostafa Ronaghi at the Royal Institute of Technology in Stockholm published their method of pyrosequencing.[54]
On 1 April 1997, Pascal Mayer and Laurent Farinelli submitted patents to the World Intellectual Property Organization describing DNA colony sequencing.[55] The DNA sample preparation and random surface-polymerase chain reaction (PCR) arraying methods described in this patent, coupled to Roger Tsien et al.'s "base-by-base" sequencing method, is now implemented in Illumina's Hi-Seq genome sequencers.
In 1998, Phil Green and Brent Ewing of the University of Washington described their phred quality score for sequencer data analysis,[56] a landmark analysis technique that gained widespread adoption, and which is still the most common metric for assessing the accuracy of a sequencing platform.[57]
Lynx Therapeutics published and marketed massively parallel signature sequencing (MPSS), in 2000. This method incorporated a parallelized, adapter/ligation-mediated, bead-based sequencing technology and served as the first commercially available "next-generation" sequencing method, though no DNA sequencers were sold to independent laboratories.[58]
Basic methods
Maxam-Gilbert sequencing
Allan Maxam and Walter Gilbert published a DNA sequencing method in 1977 based on chemical modification of DNA and subsequent cleavage at specific bases.[38] Also known as chemical sequencing, this method allowed purified samples of double-stranded DNA to be used without further cloning. This method's use of radioactive labeling and its technical complexity discouraged extensive use after refinements in the Sanger methods had been made.
Maxam-Gilbert sequencing requires radioactive labeling at one 5' end of the DNA and purification of the DNA fragment to be sequenced. Chemical treatment then generates breaks at a small proportion of one or two of the four nucleotide bases in each of four reactions (G, A+G, C, C+T). The concentration of the modifying chemicals is controlled to introduce on average one modification per DNA molecule. Thus a series of labeled fragments is generated, from the radiolabeled end to the first "cut" site in each molecule. The fragments in the four reactions are electrophoresed side by side in denaturing acrylamide gels for size separation. To visualize the fragments, the gel is exposed to X-ray film for autoradiography, yielding a series of dark bands each corresponding to a radiolabeled DNA fragment, from which the sequence may be inferred.[38]
This method is mostly obsolete as of 2023.[59]
Chain-termination methods
The chain-termination method developed by Frederick Sanger and coworkers in 1977 soon became the method of choice, owing to its relative ease and reliability.[37][60] When invented, the chain-terminator method used fewer toxic chemicals and lower amounts of radioactivity than the Maxam and Gilbert method. Because of its comparative ease, the Sanger method was soon automated and was the method used in the first generation of DNA sequencers.
Sanger sequencing is the method which prevailed from the 1980s until the mid-2000s. Over that period, great advances were made in the technique, such as fluorescent labelling, capillary electrophoresis, and general automation. These developments allowed much more efficient sequencing, leading to lower costs. The Sanger method, in mass production form, is the technology which produced the first human genome in 2001, ushering in the age of genomics. However, later in the decade, radically different approaches reached the market, bringing the cost per genome down from $100 million in 2001 to $10,000 in 2011.[61]
Sequencing by synthesis
The objective for sequential sequencing by synthesis (SBS) is to determine the sequencing of a DNA sample by detecting the incorporation of a nucleotide by a DNA polymerase. An engineered polymerase is used to synthesize a copy of a single strand of DNA and the incorporation of each nucleotide is monitored. The principle of real-time sequencing by synthesis was first described in 1993[62] with improvements published some years later.[63] The key parts are highly similar for all embodiments of SBS and includes (1) amplification of DNA (to enhance the subsequent signal) and attach the DNA to be sequenced to a solid support, (2) generation of single stranded DNA on the solid support, (3) incorporation of nucleotides using an engineered polymerase and (4) real-time detection of the incorporation of nucleotide The steps 3-4 are repeated and the sequence is assembled from the signals obtained in step 4. This principle of real-time sequencing-by-synthesis has been used for almost all massive parallel sequencing instruments, including 454, PacBio, IonTorrent, Illumina and MGI.
Large-scale sequencing and de novo sequencing

Large-scale sequencing often aims at sequencing very long DNA pieces, such as whole chromosomes, although large-scale sequencing can also be used to generate very large numbers of short sequences, such as found in phage display. For longer targets such as chromosomes, common approaches consist of cutting (with restriction enzymes) or shearing (with mechanical forces) large DNA fragments into shorter DNA fragments. The fragmented DNA may then be cloned into a DNA vector and amplified in a bacterial host such as Escherichia coli. Short DNA fragments purified from individual bacterial colonies are individually sequenced and assembled electronically into one long, contiguous sequence. Studies have shown that adding a size selection step to collect DNA fragments of uniform size can improve sequencing efficiency and accuracy of the genome assembly. In these studies, automated sizing has proven to be more reproducible and precise than manual gel sizing.[64][65][66]
The term "de novo sequencing" specifically refers to methods used to determine the sequence of DNA with no previously known sequence. De novo translates from Latin as "from the beginning". Gaps in the assembled sequence may be filled by primer walking. The different strategies have different tradeoffs in speed and accuracy; shotgun methods are often used for sequencing large genomes, but its assembly is complex and difficult, particularly with sequence repeats often causing gaps in genome assembly.
Most sequencing approaches use an in vitro cloning step to amplify individual DNA molecules, because their molecular detection methods are not sensitive enough for single molecule sequencing. Emulsion PCR[67] isolates individual DNA molecules along with primer-coated beads in aqueous droplets within an oil phase. A polymerase chain reaction (PCR) then coats each bead with clonal copies of the DNA molecule followed by immobilization for later sequencing. Emulsion PCR is used in the methods developed by Marguilis et al. (commercialized by 454 Life Sciences), Shendure and Porreca et al. (also known as "polony sequencing") and SOLiD sequencing, (developed by Agencourt, later Applied Biosystems, now Life Technologies).[68][69][70] Emulsion PCR is also used in the GemCode and Chromium platforms developed by 10x Genomics.[71]
Shotgun sequencing
Shotgun sequencing is a sequencing method designed for analysis of DNA sequences longer than 1000 base pairs, up to and including entire chromosomes. This method requires the target DNA to be broken into random fragments. After sequencing individual fragments using the chain termination method, the sequences can be reassembled on the basis of their overlapping regions.[72]
High-throughput methods

High-throughput sequencing, which includes next-generation "short-read" and third-generation "long-read" sequencing methods,[nt 1] applies to exome sequencing, genome sequencing, genome resequencing, transcriptome profiling (RNA-Seq), DNA-protein interactions (ChIP-sequencing), and epigenome characterization.[73]
The high demand for low-cost sequencing has driven the development of high-throughput sequencing technologies that parallelize the sequencing process, producing thousands or millions of sequences concurrently.[74][75][76] High-throughput sequencing technologies are intended to lower the cost of DNA sequencing beyond what is possible with standard dye-terminator methods.[77] In ultra-high-throughput sequencing as many as 500,000 sequencing-by-synthesis operations may be run in parallel.[78][79][80] Such technologies led to the ability to sequence an entire human genome in as little as one day.[81] (As of 2019), corporate leaders in the development of high-throughput sequencing products included Illumina, Qiagen and ThermoFisher Scientific.[81]
| Method | Read length | Accuracy (single read not consensus) | Reads per run | Time per run | Cost per 1 billion bases (in US$) | Advantages | Disadvantages |
|---|---|---|---|---|---|---|---|
| Single-molecule real-time sequencing (Pacific Biosciences) | 30,000 bp (N50); | Fast. Detects 4mC, 5mC, 6mA.[87] | Moderate throughput. Equipment can be very expensive. | ||||
| Ion semiconductor (Ion Torrent sequencing) | up to 600 bp[88] | 99.6%[89] | up to 80 million | 2 hours | $66.8-$950 | Less expensive equipment. Fast. | Homopolymer errors. |
| Pyrosequencing (454) | 700 bp | 99.9% | 1 million | 24 hours | $10,000 | Long read size. Fast. | Runs are expensive. Homopolymer errors. |
| Sequencing by synthesis (Illumina) | MiniSeq, NextSeq: 75–300 bp;
MiSeq: 50–600 bp; HiSeq 2500: 50–500 bp; HiSeq 3/4000: 50–300 bp; HiSeq X: 300 bp |
99.9% (Phred30) | MiniSeq/MiSeq: 1–25 Million;
NextSeq: 130-00 Million; HiSeq 2500: 300 million – 2 billion; HiSeq 3/4000 2.5 billion; HiSeq X: 3 billion |
1 to 11 days, depending upon sequencer and specified read length[90] | $5 to $150 | Potential for high sequence yield, depending upon sequencer model and desired application. | Equipment can be very expensive. Requires high concentrations of DNA. |
| Combinatorial probe anchor synthesis (cPAS- BGI/MGI) | BGISEQ-50: 35-50bp;
MGISEQ 200: 50-200bp; BGISEQ-500, MGISEQ-2000: 50-300bp[91] |
99.9% (Phred30) | BGISEQ-50: 160M;
MGISEQ 200: 300M; BGISEQ-500: 1300M per flow cell; MGISEQ-2000: 375M FCS flow cell, 1500M FCL flow cell per flow cell. |
1 to 9 days depending on instrument, read length and number of flow cells run at a time. | $5– $120 | ||
| Sequencing by ligation (SOLiD sequencing) | 50+35 or 50+50 bp | 99.9% | 1.2 to 1.4 billion | 1 to 2 weeks | $60–130 | Low cost per base. | Slower than other methods. Has issues sequencing palindromic sequences.[92] |
| Nanopore Sequencing | Dependent on library preparation, not the device, so user chooses read length (up to 2,272,580 bp reported[93]). | ~92–97% single read | dependent on read length selected by user | data streamed in real time. Choose 1 min to 48 hrs | $7–100 | Longest individual reads. Accessible user community. Portable (Palm sized). | Lower throughput than other machines, Single read accuracy in 90s. |
| GenapSys Sequencing | Around 150 bp single-end | 99.9% (Phred30) | 1 to 16 million | Around 24 hours | $667 | Low-cost of instrument ($10,000) | |
| Chain termination (Sanger sequencing) | 400 to 900 bp | 99.9% | N/A | 20 minutes to 3 hours | $2,400,000 | Useful for many applications. | More expensive and impractical for larger sequencing projects. This method also requires the time-consuming step of plasmid cloning or PCR. |
Long-read sequencing methods
Single molecule real time (SMRT) sequencing
SMRT sequencing is based on the sequencing by synthesis approach. The DNA is synthesized in zero-mode wave-guides (ZMWs) – small well-like containers with the capturing tools located at the bottom of the well. The sequencing is performed with use of unmodified polymerase (attached to the ZMW bottom) and fluorescently labelled nucleotides flowing freely in the solution. The wells are constructed in a way that only the fluorescence occurring by the bottom of the well is detected. The fluorescent label is detached from the nucleotide upon its incorporation into the DNA strand, leaving an unmodified DNA strand. According to Pacific Biosciences (PacBio), the SMRT technology developer, this methodology allows detection of nucleotide modifications (such as cytosine methylation). This happens through the observation of polymerase kinetics. This approach allows reads of 20,000 nucleotides or more, with average read lengths of 5 kilobases.[94][95] In 2015, Pacific Biosciences announced the launch of a new sequencing instrument called the Sequel System, with 1 million ZMWs compared to 150,000 ZMWs in the PacBio RS II instrument.[96][97] SMRT sequencing is referred to as "third-generation" or "long-read" sequencing.
Nanopore DNA sequencing
The DNA passing through the nanopore changes its ion current. This change is dependent on the shape, size and length of the DNA sequence. Each type of the nucleotide blocks the ion flow through the pore for a different period of time. The method does not require modified nucleotides and is performed in real time. Nanopore sequencing is referred to as "third-generation" or "long-read" sequencing, along with SMRT sequencing.
Early industrial research into this method was based on a technique called 'exonuclease sequencing', where the readout of electrical signals occurred as nucleotides passed by alpha(α)-hemolysin pores covalently bound with cyclodextrin.[98] However the subsequent commercial method, 'strand sequencing', sequenced DNA bases in an intact strand.
Two main areas of nanopore sequencing in development are solid state nanopore sequencing, and protein based nanopore sequencing. Protein nanopore sequencing utilizes membrane protein complexes such as α-hemolysin, MspA (Mycobacterium smegmatis Porin A) or CssG, which show great promise given their ability to distinguish between individual and groups of nucleotides.[99] In contrast, solid-state nanopore sequencing utilizes synthetic materials such as silicon nitride and aluminum oxide and it is preferred for its superior mechanical ability and thermal and chemical stability.[100] The fabrication method is essential for this type of sequencing given that the nanopore array can contain hundreds of pores with diameters smaller than eight nanometers.[99]
The concept originated from the idea that single stranded DNA or RNA molecules can be electrophoretically driven in a strict linear sequence through a biological pore that can be less than eight nanometers, and can be detected given that the molecules release an ionic current while moving through the pore. The pore contains a detection region capable of recognizing different bases, with each base generating various time specific signals corresponding to the sequence of bases as they cross the pore which are then evaluated.[100] Precise control over the DNA transport through the pore is crucial for success. Various enzymes such as exonucleases and polymerases have been used to moderate this process by positioning them near the pore's entrance.[101]
Short-read sequencing methods
Massively parallel signature sequencing (MPSS)
The first of the high-throughput sequencing technologies, massively parallel signature sequencing (or MPSS), was developed in the 1990s at Lynx Therapeutics, a company founded in 1992 by Sydney Brenner and Sam Eletr. MPSS was a bead-based method that used a complex approach of adapter ligation followed by adapter decoding, reading the sequence in increments of four nucleotides. This method made it susceptible to sequence-specific bias or loss of specific sequences. Because the technology was so complex, MPSS was only performed 'in-house' by Lynx Therapeutics and no DNA sequencing machines were sold to independent laboratories. Lynx Therapeutics merged with Solexa (later acquired by Illumina) in 2004, leading to the development of sequencing-by-synthesis, a simpler approach acquired from Manteia Predictive Medicine, which rendered MPSS obsolete. However, the essential properties of the MPSS output were typical of later high-throughput data types, including hundreds of thousands of short DNA sequences. In the case of MPSS, these were typically used for sequencing cDNA for measurements of gene expression levels.[58]
Polony sequencing
The polony sequencing method, developed in the laboratory of George M. Church at Harvard, was among the first high-throughput sequencing systems and was used to sequence a full E. coli genome in 2005.[102] It combined an in vitro paired-tag library with emulsion PCR, an automated microscope, and ligation-based sequencing chemistry to sequence an E. coli genome at an accuracy of >99.9999% and a cost approximately 1/9 that of Sanger sequencing.[102] The technology was licensed to Agencourt Biosciences, subsequently spun out into Agencourt Personal Genomics, and eventually incorporated into the Applied Biosystems SOLiD platform. Applied Biosystems was later acquired by Life Technologies, now part of Thermo Fisher Scientific.
454 pyrosequencing
A parallelized version of pyrosequencing was developed by 454 Life Sciences, which has since been acquired by Roche Diagnostics. The method amplifies DNA inside water droplets in an oil solution (emulsion PCR), with each droplet containing a single DNA template attached to a single primer-coated bead that then forms a clonal colony. The sequencing machine contains many picoliter-volume wells each containing a single bead and sequencing enzymes. Pyrosequencing uses luciferase to generate light for detection of the individual nucleotides added to the nascent DNA, and the combined data are used to generate sequence reads.[68] This technology provides intermediate read length and price per base compared to Sanger sequencing on one end and Solexa and SOLiD on the other.[77]
Illumina (Solexa) sequencing
Solexa, now part of Illumina, was founded by Shankar Balasubramanian and David Klenerman in 1998, and developed a sequencing method based on reversible dye-terminators technology, and engineered polymerases.[103] The reversible terminated chemistry concept was invented by Bruno Canard and Simon Sarfati at the Pasteur Institute in Paris.[104][105] It was developed internally at Solexa by those named on the relevant patents. In 2004, Solexa acquired the company Manteia Predictive Medicine in order to gain a massively parallel sequencing technology invented in 1997 by Pascal Mayer and Laurent Farinelli.[55] It is based on "DNA clusters" or "DNA colonies", which involves the clonal amplification of DNA on a surface. The cluster technology was co-acquired with Lynx Therapeutics of California. Solexa Ltd. later merged with Lynx to form Solexa Inc.


In this method, DNA molecules and primers are first attached on a slide or flow cell and amplified with polymerase so that local clonal DNA colonies, later coined "DNA clusters", are formed. To determine the sequence, four types of reversible terminator bases (RT-bases) are added and non-incorporated nucleotides are washed away. A camera takes images of the fluorescently labeled nucleotides. Then the dye, along with the terminal 3' blocker, is chemically removed from the DNA, allowing for the next cycle to begin. Unlike pyrosequencing, the DNA chains are extended one nucleotide at a time and image acquisition can be performed at a delayed moment, allowing for very large arrays of DNA colonies to be captured by sequential images taken from a single camera.

Decoupling the enzymatic reaction and the image capture allows for optimal throughput and theoretically unlimited sequencing capacity. With an optimal configuration, the ultimately reachable instrument throughput is thus dictated solely by the analog-to-digital conversion rate of the camera, multiplied by the number of cameras and divided by the number of pixels per DNA colony required for visualizing them optimally (approximately 10 pixels/colony). In 2012, with cameras operating at more than 10 MHz A/D conversion rates and available optics, fluidics and enzymatics, throughput can be multiples of 1 million nucleotides/second, corresponding roughly to 1 human genome equivalent at 1x coverage per hour per instrument, and 1 human genome re-sequenced (at approx. 30x) per day per instrument (equipped with a single camera).[106]
Combinatorial probe anchor synthesis (cPAS)
This method is an upgraded modification to combinatorial probe anchor ligation technology (cPAL) described by Complete Genomics[107] which has since become part of Chinese genomics company BGI in 2013.[108] The two companies have refined the technology to allow for longer read lengths, reaction time reductions and faster time to results. In addition, data are now generated as contiguous full-length reads in the standard FASTQ file format and can be used as-is in most short-read-based bioinformatics analysis pipelines.[109][citation needed]
The two technologies that form the basis for this high-throughput sequencing technology are DNA nanoballs (DNB) and patterned arrays for nanoball attachment to a solid surface.[107] DNA nanoballs are simply formed by denaturing double stranded, adapter ligated libraries and ligating the forward strand only to a splint oligonucleotide to form a ssDNA circle. Faithful copies of the circles containing the DNA insert are produced utilizing Rolling Circle Amplification that generates approximately 300–500 copies. The long strand of ssDNA folds upon itself to produce a three-dimensional nanoball structure that is approximately 220 nm in diameter. Making DNBs replaces the need to generate PCR copies of the library on the flow cell and as such can remove large proportions of duplicate reads, adapter-adapter ligations and PCR induced errors.[109][citation needed]

The patterned array of positively charged spots is fabricated through photolithography and etching techniques followed by chemical modification to generate a sequencing flow cell. Each spot on the flow cell is approximately 250 nm in diameter, are separated by 700 nm (centre to centre) and allows easy attachment of a single negatively charged DNB to the flow cell and thus reducing under or over-clustering on the flow cell.[107][citation needed]
Sequencing is then performed by addition of an oligonucleotide probe that attaches in combination to specific sites within the DNB. The probe acts as an anchor that then allows one of four single reversibly inactivated, labelled nucleotides to bind after flowing across the flow cell. Unbound nucleotides are washed away before laser excitation of the attached labels then emit fluorescence and signal is captured by cameras that is converted to a digital output for base calling. The attached base has its terminator and label chemically cleaved at completion of the cycle. The cycle is repeated with another flow of free, labelled nucleotides across the flow cell to allow the next nucleotide to bind and have its signal captured. This process is completed a number of times (usually 50 to 300 times) to determine the sequence of the inserted piece of DNA at a rate of approximately 40 million nucleotides per second as of 2018.[citation needed]
SOLiD sequencing

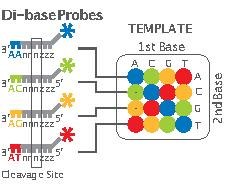
Applied Biosystems' (now a Life Technologies brand) SOLiD technology employs sequencing by ligation. Here, a pool of all possible oligonucleotides of a fixed length are labeled according to the sequenced position. Oligonucleotides are annealed and ligated; the preferential ligation by DNA ligase for matching sequences results in a signal informative of the nucleotide at that position. Each base in the template is sequenced twice, and the resulting data are decoded according to the 2 base encoding scheme used in this method. Before sequencing, the DNA is amplified by emulsion PCR. The resulting beads, each containing single copies of the same DNA molecule, are deposited on a glass slide.[110] The result is sequences of quantities and lengths comparable to Illumina sequencing.[77] This sequencing by ligation method has been reported to have some issue sequencing palindromic sequences.[92]
Ion Torrent semiconductor sequencing
Ion Torrent Systems Inc. (now owned by Life Technologies) developed a system based on using standard sequencing chemistry, but with a novel, semiconductor-based detection system. This method of sequencing is based on the detection of hydrogen ions that are released during the polymerisation of DNA, as opposed to the optical methods used in other sequencing systems. A microwell containing a template DNA strand to be sequenced is flooded with a single type of nucleotide. If the introduced nucleotide is complementary to the leading template nucleotide it is incorporated into the growing complementary strand. This causes the release of a hydrogen ion that triggers a hypersensitive ion sensor, which indicates that a reaction has occurred. If homopolymer repeats are present in the template sequence, multiple nucleotides will be incorporated in a single cycle. This leads to a corresponding number of released hydrogens and a proportionally higher electronic signal.[111]

DNA nanoball sequencing
DNA nanoball sequencing is a type of high throughput sequencing technology used to determine the entire genomic sequence of an organism. The company Complete Genomics uses this technology to sequence samples submitted by independent researchers. The method uses rolling circle replication to amplify small fragments of genomic DNA into DNA nanoballs. Unchained sequencing by ligation is then used to determine the nucleotide sequence.[112] This method of DNA sequencing allows large numbers of DNA nanoballs to be sequenced per run and at low reagent costs compared to other high-throughput sequencing platforms.[113] However, only short sequences of DNA are determined from each DNA nanoball which makes mapping the short reads to a reference genome difficult.[112]
Heliscope single molecule sequencing
Heliscope sequencing is a method of single-molecule sequencing developed by Helicos Biosciences. It uses DNA fragments with added poly-A tail adapters which are attached to the flow cell surface. The next steps involve extension-based sequencing with cyclic washes of the flow cell with fluorescently labeled nucleotides (one nucleotide type at a time, as with the Sanger method). The reads are performed by the Heliscope sequencer.[114][115] The reads are short, averaging 35 bp.[116] What made this technology especially novel was that it was the first of its class to sequence non-amplified DNA, thus preventing any read errors associated with amplification steps.[117] In 2009 a human genome was sequenced using the Heliscope, however in 2012 the company went bankrupt.[118]
Microfluidic Systems
There are two main microfluidic systems that are used to sequence DNA; droplet based microfluidics and digital microfluidics. Microfluidic devices solve many of the current limitations of current sequencing arrays.
Abate et al. studied the use of droplet-based microfluidic devices for DNA sequencing.[4] These devices have the ability to form and process picoliter sized droplets at the rate of thousands per second. The devices were created from polydimethylsiloxane (PDMS) and used Forster resonance energy transfer, FRET assays to read the sequences of DNA encompassed in the droplets. Each position on the array tested for a specific 15 base sequence.[4]
Fair et al. used digital microfluidic devices to study DNA pyrosequencing.[119] Significant advantages include the portability of the device, reagent volume, speed of analysis, mass manufacturing abilities, and high throughput. This study provided a proof of concept showing that digital devices can be used for pyrosequencing; the study included using synthesis, which involves the extension of the enzymes and addition of labeled nucleotides.[119]
Boles et al. also studied pyrosequencing on digital microfluidic devices.[120] They used an electro-wetting device to create, mix, and split droplets. The sequencing uses a three-enzyme protocol and DNA templates anchored with magnetic beads. The device was tested using two protocols and resulted in 100% accuracy based on raw pyrogram levels. The advantages of these digital microfluidic devices include size, cost, and achievable levels of functional integration.[120]
DNA sequencing research, using microfluidics, also has the ability to be applied to the sequencing of RNA, using similar droplet microfluidic techniques, such as the method, inDrops.[121] This shows that many of these DNA sequencing techniques will be able to be applied further and be used to understand more about genomes and transcriptomes.
Methods in development
DNA sequencing methods currently under development include reading the sequence as a DNA strand transits through nanopores (a method that is now commercial but subsequent generations such as solid-state nanopores are still in development),[122][123] and microscopy-based techniques, such as atomic force microscopy or transmission electron microscopy that are used to identify the positions of individual nucleotides within long DNA fragments (>5,000 bp) by nucleotide labeling with heavier elements (e.g., halogens) for visual detection and recording.[124][125] Third generation technologies aim to increase throughput and decrease the time to result and cost by eliminating the need for excessive reagents and harnessing the processivity of DNA polymerase.[126]
Tunnelling currents DNA sequencing
Another approach uses measurements of the electrical tunnelling currents across single-strand DNA as it moves through a channel. Depending on its electronic structure, each base affects the tunnelling current differently,[127] allowing differentiation between different bases.[128]
The use of tunnelling currents has the potential to sequence orders of magnitude faster than ionic current methods and the sequencing of several DNA oligomers and micro-RNA has already been achieved.[129]
Sequencing by hybridization
Sequencing by hybridization is a non-enzymatic method that uses a DNA microarray. A single pool of DNA whose sequence is to be determined is fluorescently labeled and hybridized to an array containing known sequences. Strong hybridization signals from a given spot on the array identifies its sequence in the DNA being sequenced.[130]
This method of sequencing utilizes binding characteristics of a library of short single stranded DNA molecules (oligonucleotides), also called DNA probes, to reconstruct a target DNA sequence. Non-specific hybrids are removed by washing and the target DNA is eluted.[131] Hybrids are re-arranged such that the DNA sequence can be reconstructed. The benefit of this sequencing type is its ability to capture a large number of targets with a homogenous coverage.[132] A large number of chemicals and starting DNA is usually required. However, with the advent of solution-based hybridization, much less equipment and chemicals are necessary.[131]
Sequencing with mass spectrometry
Mass spectrometry may be used to determine DNA sequences. Matrix-assisted laser desorption ionization time-of-flight mass spectrometry, or MALDI-TOF MS, has specifically been investigated as an alternative method to gel electrophoresis for visualizing DNA fragments. With this method, DNA fragments generated by chain-termination sequencing reactions are compared by mass rather than by size. The mass of each nucleotide is different from the others and this difference is detectable by mass spectrometry. Single-nucleotide mutations in a fragment can be more easily detected with MS than by gel electrophoresis alone. MALDI-TOF MS can more easily detect differences between RNA fragments, so researchers may indirectly sequence DNA with MS-based methods by converting it to RNA first.[133]
The higher resolution of DNA fragments permitted by MS-based methods is of special interest to researchers in forensic science, as they may wish to find single-nucleotide polymorphisms in human DNA samples to identify individuals. These samples may be highly degraded so forensic researchers often prefer mitochondrial DNA for its higher stability and applications for lineage studies. MS-based sequencing methods have been used to compare the sequences of human mitochondrial DNA from samples in a Federal Bureau of Investigation database[134] and from bones found in mass graves of World War I soldiers.[135]
Early chain-termination and TOF MS methods demonstrated read lengths of up to 100 base pairs.[136] Researchers have been unable to exceed this average read size; like chain-termination sequencing alone, MS-based DNA sequencing may not be suitable for large de novo sequencing projects. Even so, a recent study did use the short sequence reads and mass spectroscopy to compare single-nucleotide polymorphisms in pathogenic Streptococcus strains.[137]
Microfluidic Sanger sequencing
In microfluidic Sanger sequencing the entire thermocycling amplification of DNA fragments as well as their separation by electrophoresis is done on a single glass wafer (approximately 10 cm in diameter) thus reducing the reagent usage as well as cost.[138] In some instances researchers have shown that they can increase the throughput of conventional sequencing through the use of microchips.[139] Research will still need to be done in order to make this use of technology effective.
Microscopy-based techniques
This approach directly visualizes the sequence of DNA molecules using electron microscopy. The first identification of DNA base pairs within intact DNA molecules by enzymatically incorporating modified bases, which contain atoms of increased atomic number, direct visualization and identification of individually labeled bases within a synthetic 3,272 base-pair DNA molecule and a 7,249 base-pair viral genome has been demonstrated.[140]
RNAP sequencing
This method is based on use of RNA polymerase (RNAP), which is attached to a polystyrene bead. One end of DNA to be sequenced is attached to another bead, with both beads being placed in optical traps. RNAP motion during transcription brings the beads in closer and their relative distance changes, which can then be recorded at a single nucleotide resolution. The sequence is deduced based on the four readouts with lowered concentrations of each of the four nucleotide types, similarly to the Sanger method.[141] A comparison is made between regions and sequence information is deduced by comparing the known sequence regions to the unknown sequence regions.[142]
In vitro virus high-throughput sequencing
A method has been developed to analyze full sets of protein interactions using a combination of 454 pyrosequencing and an in vitro virus mRNA display method. Specifically, this method covalently links proteins of interest to the mRNAs encoding them, then detects the mRNA pieces using reverse transcription PCRs. The mRNA may then be amplified and sequenced. The combined method was titled IVV-HiTSeq and can be performed under cell-free conditions, though its results may not be representative of in vivo conditions.[143]
While there are many different ways to sequence DNA, only a few dominate the current market. According to this, Illumina is about 80% of the market in 2022; the rest of the market is taken by only a few players (PacBio, Oxford, 454, MGI)[144]
Sample preparation
The success of any DNA sequencing protocol relies upon the DNA or RNA sample extraction and preparation from the biological material of interest.
- A successful DNA extraction will yield a DNA sample with long, non-degraded strands.
- A successful RNA extraction will yield a RNA sample that should be converted to complementary DNA (cDNA) using reverse transcriptase—a DNA polymerase that synthesizes a complementary DNA based on existing strands of RNA in a PCR-like manner.[145] Complementary DNA can then be processed the same way as genomic DNA.
After DNA or RNA extraction, samples may require further preparation depending on the sequencing method. For Sanger sequencing, either cloning procedures or PCR are required prior to sequencing. In the case of next-generation sequencing methods, library preparation is required before processing.[146] Assessing the quality and quantity of nucleic acids both after extraction and after library preparation identifies degraded, fragmented, and low-purity samples and yields high-quality sequencing data.[147]
The high-throughput nature of current DNA/RNA sequencing technologies has posed a challenge for sample preparation method to scale-up. Several liquid handling instruments are being used for the preparation of higher numbers of samples with a lower total hands-on time:
| company | Liquid handlers / Automation | lower_mark_USD | upper_mark_USD | landing_url |
| Opentrons | OpenTrons OT-2 | $6,500 | $20,000 | https://www.opentrons.com/ |
| Gilson | Gilson Pipetmax | $20,000 | $40,000 | https://gb.gilson.com/GBSV/system-pipetmax.html |
| Neotec | Neotec EzMate | $25,000 | $45,000 | http://neotec.co.il/pipetting-device/ |
| Formulatrix | Formulatrix Mantis | $40,000 | $60,000 | https://formulatrix.com/liquid-handling-systems/mantis-liquid-handler/ |
| Hudson Robotics | Hudson Robotics SOLO | $40,000 | $50,000 | https://hudsonrobotics.com/products/applications/automated-solutions-next-generation-sequencing-ngs/ |
| Hamilton | Hamilton Microlab NIMBUS | $40,000 | $80,000 | https://www.hamiltoncompany.com/automated-liquid-handling/platforms/microlab-nimbus#specifications |
| TTP Labtech | TTP Labtech Mosquito HV Genomics | $45,000 | $80,000 | https://www.sptlabtech.com/products/liquid-handling/mosquito-hv-genomics/ |
| Beckman Coulter | Biomek 4000 | $50,000 | $65,000 | https://www.mybeckman.uk/liquid-handlers/biomek-4000/b22640 |
| Hamilton | Hamilton Genomic STARlet | $50,000 | $100,000 | https://www.hamiltoncompany.com/automated-liquid-handling/assay-ready-workstations/genomic-starlet |
| Eppendorf | Eppendorf epMotion 5075t | $95,000 | $110,000 | https://www.eppendorf.com/epmotion/ |
| Beckman Coulter | Beckman Coulter Biomek i5 | $100,000 | $150,000 | https://www.beckman.com/liquid-handlers/biomek-i5 |
| Hamilton | Hamilton NGS STAR | $100,000 | $200,000 | http://www.hamiltonrobotics.com/ |
| PerkinElmer | PerkinElmer Sciclone G3 NGS and NGSx Workstation | $150,000 | $220,000 | https://www.perkinelmer.com/uk/product/sciclone-g3-ngs-workstation-cls145321 |
| Agilent | Agilent Bravo NGS | $170,000 | $290,000 | https://www.agilent.com/en/products/automated-liquid-handling/automated-liquid-handling-applications/bravo-ngs |
| Beckman Coulter | Beckman Coulter Biomek i7 | $200,000 | $250,000 | https://www.beckman.com/liquid-handlers/biomek-i7 |
| Labcyte Echo 525 | Beckman Coulter Labcyte Echo 525 | $260,000 | $300,000 | https://www.labcyte.com/products/liquid-handling/echo-525-liquid-handler |
| Tecan | Tecan NGS | $270,000 | $350,000 | https://lifesciences.tecan.com/ngs-sample-preparation |
Development initiatives

In October 2006, the X Prize Foundation established an initiative to promote the development of full genome sequencing technologies, called the Archon X Prize, intending to award $10 million to "the first Team that can build a device and use it to sequence 100 human genomes within 10 days or less, with an accuracy of no more than one error in every 100,000 bases sequenced, with sequences accurately covering at least 98% of the genome, and at a recurring cost of no more than $10,000 (US) per genome."[148]
Each year the National Human Genome Research Institute, or NHGRI, promotes grants for new research and developments in genomics. 2010 grants and 2011 candidates include continuing work in microfluidic, polony and base-heavy sequencing methodologies.[149]
Computational challenges
The sequencing technologies described here produce raw data that needs to be assembled into longer sequences such as complete genomes (sequence assembly). There are many computational challenges to achieve this, such as the evaluation of the raw sequence data which is done by programs and algorithms such as Phred and Phrap. Other challenges have to deal with repetitive sequences that often prevent complete genome assemblies because they occur in many places of the genome. As a consequence, many sequences may not be assigned to particular chromosomes. The production of raw sequence data is only the beginning of its detailed bioinformatical analysis.[150] Yet new methods for sequencing and correcting sequencing errors were developed.[151]
Read trimming
Sometimes, the raw reads produced by the sequencer are correct and precise only in a fraction of their length. Using the entire read may introduce artifacts in the downstream analyses like genome assembly, SNP calling, or gene expression estimation. Two classes of trimming programs have been introduced, based on the window-based or the running-sum classes of algorithms.[152] This is a partial list of the trimming algorithms currently available, specifying the algorithm class they belong to:
| Name of algorithm | Type of algorithm | Link |
|---|---|---|
| Cutadapt[153] | Running sum | Cutadapt |
| ConDeTri[154] | Window based | ConDeTri |
| ERNE-FILTER[155] | Running sum | ERNE-FILTER |
| FASTX quality trimmer | Window based | FASTX quality trimmer |
| PRINSEQ[156] | Window based | PRINSEQ |
| Trimmomatic[157] | Window based | Trimmomatic |
| SolexaQA[158] | Window based | SolexaQA |
| SolexaQA-BWA | Running sum | SolexaQA-BWA |
| Sickle | Window based | Sickle |
Ethical issues
Human genetics have been included within the field of bioethics since the early 1970s[159] and the growth in the use of DNA sequencing (particularly high-throughput sequencing) has introduced a number of ethical issues. One key issue is the ownership of an individual's DNA and the data produced when that DNA is sequenced.[160] Regarding the DNA molecule itself, the leading legal case on this topic, Moore v. Regents of the University of California (1990) ruled that individuals have no property rights to discarded cells or any profits made using these cells (for instance, as a patented cell line). However, individuals have a right to informed consent regarding removal and use of cells. Regarding the data produced through DNA sequencing, Moore gives the individual no rights to the information derived from their DNA.[160]
As DNA sequencing becomes more widespread, the storage, security and sharing of genomic data has also become more important.[160][161] For instance, one concern is that insurers may use an individual's genomic data to modify their quote, depending on the perceived future health of the individual based on their DNA.[161][162] In May 2008, the Genetic Information Nondiscrimination Act (GINA) was signed in the United States, prohibiting discrimination on the basis of genetic information with respect to health insurance and employment.[163][164] In 2012, the US Presidential Commission for the Study of Bioethical Issues reported that existing privacy legislation for DNA sequencing data such as GINA and the Health Insurance Portability and Accountability Act were insufficient, noting that whole-genome sequencing data was particularly sensitive, as it could be used to identify not only the individual from which the data was created, but also their relatives.[165][166]
In most of the United States, DNA that is "abandoned", such as that found on a licked stamp or envelope, coffee cup, cigarette, chewing gum, household trash, or hair that has fallen on a public sidewalk, may legally be collected and sequenced by anyone, including the police, private investigators, political opponents, or people involved in paternity disputes. As of 2013, eleven states have laws that can be interpreted to prohibit "DNA theft".[167]
Ethical issues have also been raised by the increasing use of genetic variation screening, both in newborns, and in adults by companies such as 23andMe.[168][169] It has been asserted that screening for genetic variations can be harmful, increasing anxiety in individuals who have been found to have an increased risk of disease.[170] For example, in one case noted in Time (magazine) , doctors screening an ill baby for genetic variants chose not to inform the parents of an unrelated variant linked to dementia due to the harm it would cause to the parents.[171] However, a 2011 study in The New England Journal of Medicine has shown that individuals undergoing disease risk profiling did not show increased levels of anxiety.[170] Also, the development of Next Generation sequencing technologies such as Nanopore based sequencing has also raised further ethical concerns.[172]
See also
- Biology:Bioinformatics – Computational analysis of large, complex sets of biological data
- Biology:Cancer genome sequencing
- Circular consensus sequencing
- Biology:DNA computing – Computing using molecular biology hardware
- Biology:DNA field-effect transistor
- Biology:DNA sequencing theory – Biological theory
- Biology:DNA sequencer – A scientific instrument used to automate the DNA sequencing process
- Biology:Genographic Project – Citizen science project
- Biology:Genome project
- Biology:Genome sequencing of endangered species – DNA testing for endangerment assessment
- Biology:Genome skimming – Method of genome sequencing
- Biology:IsoBase
- Linked-read sequencing
- Biology:Jumping library
- Biology:Nucleic acid sequence – Succession of nucleotides in a nucleic acid
- Biology:Multiplex ligation-dependent probe amplification
- Medicine:Personalized medicine – Medical model that tailors medical practices to the individual patient
- Biology:Protein sequencing – Sequencing of amino acid arrangement in a protein
- Software:Sequence profiling tool
- Biology:Sequencing by hybridization
- Biology:Sequencing by ligation
- Software:TIARA (database) – Database of personal genomics information
- Engineering:Transmission electron microscopy DNA sequencing – Single-molecule sequencing technology
Notes
- ↑ "Next-generation" remains in broad use as of 2019. For instance, "From Sanger Sequencing to Genome Databases and Beyond". BioTechniques 66 (2): 60–63. February 2019. doi:10.2144/btn-2019-0011. PMID 30744413. "Next-generation sequencing (NGS) technologies have revolutionized genomic research. (opening sentence of the article)".
References
- ↑ "Introducing 'dark DNA' – the phenomenon that could change how we think about evolution". 24 August 2017. https://theconversation.com/introducing-dark-dna-the-phenomenon-that-could-change-how-we-think-about-evolution-82867.
- ↑ "What is next generation sequencing?". Archives of Disease in Childhood: Education and Practice Edition 98 (6): 236–8. December 2013. doi:10.1136/archdischild-2013-304340. PMID 23986538.
- ↑ "DNA sequencing of cancer: what have we learned?". Annual Review of Medicine 65 (1): 63–79. 2014-01-14. doi:10.1146/annurev-med-060712-200152. PMID 24274178.
- ↑ 4.0 4.1 4.2 4.3 "DNA sequence analysis with droplet-based microfluidics". Lab on a Chip 13 (24): 4864–9. December 2013. doi:10.1039/c3lc50905b. PMID 24185402.
- ↑ "Quantitative and sensitive detection of rare mutations using droplet-based microfluidics". Lab on a Chip 11 (13): 2156–66. July 2011. doi:10.1039/c1lc20128j. PMID 21594292.
- ↑ "Use of automated sequencing of polymerase chain reaction-generated amplicons to identify three types of cholera toxin subunit B in Vibrio cholerae O1 strains". J. Clin. Microbiol. 31 (1): 22–25. January 1993. doi:10.1128/JCM.31.1.22-25.1993. PMID 7678018.

- ↑ "Generations of sequencing technologies". Genomics 93 (2): 105–11. February 2009. doi:10.1016/j.ygeno.2008.10.003. PMID 18992322.
- ↑ 8.0 8.1 8.2 "DNA sequence analysis: a general, simple and rapid method for sequencing large oligodeoxyribonucleotide fragments by mapping". Nucleic Acids Research 1 (3): 331–53. March 1974. doi:10.1093/nar/1.3.331. PMID 10793670.
- ↑ Hunt, Katie (17 February 2021). "World's oldest DNA sequenced from a mammoth that lived more than a million years ago". CNN. https://www.cnn.com/2021/02/17/world/mammoth-oldest-dna-million-years-ago-scn/index.html. Retrieved 17 February 2021.
- ↑ Callaway, Ewen (17 February 2021). "Million-year-old mammoth genomes shatter record for oldest ancient DNA – Permafrost-preserved teeth, up to 1.6 million years old, identify a new kind of mammoth in Siberia.". Nature 590 (7847): 537–538. doi:10.1038/d41586-021-00436-x. PMID 33597786. Bibcode: 2021Natur.590..537C.
- ↑ 11.0 11.1 11.2 Castro, Christina; Marine, Rachel; Ramos, Edward; Ng, Terry Fei Fan (2019). "The effect of variant interference on de novo assembly for viral deep sequencing". BMC Genomics 21 (1): 421. doi:10.1186/s12864-020-06801-w. PMID 32571214.
- ↑ 12.0 12.1 Wohl, Shirlee; Schaffner, Stephen F.; Sabeti, Pardis C. (2016). "Genomic Analysis of Viral Outbreaks". Annual Review of Virology 3 (1): 173–195. doi:10.1146/annurev-virology-110615-035747. PMID 27501264.
- ↑ Boycott, Kym M.; Vanstone, Megan R.; Bulman, Dennis E.; MacKenzie, Alex E. (October 2013). "Rare-disease genetics in the era of next-generation sequencing: discovery to translation". Nature Reviews Genetics 14 (10): 681–691. doi:10.1038/nrg3555. PMID 23999272.
- ↑ "Mycobacterium tuberculosis resistance prediction and lineage classification from genome sequencing: comparison of automated analysis tools". Sci Rep 7: 46327. 2017. doi:10.1038/srep46327. PMID 28425484. Bibcode: 2017NatSR...746327S.
- ↑ "A large scale evaluation of TBProfiler and Mykrobe for antibiotic resistance prediction in Mycobacterium tuberculosis". PeerJ 7: e6857. 2019. doi:10.7717/peerj.6857. PMID 31106066.
- ↑ Mykrobe predictor –Antibiotic resistance prediction for S. aureus and M. tuberculosis from whole genome sequence data
- ↑ Bradley, Phelim; Gordon, N. Claire; Walker, Timothy M.; Dunn, Laura; Heys, Simon; Huang, Bill; Earle, Sarah; Pankhurst, Louise J. et al. (21 December 2015). "Rapid antibiotic-resistance predictions from genome sequence data for Staphylococcus aureus and Mycobacterium tuberculosis". Nature Communications 6 (1): 10063. doi:10.1038/ncomms10063. PMID 26686880. Bibcode: 2015NatCo...610063B.
- ↑ "Michael Mosley vs the superbugs". https://www.tvo.org/transcript/115187X/michael-mosley-vs-the-superbugs.
- ↑ Mykrobe, Mykrobe-tools, 2022-12-24, https://github.com/Mykrobe-tools/mykrobe, retrieved 2023-01-02
- ↑ Curtis, Caitlin; Hereward, James (29 August 2017). "From the crime scene to the courtroom: the journey of a DNA sample". The Conversation. https://theconversation.com/from-the-crime-scene-to-the-courtroom-the-journey-of-a-dna-sample-82250.
- ↑ "High resolution crystal structures of T4 phage beta-glucosyltransferase: induced fit and effect of substrate and metal binding". Journal of Molecular Biology 311 (3): 569–77. August 2001. doi:10.1006/jmbi.2001.4905. PMID 11493010.
- ↑ "Amount and distribution of 5-methylcytosine in human DNA from different types of tissues of cells". Nucleic Acids Research 10 (8): 2709–21. April 1982. doi:10.1093/nar/10.8.2709. PMID 7079182.
- ↑ "5-Methylcytosine in eukaryotic DNA". Science 212 (4501): 1350–7. June 1981. doi:10.1126/science.6262918. PMID 6262918. Bibcode: 1981Sci...212.1350E.
- ↑ "Sensitive and specific single-molecule sequencing of 5-hydroxymethylcytosine". Nature Methods 9 (1): 75–7. November 2011. doi:10.1038/nmeth.1779. PMID 22101853.
- ↑ Czernecki, Dariusz; Bonhomme, Frédéric; Kaminski, Pierre-Alexandre; Delarue, Marc (5 August 2021). "Characterization of a triad of genes in cyanophage S-2L sufficient to replace adenine by 2-aminoadenine in bacterial DNA". Nature Communications 12 (1): 4710. doi:10.1038/s41467-021-25064-x. PMID 34354070. Bibcode: 2021NatCo..12.4710C.
- ↑ "The structure of DNA". Cold Spring Harb. Symp. Quant. Biol. 18: 123–31. 1953. doi:10.1101/SQB.1953.018.01.020. PMID 13168976.
- ↑ Marks, L.. "The path to DNA sequencing: The life and work of Frederick Sanger" (in en). http://www.whatisbiotechnology.org/exhibitions/sanger/path.
- ↑ "Nucleotide sequence of the gene coding for the bacteriophage MS2 coat protein". Nature 237 (5350): 82–8. May 1972. doi:10.1038/237082a0. PMID 4555447. Bibcode: 1972Natur.237...82J.
- ↑ "Complete nucleotide sequence of bacteriophage MS2 RNA: primary and secondary structure of the replicase gene". Nature 260 (5551): 500–7. April 1976. doi:10.1038/260500a0. PMID 1264203. Bibcode: 1976Natur.260..500F.
- ↑ "RNA sequencing: advances, challenges and opportunities". Nature Reviews Genetics 12 (2): 87–98. February 2011. doi:10.1038/nrg2934. PMID 21191423.
- ↑ "Ray Wu Faculty Profile". Cornell University. http://www.mbg.cornell.edu/faculty-staff/faculty/wu.cfm.
- ↑ "Chemical synthesis of a primer and its use in the sequence analysis of the lysozyme gene of bacteriophage T4". Proceedings of the National Academy of Sciences of the United States of America 71 (6): 2510–4. June 1974. doi:10.1073/pnas.71.6.2510. PMID 4526223. Bibcode: 1974PNAS...71.2510P.
- ↑ "Ray Wu as Fifth Business: Demonstrating Collective Memory in the History of DNA Sequencing". Studies in the History and Philosophy of Science. Part C 46: 1–14. June 2014. doi:10.1016/j.shpsc.2013.12.006. PMID 24565976.
- ↑ "Nucleotide sequence analysis of DNA". Nature New Biology 236 (68): 198–200. 1972. doi:10.1038/newbio236198a0. PMID 4553110.
- ↑ "Nucleotide sequence analysis of DNA. IX. Use of oligonucleotides of defined sequence as primers in DNA sequence analysis". Biochem. Biophys. Res. Commun. 48 (5): 1295–302. 1972. doi:10.1016/0006-291X(72)90852-2. PMID 4560009.
- ↑ "Nucleotide sequence analysis of DNA. XII. The chemical synthesis and sequence analysis of a dodecadeoxynucleotide which binds to the endolysin gene of bacteriophage lambda". Biochem. Biophys. Res. Commun. 55 (4): 1092–99. 1973. doi:10.1016/S0006-291X(73)80007-5. PMID 4358929.
- ↑ 37.0 37.1 "DNA sequencing with chain-terminating inhibitors". Proc. Natl. Acad. Sci. USA 74 (12): 5463–77. December 1977. doi:10.1073/pnas.74.12.5463. PMID 271968. Bibcode: 1977PNAS...74.5463S.
- ↑ 38.0 38.1 38.2 "A new method for sequencing DNA". Proc. Natl. Acad. Sci. USA 74 (2): 560–64. February 1977. doi:10.1073/pnas.74.2.560. PMID 265521. Bibcode: 1977PNAS...74..560M.
- ↑ Gilbert, W. DNA sequencing and gene structure. Nobel lecture, 8 December 1980.
- ↑ "The Nucleotide Sequence of the lac Operator". Proc. Natl. Acad. Sci. U.S.A. 70 (12): 3581–84. December 1973. doi:10.1073/pnas.70.12.3581. PMID 4587255. Bibcode: 1973PNAS...70.3581G.
- ↑ "Nucleotide sequence of bacteriophage phi X174 DNA". Nature 265 (5596): 687–95. February 1977. doi:10.1038/265687a0. PMID 870828. Bibcode: 1977Natur.265..687S.
- ↑ Marks, L.. "The next frontier: Human viruses" (in en). https://www.whatisbiotechnology.org/index.php/exhibitions/sanger/sequencing.
- ↑ "DNA sequencing with direct blotting electrophoresis". EMBO J 3 (12): 2905–09. 1984. doi:10.1002/j.1460-2075.1984.tb02230.x. PMID 6396083.
- ↑ United States Patent 4,631,122 (1986)
- ↑ "Complete DNA sequence of yeast chromosome II". EMBO J. 13 (24): 5795–809. 1994. doi:10.1002/j.1460-2075.1994.tb06923.x. PMID 7813418.
- ↑ "Fluorescence Detection in Automated DNA Sequence Analysis". Nature 321 (6071): 674–79. 12 June 1986. doi:10.1038/321674a0. PMID 3713851. Bibcode: 1986Natur.321..674S.
- ↑ "A system for rapid DNA sequencing with fluorescent chain-terminating dideoxynucleotides". Science 238 (4825): 336–41. 16 October 1987. doi:10.1126/science.2443975. PMID 2443975. Bibcode: 1987Sci...238..336P.
- ↑ "Complementary DNA sequencing: expressed sequence tags and human genome project". Science 252 (5013): 1651–56. June 1991. doi:10.1126/science.2047873. PMID 2047873. Bibcode: 1991Sci...252.1651A.
- ↑ "Whole-genome random sequencing and assembly of Haemophilus influenzae Rd". Science 269 (5223): 496–512. July 1995. doi:10.1126/science.7542800. PMID 7542800. Bibcode: 1995Sci...269..496F.
- ↑ "Initial sequencing and analysis of the human genome". Nature 409 (6822): 860–921. February 2001. doi:10.1038/35057062. PMID 11237011. Bibcode: 2001Natur.409..860L. https://deepblue.lib.umich.edu/bitstream/2027.42/62798/1/409860a0.pdf.
- ↑ "The sequence of the human genome". Science 291 (5507): 1304–51. February 2001. doi:10.1126/science.1058040. PMID 11181995. Bibcode: 2001Sci...291.1304V.
- ↑ Yang, Aimin; Zhang, Wei; Wang, Jiahao; Yang, Ke; Han, Yang; Zhang, Limin (2020). "Review on the Application of Machine Learning Algorithms in the Sequence Data Mining of DNA". Frontiers in Bioengineering and Biotechnology 8: 1032. doi:10.3389/fbioe.2020.01032. PMID 33015010.
- ↑ "Espacenet – Bibliographic data". http://worldwide.espacenet.com/publicationDetails/biblio?FT=D&date=19910516&DB=EPODOC&locale=en_EP&CC=WO&NR=9106678A1&KC=A1&ND=4.
- ↑ "Real-time DNA sequencing using detection of pyrophosphate release". Analytical Biochemistry 242 (1): 84–89. 1996. doi:10.1006/abio.1996.0432. PMID 8923969.
- ↑ 55.0 55.1 Kawashima, Eric H.; Laurent Farinelli (2005-05-12). "Patent: Method of nucleic acid amplification". http://www.patentlens.net/patentlens/patent/WO_1998_044151_A1/en/.
- ↑ "Base-calling of automated sequencer traces using phred. II. Error probabilities". Genome Res. 8 (3): 186–94. March 1998. doi:10.1101/gr.8.3.186. PMID 9521922.
- ↑ "Quality Scores for Next-Generation Sequencing". 31 October 2011. https://www.illumina.com/documents/products/technotes/technote_Q-Scores.pdf.
- ↑ 58.0 58.1 "Gene expression analysis by massively parallel signature sequencing (MPSS) on microbead arrays". Nature Biotechnology 18 (6): 630–34. 2000. doi:10.1038/76469. PMID 10835600.
- ↑ "maxam gilbert sequencing". https://pubmed.ncbi.nlm.nih.gov/?term=maxam+gilbert+sequencing&filter=years.2013-2023&sort=pubdate.
- ↑ "A rapid method for determining sequences in DNA by primed synthesis with DNA polymerase". J. Mol. Biol. 94 (3): 441–48. May 1975. doi:10.1016/0022-2836(75)90213-2. PMID 1100841.
- ↑ Wetterstrand, Kris. "DNA Sequencing Costs: Data from the NHGRI Genome Sequencing Program (GSP)". National Human Genome Research Institute. https://www.genome.gov/sequencingcosts.
- ↑ Nyren, P.; Pettersson, B.; Uhlen, M. (January 1993). "Solid Phase DNA Minisequencing by an Enzymatic Luminometric Inorganic Pyrophosphate Detection Assay". Analytical Biochemistry 208 (1): 171–175. doi:10.1006/abio.1993.1024. PMID 8382019.
- ↑ Ronaghi, Mostafa; Uhlén, Mathias; Nyrén, Pål (17 July 1998). "A Sequencing Method Based on Real-Time Pyrophosphate". Science 281 (5375): 363–365. doi:10.1126/science.281.5375.363. PMID 9705713.
- ↑ "Evaluation and optimisation of preparative semi-automated electrophoresis systems for Illumina library preparation". Electrophoresis 33 (23): 3521–28. 2012. doi:10.1002/elps.201200128. PMID 23147856.
- ↑ "Towards quantitative metagenomics of wild viruses and other ultra-low concentration DNA samples: a rigorous assessment and optimization of the linker amplification method". Environ. Microbiol. 14 (9): 2526–37. 2012. doi:10.1111/j.1462-2920.2012.02791.x. PMID 22713159. Bibcode: 2012EnvMi..14.2526D.
- ↑ "Double digest RADseq: an inexpensive method for de novo SNP discovery and genotyping in model and non-model species". PLOS ONE 7 (5): e37135. 2012. doi:10.1371/journal.pone.0037135. PMID 22675423. Bibcode: 2012PLoSO...737135P.
- ↑ "Amplification of complex gene libraries by emulsion PCR". Nature Methods 3 (7): 545–50. 2006. doi:10.1038/nmeth896. PMID 16791213.
- ↑ 68.0 68.1 "Genome Sequencing in Open Microfabricated High Density Picoliter Reactors". Nature 437 (7057): 376–80. September 2005. doi:10.1038/nature03959. PMID 16056220. Bibcode: 2005Natur.437..376M.
- ↑ "Accurate Multiplex Polony Sequencing of an Evolved Bacterial Genome". Science 309 (5741): 1728–32. 2005. doi:10.1126/science.1117389. PMID 16081699. Bibcode: 2005Sci...309.1728S.
- ↑ "Applied Biosystems – File Not Found (404 Error)". 16 May 2008. http://solid.appliedbiosystems.com/.
- ↑ "Coming of age: ten years of next-generation sequencing technologies". Nature Reviews Genetics 17 (6): 333–51. May 2016. doi:10.1038/nrg.2016.49. PMID 27184599.
- ↑ "A strategy of DNA sequencing employing computer programs.". Nucleic Acids Research 6 (7): 2601–10. 11 June 1979. doi:10.1093/nar/6.7.2601. PMID 461197.
- ↑ "Next-generation sequencing in aging research: emerging applications, problems, pitfalls and possible solutions". Ageing Research Reviews 9 (3): 315–23. 2010. doi:10.1016/j.arr.2009.10.006. PMID 19900591.
- ↑ "Next-generation sequencing: methodology and application". J Invest Dermatol 133 (8): e11. August 2013. doi:10.1038/jid.2013.248. PMID 23856935.
- ↑ "Advanced sequencing technologies and their wider impact in microbiology". J. Exp. Biol. 210 (Pt 9): 1518–25. May 2007. doi:10.1242/jeb.001370. PMID 17449817.
- ↑ "Genomes for all". Sci. Am. 294 (1): 46–54. January 2006. doi:10.1038/scientificamerican0106-46. PMID 16468433. Bibcode: 2006SciAm.294a..46C.(Subscription content?)
- ↑ 77.0 77.1 77.2 "Next-generation sequencing transforms today's biology". Nat. Methods 5 (1): 16–18. January 2008. doi:10.1038/nmeth1156. PMID 18165802.
- ↑ Kalb, Gilbert; Moxley, Robert (1992). Massively Parallel, Optical, and Neural Computing in the United States. IOS Press. ISBN 978-90-5199-097-3.[page needed]
- ↑ "Keeping Up with the Next Generation". The Journal of Molecular Diagnostics 10 (6): 484–92. 2008. doi:10.2353/jmoldx.2008.080027. PMID 18832462.
- ↑ "Massively Parallel Sequencing: The Next Big Thing in Genetic Medicine". The American Journal of Human Genetics 85 (2): 142–54. 2009. doi:10.1016/j.ajhg.2009.06.022. PMID 19679224.
- ↑ 81.0 81.1 "From Sanger sequencing to genome databases and beyond". BioTechniques (Future Science) 66 (2): 60–63. February 2019. doi:10.2144/btn-2019-0011. PMID 30744413.
- ↑ "A tale of three next generation sequencing platforms: comparison of Ion Torrent, Pacific Biosciences and illumina MiSeq sequencers". BMC Genomics 13 (1): 341. 1 January 2012. doi:10.1186/1471-2164-13-341. PMID 22827831.
- ↑ "Comparison of Next-Generation Sequencing Systems". Journal of Biomedicine and Biotechnology 2012: 251364. 1 January 2012. doi:10.1155/2012/251364. PMID 22829749.
- ↑ "New Software, Polymerase for Sequel System Boost Throughput and Affordability – PacBio". 7 March 2018. https://www.pacb.com/blog/new-software-polymerase-sequel-system-boost-throughput-affordability/.
- ↑ "After a Year of Testing, Two Early PacBio Customers Expect More Routine Use of RS Sequencer in 2012". GenomeWeb. 10 January 2012. http://www.genomeweb.com/sequencing/after-year-testing-two-early-pacbio-customers-expect-more-routine-use-rs-sequenc.(registration required)
- ↑ Inc., Pacific Biosciences (2013). "Pacific Biosciences Introduces New Chemistry With Longer Read Lengths to Detect Novel Features in DNA Sequence and Advance Genome Studies of Large Organisms" (Press release).
- ↑ "The methylomes of six bacteria". Nucleic Acids Research 40 (22): 11450–62. 2 October 2012. doi:10.1093/nar/gks891. PMID 23034806.
- ↑ "Ion 520 & Ion 530 ExT Kit-Chef – Thermo Fisher Scientific". https://www.thermofisher.com/order/catalog/product/A30670.
- ↑ "Raw accuracy". http://129.130.90.13/ion-docs/GUID-C6419130-57D8-4DE2-BCF8-47157CB3C9A2.html.
- ↑ "Next generation sequencing of microbial transcriptomes: challenges and opportunities". FEMS Microbiology Letters 302 (1): 1–7. 1 January 2010. doi:10.1111/j.1574-6968.2009.01767.x. PMID 19735299.
- ↑ "BGI and MGISEQ". http://en.mgitech.cn/product/30.html.
- ↑ 92.0 92.1 "Palindromic sequence impedes sequencing-by-ligation mechanism". BMC Systems Biology 6 (Suppl 2): S10. 2012. doi:10.1186/1752-0509-6-S2-S10. PMID 23281822.
- ↑ Loose, Matthew; Rakyan, Vardhman; Holmes, Nadine; Payne, Alexander (3 May 2018). "Whale watching with BulkVis: A graphical viewer for Oxford Nanopore bulk fast5 files". bioRxiv 10.1101/312256.
- ↑ Cite error: Invalid
<ref>tag; no text was provided for refs namedflxlexblog.wordpress.com - ↑ "PacBio Sales Start to Pick Up as Company Delivers on Product Enhancements". 12 February 2013. http://www.genomeweb.com/sequencing/pacbio-sales-start-pick-company-delivers-product-enhancements.
- ↑ "Bio-IT World". http://www.bio-itworld.com/2015/9/30/pacbio-announces-sequel-sequencing-system.aspx.
- ↑ "PacBio Launches Higher-Throughput, Lower-Cost Single-Molecule Sequencing System". October 2015. https://www.genomeweb.com/business-news/pacbio-launches-higher-throughput-lower-cost-single-molecule-sequencing-system.
- ↑ "Continuous base identification for single-molecule nanopore DNA sequencing". Nature Nanotechnology 4 (4): 265–70. April 2009. doi:10.1038/nnano.2009.12. PMID 19350039. Bibcode: 2009NatNa...4..265C.
- ↑ 99.0 99.1 "Fabrication and characterization of solid-state nanopore arrays for high-throughput DNA sequencing". Nanotechnology 23 (38): 385308. 2012. doi:10.1088/0957-4484/23/38/385308. PMID 22948520. Bibcode: 2012Nanot..23L5308D.
- ↑ 100.0 100.1 "Double-functionalized nanopore-embedded gold electrodes for rapid DNA sequencing". Applied Physics Letters 100 (2): 023701. 2012. doi:10.1063/1.3673335. Bibcode: 2012ApPhL.100b3701P. https://zenodo.org/record/890231.
- ↑ "Selective aluminum passivation for targeted immobilization of single DNA polymerase molecules in zero-mode waveguide nanostructures". Proceedings of the National Academy of Sciences 105 (4): 1176–81. 2008. doi:10.1073/pnas.0710982105. PMID 18216253. Bibcode: 2008PNAS..105.1176K.
- ↑ 102.0 102.1 "Accurate multiplex polony sequencing of an evolved bacterial genome.". Science 309 (5741): 1728–32. 9 September 2005. doi:10.1126/science.1117389. PMID 16081699. Bibcode: 2005Sci...309.1728S.
- ↑ "Accurate whole human genome sequencing using reversible terminator chemistry". Nature 456 (7218): 53–59. 2008. doi:10.1038/nature07517. PMID 18987734. Bibcode: 2008Natur.456...53B.
- ↑ Canard, Bruno; Sarfati, Simon (13 October 1994), Novel derivatives usable for the sequencing of nucleic acids, http://www.google.ge/patents/CA2158975A1, retrieved 2016-03-09
- ↑ "DNA polymerase fluorescent substrates with reversible 3'-tags". Gene 148 (1): 1–6. October 1994. doi:10.1016/0378-1119(94)90226-7. PMID 7523248.
- ↑ "Next-generation DNA sequencing methods". Annu Rev Genom Hum Genet 9: 387–402. 2008. doi:10.1146/annurev.genom.9.081307.164359. PMID 18576944.
- ↑ 107.0 107.1 107.2 "Human genome sequencing using unchained base reads on self-assembling DNA nanoarrays". Science 327 (5961): 78–81. January 2010. doi:10.1126/science.1181498. PMID 19892942. Bibcode: 2010Sci...327...78D.
- ↑ brandonvd. "About Us – Complete Genomics". http://www.completegenomics.com/.
- ↑ 109.0 109.1 "A reference human genome dataset of the BGISEQ-500 sequencer". GigaScience 6 (5): 1–9. May 2017. doi:10.1093/gigascience/gix024. PMID 28379488.
- ↑ "A high-resolution, nucleosome position map of C. elegans reveals a lack of universal sequence-dictated positioning". Genome Res. 18 (7): 1051–63. July 2008. doi:10.1101/gr.076463.108. PMID 18477713.
- ↑ "Torrents of sequence". Nat Methods 8 (1): 44. 2011. doi:10.1038/nmeth.f.330.
- ↑ 112.0 112.1 "Human Genome Sequencing Using Unchained Base Reads in Self-Assembling DNA Nanoarrays". Science 327 (5961): 78–81. 2010. doi:10.1126/science.1181498. PMID 19892942. Bibcode: 2010Sci...327...78D.
- ↑ "Genome Sequencing on Nanoballs". Nature Biotechnology 28 (1): 43–44. 2010. doi:10.1038/nbt0110-43. PMID 20062041.
- ↑ "HeliScope Gene Sequencing / Genetic Analyzer System : Helicos BioSciences". 2 November 2009. http://www.helicosbio.com/Products/HelicosregGeneticAnalysisSystem/HeliScopetradeSequencer/tabid/87/Default.aspx.
- ↑ "Single molecule sequencing with a HeliScope genetic analysis system". Current Protocols in Molecular Biology Chapter 7: Unit7.10. October 2010. doi:10.1002/0471142727.mb0710s92. PMID 20890904.
- ↑ "tSMS SeqLL Technical Explanation". SeqLL. http://seqll.com/technical-description/.
- ↑ Heather, James M.; Chain, Benjamin (January 2016). "The sequence of sequencers: The history of sequencing DNA". Genomics 107 (1): 1–8. doi:10.1016/j.ygeno.2015.11.003. PMID 26554401.
- ↑ Sara El-Metwally; Osama M. Ouda; Mohamed Helmy (2014). "New Horizons in Next-Generation Sequencing". Next Generation Sequencing Technologies and Challenges in Sequence Assembly. SpringerBriefs in Systems Biology. 7. Next Generation Sequencing Technologies and Challenges in Sequence Assembly, Springer Briefs in Systems Biology Volume 7. pp. 51–59. doi:10.1007/978-1-4939-0715-1_6. ISBN 978-1-4939-0714-4.
- ↑ 119.0 119.1 "Chemical and Biological Applications of Digital-Microfluidic Devices". IEEE Design & Test of Computers 24 (1): 10–24. January 2007. doi:10.1109/MDT.2007.8.
- ↑ 120.0 120.1 "Droplet-based pyrosequencing using digital microfluidics". Analytical Chemistry 83 (22): 8439–47. November 2011. doi:10.1021/ac201416j. PMID 21932784.
- ↑ "Single-cell barcoding and sequencing using droplet microfluidics". Nature Protocols 12 (1): 44–73. January 2017. doi:10.1038/nprot.2016.154. PMID 27929523.
- ↑ "The Harvard Nanopore Group". Mcb.harvard.edu. http://mcb.harvard.edu/branton/index.htm.
- ↑ "Nanopore Sequencing Could Slash DNA Analysis Costs". http://www.physorg.com/news157378086.html.
- ↑ US patent 20060029957, ZS Genetics, "Systems and methods of analyzing nucleic acid polymers and related components", issued 2005-07-14
- ↑ "Perspectives and challenges of emerging single-molecule DNA sequencing technologies". Small 5 (23): 2638–49. December 2009. doi:10.1002/smll.200900976. PMID 19904762.
- ↑ "A window into third-generation sequencing". Human Molecular Genetics 19 (R2): R227–40. 2010. doi:10.1093/hmg/ddq416. PMID 20858600.
- ↑ "The electronic properties of DNA bases". Small 3 (9): 1539–43. 2007. doi:10.1002/smll.200600732. PMID 17786897.
- ↑ "Fast DNA sequencing by electrical means inches closer". Nanotechnology 24 (34): 342501. 2013. doi:10.1088/0957-4484/24/34/342501. PMID 23899780. Bibcode: 2013Nanot..24H2501D. https://zenodo.org/record/896777.
- ↑ "Single-molecule electrical random resequencing of DNA and RNA". Sci Rep 2: 501. 2012. doi:10.1038/srep00501. PMID 22787559. Bibcode: 2012NatSR...2E.501O.
- ↑ "Comparison of Sequencing by Hybridization and Cycle Sequencing for Genotyping of Human Immunodeficiency Virus Type 1 Reverse Transcriptase". J. Clin. Microbiol. 38 (7): 2715–21. 1 July 2000. doi:10.1128/JCM.38.7.2715-2721.2000. PMID 10878069.
- ↑ 131.0 131.1 "A glimpse into past, present, and future DNA sequencing". Molecular Genetics and Metabolism 110 (1–2): 3–24. 2013. doi:10.1016/j.ymgme.2013.04.024. PMID 23742747.
- ↑ Gibas, Cynthia, ed (2012). "Sequencing by Hybridization of Long Targets". PLOS ONE 7 (5): e35819. doi:10.1371/journal.pone.0035819. PMID 22574124. Bibcode: 2012PLoSO...735819Q.
- ↑ "Mass-spectrometry DNA sequencing". Mutation Research 573 (1–2): 3–12. 2005. doi:10.1016/j.mrfmmm.2004.07.021. PMID 15829234.
- ↑ "Base composition analysis of human mitochondrial DNA using electrospray ionization mass spectrometry: A novel tool for the identification and differentiation of humans". Analytical Biochemistry 344 (1): 53–69. 2005. doi:10.1016/j.ab.2005.05.028. PMID 16054106.
- ↑ "Comparative analysis of human mitochondrial DNA from World War I bone samples by DNA sequencing and ESI-TOF mass spectrometry". Forensic Science International: Genetics 7 (1): 1–9. 15 June 2011. doi:10.1016/j.fsigen.2011.05.009. PMID 21683667.
- ↑ "High-throughput DNA analysis by time-of-flight mass spectrometry". Nature Medicine 3 (3): 360–62. 1 March 1997. doi:10.1038/nm0397-360. PMID 9055869.
- ↑ "Molecular complexity of successive bacterial epidemics deconvoluted by comparative pathogenomics". Proceedings of the National Academy of Sciences 107 (9): 4371–76. 8 February 2010. doi:10.1073/pnas.0911295107. PMID 20142485. Bibcode: 2010PNAS..107.4371B.
- ↑ "DNA sequencing and genotyping in miniaturized electrophoresis systems". Electrophoresis 25 (21–22): 3564–88. 1 November 2004. doi:10.1002/elps.200406161. PMID 15565709.
- ↑ "DNA sequencing by denaturation: experimental proof of concept with an integrated fluidic device". Lab on a Chip 10 (9): 1153–59. 2010. doi:10.1039/b921417h. PMID 20390134.
- ↑ "DNA Base Identification by Electron Microscopy". Microscopy and Microanalysis 18 (5): 1049–53. 9 October 2012. doi:10.1017/S1431927612012615. PMID 23046798. Bibcode: 2012MiMic..18.1049B.
- ↑ "Sequencing technologies and genome sequencing". Journal of Applied Genetics 52 (4): 413–35. November 2011. doi:10.1007/s13353-011-0057-x. PMID 21698376.
- ↑ "Sequencing technologies and genome sequencing". Journal of Applied Genetics 52 (4): 413–35. 2011. doi:10.1007/s13353-011-0057-x. PMID 21698376.
- ↑ "Next-generation sequencing coupled with a cell-free display technology for high-throughput production of reliable interactome data". Scientific Reports 2: 691. 2012. doi:10.1038/srep00691. PMID 23056904. Bibcode: 2012NatSR...2E.691F.
- ↑ "2022 Sequencing Market Share – Same as It Ever Was (For Now)". 25 June 2023. https://sandiegomics.com/2022-sequencing-market-share-same-as-it-ever-was-for-now/.
- ↑ "The Current Status of cDNA Cloning". Genomics 91 (3): 232–42. 2008. doi:10.1016/j.ygeno.2007.11.004. PMID 18222633.
- ↑ "Comparison of Library Preparation Methods Reveals Their Impact on Interpretation of Metatranscriptomic Data". BMC Genomics 15 (1): 912–12. 2014. doi:10.1186/1471-2164-15-912. PMID 25331572.
- ↑ "Scalable Nucleic Acid Quality Assessments for Illumina Next-Generation Sequencing Library Prep". https://www.illumina.com/content/dam/illumina-marketing/documents/products/appnotes/library-qc-fragment-analyzer-application-note-770-2017-002.pdf.
- ↑ "Archon Genomics XPRIZE". http://genomics.xprize.org/.
- ↑ "Grant Information". http://www.genome.gov/10000004.
- ↑ "Interactive visualization and analysis of large-scale sequencing datasets using ZENBU". Nat. Biotechnol. 32 (3): 217–19. 2014. doi:10.1038/nbt.2840. PMID 24727769.
- ↑ "Using a VOM model for reconstructing potential coding regions in EST sequences". Computational Statistics 22 (1): 49–69. 2007. doi:10.1007/s00180-007-0021-8. http://www.eng.tau.ac.il/~bengal/VOM_EST.pdf. Retrieved 10 January 2014.
- ↑ "An Extensive Evaluation of Read Trimming Effects on Illumina NGS Data Analysis". PLOS ONE 8 (12): e85024. 2013. doi:10.1371/journal.pone.0085024. PMID 24376861. Bibcode: 2013PLoSO...885024D.
- ↑ Martin, Marcel (2 May 2011). "Cutadapt removes adapter sequences from high-throughput sequencing reads". EMBnet.journal 17 (1): 10. doi:10.14806/ej.17.1.200.
- ↑ "ConDeTri--a content dependent read trimmer for Illumina data". PLOS ONE 6 (10): e26314. 19 October 2011. doi:10.1371/journal.pone.0026314. PMID 22039460. Bibcode: 2011PLoSO...626314S.
- ↑ "Erne-Bs5". Proceedings of the ACM Conference on Bioinformatics, Computational Biology and Biomedicine. 12. 2012. pp. 12–19. doi:10.1145/2382936.2382938. ISBN 9781450316705.
- ↑ "Quality control and preprocessing of metagenomic datasets". Bioinformatics 27 (6): 863–4. March 2011. doi:10.1093/bioinformatics/btr026. PMID 21278185.
- ↑ "Trimmomatic: a flexible trimmer for Illumina sequence data". Bioinformatics 30 (15): 2114–20. August 2014. doi:10.1093/bioinformatics/btu170. PMID 24695404.
- ↑ "SolexaQA: At-a-glance quality assessment of Illumina second-generation sequencing data". BMC Bioinformatics 11 (1): 485. September 2010. doi:10.1186/1471-2105-11-485. PMID 20875133.
- ↑ "Ethical issues in human genome research". FASEB Journal 5 (1): 55–60. January 1991. doi:10.1096/fasebj.5.1.1825074. PMID 1825074.
- ↑ 160.0 160.1 160.2 "The $1000 genome: ethical and legal issues in whole genome sequencing of individuals". The American Journal of Bioethics 3 (3): W–IF1. August 2003. doi:10.1162/152651603322874762. PMID 14735880.
- ↑ 161.0 161.1 Henderson, Mark (2013-09-09). "Human genome sequencing: the real ethical dilemmas". The Guardian. https://www.theguardian.com/science/2013/sep/09/genetics-ethics-human-gene-sequencing.
- ↑ Harmon, Amy (24 February 2008). "Insurance Fears Lead Many to Shun DNA Tests". https://www.nytimes.com/2008/02/24/health/24dna.html?pagewanted=all&_r=0.
- ↑ Statement of Administration policy, Executive Office of the President, Office of Management and Budget, 27 April 2007
- ↑ National Human Genome Research Institute (21 May 2008). "President Bush Signs the Genetic Information Nondiscrimination Act of 2008". http://www.genome.gov/27026050.
- ↑ Baker, Monya (11 October 2012). "US ethics panel reports on DNA sequencing and privacy". Nature News Blog. https://blogs.nature.com/news/2012/10/us-ethics-panel-reports-on-dna-sequencing-and-privacy.html.
- ↑ "Privacy and Progress in Whole Genome Sequencing". Presidential Commission for the Study of Bioethical Issues. http://bioethics.gov/sites/default/files/PrivacyProgress508_1.pdf.
- ↑ Hartnett, Kevin (2013-05-12). "The DNA in your garbage: up for grabs" (in en-US). https://www.bostonglobe.com/ideas/2013/05/11/the-dna-your-garbage-for-grabs/sU12MtVLkoypL1qu2iF6IL/story.html.
- ↑ "The ethical hazards and programmatic challenges of genomic newborn screening". JAMA 307 (5): 461–2. February 2012. doi:10.1001/jama.2012.68. PMID 22298675.
- ↑ Hughes, Virginia (2013-01-07). "It's Time To Stop Obsessing About the Dangers of Genetic Information". http://www.slate.com/articles/health_and_science/medical_examiner/2013/01/ethics_of_genetic_information_whole_genome_sequencing_is_here_and_we_need.html.
- ↑ 170.0 170.1 "Effect of direct-to-consumer genomewide profiling to assess disease risk". The New England Journal of Medicine 364 (6): 524–34. February 2011. doi:10.1056/NEJMoa1011893. PMID 21226570.
- ↑ Rochman, Bonnie (25 October 2012). "What Your Doctor Isn't Telling You About Your DNA". http://healthland.time.com/2012/10/25/what-your-doctor-isnt-telling-you-about-your-dna/.
- ↑ Sajeer P, Muhammad (4 May 2023). "Disruptive technology: Exploring the ethical, legal, political, and societal implications of nanopore sequencing technology". EMBO Reports 24 (5): e56619. doi:10.15252/embr.202256619. PMID 36988424.
External links
| Library resources about DNA sequencing |
| Wikibooks has a book on the topic of: Next Generation Sequencing (NGS) |
- A wikibook on next generation sequencing
 |  |

