Biology:DNA polymerase
| DNA-directed DNA polymerase | |||||||||
|---|---|---|---|---|---|---|---|---|---|
 3D structure of the DNA-binding helix-turn-helix motifs in human DNA polymerase beta (based on PDB file 7ICG) | |||||||||
| Identifiers | |||||||||
| EC number | 2.7.7.7 | ||||||||
| CAS number | 9012-90-2 | ||||||||
| Databases | |||||||||
| IntEnz | IntEnz view | ||||||||
| BRENDA | BRENDA entry | ||||||||
| ExPASy | NiceZyme view | ||||||||
| KEGG | KEGG entry | ||||||||
| MetaCyc | metabolic pathway | ||||||||
| PRIAM | profile | ||||||||
| PDB structures | RCSB PDB PDBe PDBsum | ||||||||
| Gene Ontology | AmiGO / QuickGO | ||||||||
| |||||||||
A DNA polymerase is a member of a family of enzymes that catalyze the synthesis of DNA molecules from nucleoside triphosphates, the molecular precursors of DNA. These enzymes are essential for DNA replication and usually work in groups to create two identical DNA duplexes from a single original DNA duplex. During this process, DNA polymerase "reads" the existing DNA strands to create two new strands that match the existing ones.[1][2][3][4][5][6] These enzymes catalyze the chemical reaction
- deoxynucleoside triphosphate + DNAn ⇌ pyrophosphate + DNAn+1.
DNA polymerase adds nucleotides to the three prime (3')-end of a DNA strand, one nucleotide at a time. Every time a cell divides, DNA polymerases are required to duplicate the cell's DNA, so that a copy of the original DNA molecule can be passed to each daughter cell. In this way, genetic information is passed down from generation to generation.
Before replication can take place, an enzyme called helicase unwinds the DNA molecule from its tightly woven form, in the process breaking the hydrogen bonds between the nucleotide bases. This opens up or "unzips" the double-stranded DNA to give two single strands of DNA that can be used as templates for replication in the above reaction.
History
In 1956, Arthur Kornberg and colleagues discovered DNA polymerase I (Pol I), in Escherichia coli. They described the DNA replication process by which DNA polymerase copies the base sequence of a template DNA strand. Kornberg was later awarded the Nobel Prize in Physiology or Medicine in 1959 for this work.[7] DNA polymerase II was discovered by Thomas Kornberg (the son of Arthur Kornberg) and Malcolm E. Gefter in 1970 while further elucidating the role of Pol I in E. coli DNA replication.[8] Three more DNA polymerases have been found in E. coli, including DNA polymerase III (discovered in the 1970s) and DNA polymerases IV and V (discovered in 1999).[9]
Function


The main function of DNA polymerase is to synthesize DNA from deoxyribonucleotides, the building blocks of DNA. The DNA copies are created by the pairing of nucleotides to bases present on each strand of the original DNA molecule. This pairing always occurs in specific combinations, with cytosine along with guanine, and thymine along with adenine, forming two separate pairs, respectively. By contrast, RNA polymerases synthesize RNA from ribonucleotides from either RNA or DNA.[citation needed]
When synthesizing new DNA, DNA polymerase can add free nucleotides only to the 3' end of the newly forming strand. This results in elongation of the newly forming strand in a 5'–3' direction.[citation needed]
It is important to note that the directionality of the newly forming strand (the daughter strand) is opposite to the direction in which DNA polymerase moves along the template strand. Since DNA polymerase requires a free 3' OH group for initiation of synthesis, it can synthesize in only one direction by extending the 3' end of the preexisting nucleotide chain. Hence, DNA polymerase moves along the template strand in a 3'–5' direction, and the daughter strand is formed in a 5'–3' direction. This difference enables the resultant double-strand DNA formed to be composed of two DNA strands that are antiparallel to each other.[citation needed]
The function of DNA polymerase is not quite perfect, with the enzyme making about one mistake for every billion base pairs copied. Error correction is a property of some, but not all DNA polymerases. This process corrects mistakes in newly synthesized DNA. When an incorrect base pair is recognized, DNA polymerase moves backwards by one base pair of DNA. The 3'–5' exonuclease activity of the enzyme allows the incorrect base pair to be excised (this activity is known as proofreading). Following base excision, the polymerase can re-insert the correct base and replication can continue forwards. This preserves the integrity of the original DNA strand that is passed onto the daughter cells.
Fidelity is very important in DNA replication. Mismatches in DNA base pairing can potentially result in dysfunctional proteins and could lead to cancer. Many DNA polymerases contain an exonuclease domain, which acts in detecting base pair mismatches and further performs in the removal of the incorrect nucleotide to be replaced by the correct one.[10] The shape and the interactions accommodating the Watson and Crick base pair are what primarily contribute to the detection or error. Hydrogen bonds play a key role in base pair binding and interaction. The loss of an interaction, which occurs at a mismatch, is said to trigger a shift in the balance, for the binding of the template-primer, from the polymerase, to the exonuclease domain. In addition, an incorporation of a wrong nucleotide causes a retard in DNA polymerization. This delay gives time for the DNA to be switched from the polymerase site to the exonuclease site. Different conformational changes and loss of interaction occur at different mismatches. In a purine:pyrimidine mismatch there is a displacement of the pyrimidine towards the major groove and the purine towards the minor groove. Relative to the shape of DNA polymerase's binding pocket, steric clashes occur between the purine and residues in the minor groove, and important van der Waals and electrostatic interactions are lost by the pyrimidine.[11] Pyrimidine:pyrimidine and purine:purine mismatches present less notable changes since the bases are displaced towards the major groove, and less steric hindrance is experienced. However, although the different mismatches result in different steric properties, DNA polymerase is still able to detect and differentiate them so uniformly and maintain fidelity in DNA replication.[12] DNA polymerization is also critical for many mutagenesis processes and is widely employed in biotechnologies.
Structure
The known DNA polymerases have highly conserved structure, which means that their overall catalytic subunits vary very little from species to species, independent of their domain structures. Conserved structures usually indicate important, irreplaceable functions of the cell, the maintenance of which provides evolutionary advantages. The shape can be described as resembling a right hand with thumb, finger, and palm domains. The palm domain appears to function in catalyzing the transfer of phosphoryl groups in the phosphoryl transfer reaction. DNA is bound to the palm when the enzyme is active. This reaction is believed to be catalyzed by a two-metal-ion mechanism. The finger domain functions to bind the nucleoside triphosphates with the template base. The thumb domain plays a potential role in the processivity, translocation, and positioning of the DNA.[13]
Processivity
DNA polymerase's rapid catalysis is due to its processive nature. Processivity is a characteristic of enzymes that function on polymeric substrates. In the case of DNA polymerase, the degree of processivity refers to the average number of nucleotides added each time the enzyme binds a template. The average DNA polymerase requires about one second locating and binding a primer/template junction. Once it is bound, a nonprocessive DNA polymerase adds nucleotides at a rate of one nucleotide per second.[14]: 207–208 Processive DNA polymerases, however, add multiple nucleotides per second, drastically increasing the rate of DNA synthesis. The degree of processivity is directly proportional to the rate of DNA synthesis. The rate of DNA synthesis in a living cell was first determined as the rate of phage T4 DNA elongation in phage infected E. coli. During the period of exponential DNA increase at 37 °C, the rate was 749 nucleotides per second.[15]
DNA polymerase's ability to slide along the DNA template allows increased processivity. There is a dramatic increase in processivity at the replication fork. This increase is facilitated by the DNA polymerase's association with proteins known as the sliding DNA clamp. The clamps are multiple protein subunits associated in the shape of a ring. Using the hydrolysis of ATP, a class of proteins known as the sliding clamp loading proteins open up the ring structure of the sliding DNA clamps allowing binding to and release from the DNA strand. Protein–protein interaction with the clamp prevents DNA polymerase from diffusing from the DNA template, thereby ensuring that the enzyme binds the same primer/template junction and continues replication.[14]: 207–208 DNA polymerase changes conformation, increasing affinity to the clamp when associated with it and decreasing affinity when it completes the replication of a stretch of DNA to allow release from the clamp.[citation needed]
DNA polymerase processivity has been studied with in vitro single-molecule experiments (namely, optical tweezers and magnetic tweezers) have revealed the synergies between DNA polymerases and other molecules of the replisome (helicases and SSBs) and with the DNA replication fork.[16] These results have lead to the developement of synergetic kinetic models for DNA replication describing the resulting DNA polymerase processivity increase.[16]
Variation across species
| DNA polymerase family A | |||||||||
|---|---|---|---|---|---|---|---|---|---|
 c:o6-methyl-guanine pair in the polymerase-2 basepair position | |||||||||
| Identifiers | |||||||||
| Symbol | DNA_pol_A | ||||||||
| Pfam | PF00476 | ||||||||
| InterPro | IPR001098 | ||||||||
| SMART | - | ||||||||
| PROSITE | PDOC00412 | ||||||||
| SCOP2 | 1dpi / SCOPe / SUPFAM | ||||||||
| |||||||||
| DNA polymerase family B | |||||||||
|---|---|---|---|---|---|---|---|---|---|
 crystal structure of rb69 gp43 in complex with dna containing thymine glycol | |||||||||
| Identifiers | |||||||||
| Symbol | DNA_pol_B | ||||||||
| Pfam | PF00136 | ||||||||
| Pfam clan | CL0194 | ||||||||
| InterPro | IPR006134 | ||||||||
| PROSITE | PDOC00107 | ||||||||
| SCOP2 | 1noy / SCOPe / SUPFAM | ||||||||
| |||||||||
| DNA polymerase type B, organellar and viral | |||||||||
|---|---|---|---|---|---|---|---|---|---|
 phi29 dna polymerase, orthorhombic crystal form, ssdna complex | |||||||||
| Identifiers | |||||||||
| Symbol | DNA_pol_B_2 | ||||||||
| Pfam | PF03175 | ||||||||
| Pfam clan | CL0194 | ||||||||
| InterPro | IPR004868 | ||||||||
| |||||||||
Based on sequence homology, DNA polymerases can be further subdivided into seven different families: A, B, C, D, X, Y, and RT.
Some viruses also encode special DNA polymerases, such as Hepatitis B virus DNA polymerase. These may selectively replicate viral DNA through a variety of mechanisms. Retroviruses encode an unusual DNA polymerase called reverse transcriptase, which is an RNA-dependent DNA polymerase (RdDp). It polymerizes DNA from a template of RNA.
| Family[17] | Types of DNA polymerase | Taxa | Examples | Feature |
|---|---|---|---|---|
| A | Replicative and Repair Polymerases | Eukaryotic and Prokaryotic | T7 DNA polymerase, Pol I, Pol γ, θ, and ν | Two exonuclease domains (3'-5' and 5'-3') |
| B | Replicative and Repair Polymerases | Eukaryotic and Prokaryotic | Pol II, Pol B, Pol ζ, Pol α, δ, and ε | 3'-5 exonuclease (proofreading); some viral polymerases use protein primers |
| C | Replicative Polymerases | Prokaryotic | Pol III | 3'-5 exonuclease (proofreading) |
| D | Replicative Polymerases | Euryarchaeota | PolD (DP1/DP2 heterodimer)[18] | No "hand" feature, double barrel RNA polymerase-like; 3'-5 exonuclease (proofreading) |
| X | Replicative and Repair Polymerases | Eukaryotic | Pol β, Pol σ, Pol λ, Pol μ, and terminal deoxynucleotidyl transferase | template optional; 5' phosphatase (only Pol β); weak "hand" feature |
| Y | Replicative and Repair Polymerases | Eukaryotic and Prokaryotic | Pol ι, Pol κ, Pol η,[19] Pol IV, and Pol V | Translesion synthesis[20] |
| RT | Replicative and Repair Polymerases | Viruses, Retroviruses, and Eukaryotic | Telomerase, Hepatitis B virus | RNA-dependent |
Prokaryotic polymerase
Prokaryotic polymerases exist in two forms: core polymerase and holoenzyme. Core polymerase synthesizes DNA from the DNA template but it cannot initiate the synthesis alone or accurately. Holoenzyme accurately initiates synthesis.
Pol I
Prokaryotic family A polymerases include the DNA polymerase I (Pol I) enzyme, which is encoded by the polA gene and ubiquitous among prokaryotes. This repair polymerase is involved in excision repair with both 3'–5' and 5'–3' exonuclease activity and processing of Okazaki fragments generated during lagging strand synthesis.[21] Pol I is the most abundant polymerase, accounting for >95% of polymerase activity in E. coli; yet cells lacking Pol I have been found suggesting Pol I activity can be replaced by the other four polymerases. Pol I adds ~15-20 nucleotides per second, thus showing poor processivity. Instead, Pol I starts adding nucleotides at the RNA primer:template junction known as the origin of replication (ori). Approximately 400 bp downstream from the origin, the Pol III holoenzyme is assembled and takes over replication at a highly processive speed and nature.[22]
Taq polymerase is a heat-stable enzyme of this family that lacks proofreading ability.[23]
Pol II
DNA polymerase II is a family B polymerase encoded by the polB gene. Pol II has 3'–5' exonuclease activity and participates in DNA repair, replication restart to bypass lesions, and its cell presence can jump from ~30-50 copies per cell to ~200–300 during SOS induction. Pol II is also thought to be a backup to Pol III as it can interact with holoenzyme proteins and assume a high level of processivity. The main role of Pol II is thought to be the ability to direct polymerase activity at the replication fork and help stalled Pol III bypass terminal mismatches.[24]
Pfu DNA polymerase is a heat-stable enzyme of this family found in the hyperthermophilic archaeon Pyrococcus furiosus.[25] Detailed classification divides family B in archaea into B1, B2, B3, in which B2 is a group of pseudoenzymes. Pfu belongs to family B3. Others PolBs found in archaea are part of "Casposons", Cas1-dependent transposons.[26] Some viruses (including Φ29 DNA polymerase) and mitochondrial plasmids carry polB as well.[27]
Pol III
DNA polymerase III holoenzyme is the primary enzyme involved in DNA replication in E. coli and belongs to family C polymerases. It consists of three assemblies: the pol III core, the beta sliding clamp processivity factor, and the clamp-loading complex. The core consists of three subunits: α, the polymerase activity hub, ɛ, exonucleolytic proofreader, and θ, which may act as a stabilizer for ɛ. The beta sliding clamp processivity factor is also present in duplicate, one for each core, to create a clamp that encloses DNA allowing for high processivity.[28] The third assembly is a seven-subunit (τ2γδδ′χψ) clamp loader complex.
The old textbook "trombone model" depicts an elongation complex with two equivalents of the core enzyme at each replication fork (RF), one for each strand, the lagging and leading.[24] However, recent evidence from single-molecule studies indicates an average of three stoichiometric equivalents of core enzyme at each RF for both Pol III and its counterpart in B. subtilis, PolC.[29] In-cell fluorescent microscopy has revealed that leading strand synthesis may not be completely continuous, and Pol III* (i.e., the holoenzyme α, ε, τ, δ and χ subunits without the ß2 sliding clamp) has a high frequency of dissociation from active RFs.[30] In these studies, the replication fork turnover rate was about 10s for Pol III*, 47s for the ß2 sliding clamp, and 15m for the DnaB helicase. This suggests that the DnaB helicase may remain stably associated at RFs and serve as a nucleation point for the competent holoenzyme. In vitro single-molecule studies have shown that Pol III* has a high rate of RF turnover when in excess, but remains stably associated with replication forks when concentration is limiting.[30] Another single-molecule study showed that DnaB helicase activity and strand elongation can proceed with decoupled, stochastic kinetics.[30]
Pol IV
In E. coli, DNA polymerase IV (Pol IV) is an error-prone DNA polymerase involved in non-targeted mutagenesis.[31] Pol IV is a Family Y polymerase expressed by the dinB gene that is switched on via SOS induction caused by stalled polymerases at the replication fork. During SOS induction, Pol IV production is increased tenfold and one of the functions during this time is to interfere with Pol III holoenzyme processivity. This creates a checkpoint, stops replication, and allows time to repair DNA lesions via the appropriate repair pathway.[32] Another function of Pol IV is to perform translesion synthesis at the stalled replication fork like, for example, bypassing N2-deoxyguanine adducts at a faster rate than transversing undamaged DNA. Cells lacking the dinB gene have a higher rate of mutagenesis caused by DNA damaging agents.[33]
Pol V
DNA polymerase V (Pol V) is a Y-family DNA polymerase that is involved in SOS response and translesion synthesis DNA repair mechanisms.[34] Transcription of Pol V via the umuDC genes is highly regulated to produce only Pol V when damaged DNA is present in the cell generating an SOS response. Stalled polymerases causes RecA to bind to the ssDNA, which causes the LexA protein to autodigest. LexA then loses its ability to repress the transcription of the umuDC operon. The same RecA-ssDNA nucleoprotein posttranslationally modifies the UmuD protein into UmuD' protein. UmuD and UmuD' form a heterodimer that interacts with UmuC, which in turn activates umuC's polymerase catalytic activity on damaged DNA.[35] In E. coli, a polymerase "tool belt" model for switching pol III with pol IV at a stalled replication fork, where both polymerases bind simultaneously to the β-clamp, has been proposed.[36] However, the involvement of more than one TLS polymerase working in succession to bypass a lesion has not yet been shown in E. coli. Moreover, Pol IV can catalyze both insertion and extension with high efficiency, whereas pol V is considered the major SOS TLS polymerase. One example is the bypass of intra strand guanine thymine cross-link where it was shown on the basis of the difference in the mutational signatures of the two polymerases, that pol IV and pol V compete for TLS of the intra-strand crosslink.[36]
Family D
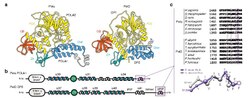
In 1998, the family D of DNA polymerase was discovered in Pyrococcus furiosus and Methanococcus jannaschii.[38] The PolD complex is a heterodimer of two chains, each encoded by DP1 (small proofreading) and DP2 (large catalytic). Unlike other DNA polymerases, the structure and mechanism of the DP2 catalytic core resemble that of multi-subunit RNA polymerases. The DP1-DP2 interface resembles that of Eukaryotic Class B polymerase zinc finger and its small subunit.[18] DP1, a Mre11-like exonuclease,[39] is likely the precursor of small subunit of Pol α and ε, providing proofreading capabilities now lost in Eukaryotes.[26] Its N-terminal HSH domain is similar to AAA proteins, especially Pol III subunit δ and RuvB, in structure.[40] DP2 has a Class II KH domain.[18] Pyrococcus abyssi polD is more heat-stable and more accurate than Taq polymerase, but has not yet been commercialized.[41] It has been proposed that family D DNA polymerase was the first to evolve in cellular organisms and that the replicative polymerase of the Last Universal Cellular Ancestor (LUCA) belonged to family D.[42]
Eukaryotic DNA polymerase
Polymerases β, λ, σ, μ (beta, lambda, sigma, mu) and TdT
Family X polymerases contain the well-known eukaryotic polymerase pol β (beta), as well as other eukaryotic polymerases such as Pol σ (sigma), Pol λ (lambda), Pol μ (mu), and Terminal deoxynucleotidyl transferase (TdT). Family X polymerases are found mainly in vertebrates, and a few are found in plants and fungi. These polymerases have highly conserved regions that include two helix-hairpin-helix motifs that are imperative in the DNA-polymerase interactions. One motif is located in the 8 kDa domain that interacts with downstream DNA and one motif is located in the thumb domain that interacts with the primer strand. Pol β, encoded by POLB gene, is required for short-patch base excision repair, a DNA repair pathway that is essential for repairing alkylated or oxidized bases as well as abasic sites. Pol λ and Pol μ, encoded by the POLL and POLM genes respectively, are involved in non-homologous end-joining, a mechanism for rejoining DNA double-strand breaks due to hydrogen peroxide and ionizing radiation, respectively. TdT is expressed only in lymphoid tissue, and adds "n nucleotides" to double-strand breaks formed during V(D)J recombination to promote immunological diversity.[43]
Polymerases α, δ and ε (alpha, delta, and epsilon)
Pol α (alpha), Pol δ (delta), and Pol ε (epsilon) are members of Family B Polymerases and are the main polymerases involved with nuclear DNA replication. Pol α complex (pol α-DNA primase complex) consists of four subunits: the catalytic subunit POLA1, the regulatory subunit POLA2, and the small and the large primase subunits PRIM1 and PRIM2 respectively. Once primase has created the RNA primer, Pol α starts replication elongating the primer with ~20 nucleotides.[44] Due to its high processivity, Pol δ takes over the leading and lagging strand synthesis from Pol α.[14]: 218–219 Pol δ is expressed by genes POLD1, creating the catalytic subunit, POLD2, POLD3, and POLD4 creating the other subunits that interact with Proliferating Cell Nuclear Antigen (PCNA), which is a DNA clamp that allows Pol δ to possess processivity.[45] Pol ε is encoded by the POLE1, the catalytic subunit, POLE2, and POLE3 gene. It has been reported that the function of Pol ε is to extend the leading strand during replication,[46][47] while Pol δ primarily replicates the lagging strand; however, recent evidence suggested that Pol δ might have a role in replicating the leading strand of DNA as well.[48] Pol ε's C-terminus "polymerase relic" region, despite being unnecessary for polymerase activity,[49] is thought to be essential to cell vitality. The C-terminus region is thought to provide a checkpoint before entering anaphase, provide stability to the holoenzyme, and add proteins to the holoenzyme necessary for initiation of replication.[50] Pol ε has a larger "palm" domain that provides high processivity independently of PCNA.[49]
Compared to other Family B polymerases, the DEDD exonuclease family responsible for proofreading is inactivated in Pol α.[26] Pol ε is unique in that it has two zinc finger domains and an inactive copy of another family B polymerase in its C-terminal. The presence of this zinc finger has implications in the origins of Eukaryota, which in this case is placed into the Asgard group with archaeal B3 polymerase.[51]
Polymerases η, ι and κ (eta, iota, and kappa)
Pol η (eta), Pol ι (iota), and Pol κ (kappa), are Family Y DNA polymerases involved in the DNA repair by translation synthesis and encoded by genes POLH, POLI, and POLK respectively. Members of Family Y have five common motifs to aid in binding the substrate and primer terminus and they all include the typical right hand thumb, palm and finger domains with added domains like little finger (LF), polymerase-associated domain (PAD), or wrist. The active site, however, differs between family members due to the different lesions being repaired. Polymerases in Family Y are low-fidelity polymerases, but have been proven to do more good than harm as mutations that affect the polymerase can cause various diseases, such as skin cancer and Xeroderma Pigmentosum Variant (XPS). The importance of these polymerases is evidenced by the fact that gene encoding DNA polymerase η is referred as XPV, because loss of this gene results in the disease Xeroderma Pigmentosum Variant. Pol η is particularly important for allowing accurate translesion synthesis of DNA damage resulting from ultraviolet radiation. The functionality of Pol κ is not completely understood, but researchers have found two probable functions. Pol κ is thought to act as an extender or an inserter of a specific base at certain DNA lesions. All three translesion synthesis polymerases, along with Rev1, are recruited to damaged lesions via stalled replicative DNA polymerases. There are two pathways of damage repair leading researchers to conclude that the chosen pathway depends on which strand contains the damage, the leading or lagging strand.[52]
Polymerases Rev1 and ζ (zeta)
Pol ζ another B family polymerase, is made of two subunits Rev3, the catalytic subunit, and Rev7 (MAD2L2), which increases the catalytic function of the polymerase, and is involved in translesion synthesis. Pol ζ lacks 3' to 5' exonuclease activity, is unique in that it can extend primers with terminal mismatches. Rev1 has three regions of interest in the BRCT domain, ubiquitin-binding domain, and C-terminal domain and has dCMP transferase ability, which adds deoxycytidine opposite lesions that would stall replicative polymerases Pol δ and Pol ε. These stalled polymerases activate ubiquitin complexes that in turn disassociate replication polymerases and recruit Pol ζ and Rev1. Together Pol ζ and Rev1 add deoxycytidine and Pol ζ extends past the lesion. Through a yet undetermined process, Pol ζ disassociates and replication polymerases reassociate and continue replication. Pol ζ and Rev1 are not required for replication, but loss of REV3 gene in budding yeast can cause increased sensitivity to DNA-damaging agents due to collapse of replication forks where replication polymerases have stalled.[53]
Telomerase
Telomerase is a ribonucleoprotein which functions to replicate ends of linear chromosomes since normal DNA polymerase cannot replicate the ends, or telomeres. The single-strand 3' overhang of the double-strand chromosome with the sequence 5'-TTAGGG-3' recruits telomerase. Telomerase acts like other DNA polymerases by extending the 3' end, but, unlike other DNA polymerases, telomerase does not require a template. The TERT subunit, an example of a reverse transcriptase, uses the RNA subunit to form the primer–template junction that allows telomerase to extend the 3' end of chromosome ends. The gradual decrease in size of telomeres as the result of many replications over a lifetime are thought to be associated with the effects of aging.[14]: 248–249
Polymerases γ, θ and ν (gamma, theta and nu)
Pol γ (gamma), Pol θ (theta), and Pol ν (nu) are Family A polymerases. Pol γ, encoded by the POLG gene, was long thought to be the only mitochondrial polymerase. However, recent research shows that at least Pol β (beta), a Family X polymerase, is also present in mitochondria.[54][55] Any mutation that leads to limited or non-functioning Pol γ has a significant effect on mtDNA and is the most common cause of autosomal inherited mitochondrial disorders.[56] Pol γ contains a C-terminus polymerase domain and an N-terminus 3'–5' exonuclease domain that are connected via the linker region, which binds the accessory subunit. The accessory subunit binds DNA and is required for processivity of Pol γ. Point mutation A467T in the linker region is responsible for more than one-third of all Pol γ-associated mitochondrial disorders.[57] While many homologs of Pol θ, encoded by the POLQ gene, are found in eukaryotes, its function is not clearly understood. The sequence of amino acids in the C-terminus is what classifies Pol θ as Family A polymerase, although the error rate for Pol θ is more closely related to Family Y polymerases. Pol θ extends mismatched primer termini and can bypass abasic sites by adding a nucleotide. It also has Deoxyribophosphodiesterase (dRPase) activity in the polymerase domain and can show ATPase activity in close proximity to ssDNA.[58] Pol ν (nu) is considered to be the least effective of the polymerase enzymes.[59] However, DNA polymerase nu plays an active role in homology repair during cellular responses to crosslinks, fulfilling its role in a complex with helicase.[59]
Plants use two Family A polymerases to copy both the mitochondrial and plastid genomes. They are more similar to bacterial Pol I than they are to mammalian Pol γ.[60]
Reverse transcriptase
Retroviruses encode an unusual DNA polymerase called reverse transcriptase, which is an RNA-dependent DNA polymerase (RdDp) that synthesizes DNA from a template of RNA. The reverse transcriptase family contain both DNA polymerase functionality and RNase H functionality, which degrades RNA base-paired to DNA. An example of a retrovirus is HIV.[14] Reverse transcriptase is commonly employed in amplification of RNA for research purposes. Using an RNA template, PCR can utilize reverse transcriptase, creating a DNA template. This new DNA template can then be used for typical PCR amplification. The products of such an experiment are thus amplified PCR products from RNA.[9]
Each HIV retrovirus particle contains two RNA genomes, but, after an infection, each virus generates only one provirus.[61] After infection, reverse transcription is accompanied by template switching between the two genome copies (copy choice recombination).[61] From 5 to 14 recombination events per genome occur at each replication cycle.[62] Template switching (recombination) appears to be necessary for maintaining genome integrity and as a repair mechanism for salvaging damaged genomes.[63][61]
Bacteriophage T4 DNA polymerase
Bacteriophage (phage) T4 encodes a DNA polymerase that catalyzes DNA synthesis in a 5' to 3' direction.[64] The phage polymerase also has an exonuclease activity that acts in a 3' to 5' direction,[65] and this activity is employed in the proofreading and editing of newly inserted bases.[66] A phage mutant with a temperature sensitive DNA polymerase, when grown at permissive temperatures, was observed to undergo recombination at frequencies that are about two-fold higher than that of wild-type phage.[67]
It was proposed that a mutational alteration in the phage DNA polymerase can stimulate template strand switching (copy choice recombination) during replication.[67]
See also
- Biological machines
- DNA sequencing
- Enzyme catalysis
- Genetic recombination
- Molecular cloning
- Polymerase chain reaction
- Protein domain dynamics
- Reverse transcription
- RNA polymerase
- Taq DNA polymerase
References
- ↑ "Calf thymus polymerase". The Journal of Biological Chemistry 235 (8): 2399–2403. August 1960. doi:10.1016/S0021-9258(18)64634-4. PMID 13802334.
- ↑ "Biochemical studies of bacterial sporulation. II. Deoxy- ribonucleic acid polymerase in spores of Bacillus subtilis". The Journal of Biological Chemistry 241 (7): 1478–1482. April 1966. doi:10.1016/S0021-9258(18)96736-0. PMID 4957767.
- ↑ "Enzymatic synthesis of deoxyribonucleic acid. I. Preparation of substrates and partial purification of an enzyme from Escherichia coli". The Journal of Biological Chemistry 233 (1): 163–170. July 1958. doi:10.1016/S0021-9258(19)68048-8. PMID 13563462.
- ↑ "Enzymatic synthesis of deoxyribonucleic acid. XIV. Further purification and properties of deoxyribonucleic acid polymerase of Escherichia coli". The Journal of Biological Chemistry 239: 222–232. January 1964. doi:10.1016/S0021-9258(18)51772-5. PMID 14114848.
- ↑ "Enzymatic synthesis of deoxyribonucleic acid. VII. Synthesis of a polymer of deoxyadenylate and deoxythymidylate". The Journal of Biological Chemistry 235 (11): 3242–3249. November 1960. doi:10.1016/S0021-9258(20)81345-3. PMID 13747134.
- ↑ "Purification and properties of deoxyribonucleic acid polymerase from Micrococcus lysodeikticus". The Journal of Biological Chemistry 241 (9): 2035–2041. May 1966. doi:10.1016/S0021-9258(18)96662-7. PMID 5946628.
- ↑ "The Nobel Prize in Physiology or Medicine 1959". Nobel Foundation. https://www.nobelprize.org/nobel_prizes/medicine/laureates/1959/.
- ↑ "DNA polymerase II of Escherichia coli in the bypass of abasic sites in vivo". Genetics 136 (2): 439–448. February 1994. doi:10.1093/genetics/136.2.439. PMID 7908652.
- ↑ 9.0 9.1 Lehninger principles of biochemistry (6th ed.). New York: W.H. Freeman and Company. 2013. ISBN 978-1-4292-3414-6. OCLC 824794893.
- ↑ Biochemistry. Mary Finch. 2013.
- ↑ "Structure of an adenine-cytosine base pair in DNA and its implications for mismatch repair". Nature 320 (6062): 552–555. 1986. doi:10.1038/320552a0. PMID 3960137. Bibcode: 1986Natur.320..552H.
- ↑ "Structural basis of high-fidelity DNA synthesis by yeast DNA polymerase delta". Nature Structural & Molecular Biology 16 (9): 979–986. September 2009. doi:10.1038/nsmb.1663. PMID 19718023.
- ↑ "DNA polymerases: structural diversity and common mechanisms". The Journal of Biological Chemistry 274 (25): 17395–17398. June 1999. doi:10.1074/jbc.274.25.17395. PMID 10364165.
- ↑ 14.0 14.1 14.2 14.3 14.4 Molecular biology of the gene (6th ed.). San Francisco: Pearson/Benjamin Cummings. 2008. ISBN 978-0-8053-9592-1.
- ↑ "DNA elongation rates and growing point distributions of wild-type phage T4 and a DNA-delay amber mutant". Journal of Molecular Biology 106 (4): 963–981. October 1976. doi:10.1016/0022-2836(76)90346-6. PMID 789903.
- ↑ 16.0 16.1 "DNA replication: In vitro single-molecule manipulation data analysis and models". Computational and Structural Biotechnology Journal 19: 3765–3778. 2021. doi:10.1016/j.csbj.2021.06.032. PMID 34285777.
- ↑ "Evolution of DNA polymerase families: evidences for multiple gene exchange between cellular and viral proteins". Journal of Molecular Evolution 54 (6): 763–773. June 2002. doi:10.1007/s00239-001-0078-x. PMID 12029358. Bibcode: 2002JMolE..54..763F. http://129.175.105.74/labhome/jfilee/article_jf_1.pdf. Retrieved 2019-09-23.
- ↑ 18.0 18.1 18.2 "Structure of the DP1-DP2 PolD complex bound with DNA and its implications for the evolutionary history of DNA and RNA polymerases". PLOS Biology 17 (1): e3000122. January 2019. doi:10.1371/journal.pbio.3000122. PMID 30657780.
- ↑ "The Proliferating Cell Nuclear Antigen (PCNA)-interacting Protein (PIP) Motif of DNA Polymerase η Mediates Its Interaction with the C-terminal Domain of Rev1". The Journal of Biological Chemistry 291 (16): 8735–8744. April 2016. doi:10.1074/jbc.M115.697938. PMID 26903512.
- ↑ "An overview of Y-Family DNA polymerases and a case study of human DNA polymerase η" (in EN). Biochemistry 53 (17): 2793–2803. May 2014. doi:10.1021/bi500019s. PMID 24716551.
- ↑ DNA Polymerases: Discovery, Characterization Functions in Cellular DNA Transactions. World Scientific Publishing Company. 2010. ISBN 978-981-4299-16-9.
- ↑ "Auto-acetylation of transcription factors as a control mechanism in gene expression". Cell Cycle 3 (2): 114–115. February 2004. doi:10.4161/cc.3.2.651. PMID 14712067.
- ↑ "Deoxyribonucleic acid polymerase from the extreme thermophile Thermus aquaticus". Journal of Bacteriology 127 (3): 1550–1557. September 1976. doi:10.1128/JB.127.3.1550-1557.1976. PMID 8432.
- ↑ 24.0 24.1 "DNA polymerase II as a fidelity factor in chromosomal DNA synthesis in Escherichia coli". Molecular Microbiology 58 (1): 61–70. October 2005. doi:10.1111/j.1365-2958.2005.04805.x. PMID 16164549.
- ↑ InterPro protein view: P61875
- ↑ 26.0 26.1 26.2 "Evolution of replicative DNA polymerases in archaea and their contributions to the eukaryotic replication machinery". Frontiers in Microbiology 5: 354. 2014. doi:10.3389/fmicb.2014.00354. PMID 25101062.
- ↑ "The linear plasmid pMC3-2 from Morchella conica is structurally related to adenoviruses". Current Genetics 20 (6): 527–533. December 1991. doi:10.1007/BF00334782. PMID 1782679.
- ↑ "DnaX complex of Escherichia coli DNA polymerase III holoenzyme. The chi psi complex functions by increasing the affinity of tau and gamma for delta.delta' to a physiologically relevant range". The Journal of Biological Chemistry 270 (49): 29570–29577. December 1995. doi:10.1074/jbc.270.49.29570. PMID 7494000.
- ↑ "Single-Molecule DNA Polymerase Dynamics at a Bacterial Replisome in Live Cells". Biophysical Journal 111 (12): 2562–2569. December 2016. doi:10.1016/j.bpj.2016.11.006. PMID 28002733. Bibcode: 2016BpJ...111.2562L.
- ↑ 30.0 30.1 30.2 "Bacterial replisomes". Current Opinion in Structural Biology 53: 159–168. December 2018. doi:10.1016/j.sbi.2018.09.006. PMID 30292863.
- ↑ "Error-prone repair DNA polymerases in prokaryotes and eukaryotes". Annual Review of Biochemistry 71: 17–50. 2002. doi:10.1146/annurev.biochem.71.083101.124707. PMID 12045089.
- ↑ "Escherichia coli DinB inhibits replication fork progression without significantly inducing the SOS response". Genes & Genetic Systems 87 (2): 75–87. 2012. doi:10.1266/ggs.87.75. PMID 22820381.
- ↑ "Proficient and accurate bypass of persistent DNA lesions by DinB DNA polymerases". Cell Cycle 6 (7): 817–822. April 2007. doi:10.4161/cc.6.7.4065. PMID 17377496.
- ↑ "A new model for SOS-induced mutagenesis: how RecA protein activates DNA polymerase V". Critical Reviews in Biochemistry and Molecular Biology 45 (3): 171–184. June 2010. doi:10.3109/10409238.2010.480968. PMID 20441441.
- ↑ "Managing DNA polymerases: coordinating DNA replication, DNA repair, and DNA recombination". Proceedings of the National Academy of Sciences of the United States of America 98 (15): 8342–8349. July 2001. doi:10.1073/pnas.111036998. PMID 11459973. Bibcode: 2001PNAS...98.8342S.
- ↑ 36.0 36.1 "Genetic requirement for mutagenesis of the G[8,5-MeT cross-link in Escherichia coli: DNA polymerases IV and V compete for error-prone bypass"]. Biochemistry 50 (12): 2330–2338. March 2011. doi:10.1021/bi102064z. PMID 21302943.
- ↑ "Structural basis for the increased processivity of D-family DNA polymerases in complex with PCNA". Nature Communications 11 (1): 1591. March 2020. doi:10.1038/s41467-020-15392-9. PMID 32221299. Bibcode: 2020NatCo..11.1591M.
- ↑ "A novel DNA polymerase family found in Archaea". Journal of Bacteriology 180 (8): 2232–2236. April 1998. doi:10.1128/JB.180.8.2232-2236.1998. PMID 9555910.
- ↑ "Shared active site architecture between archaeal PolD and multi-subunit RNA polymerases revealed by X-ray crystallography". Nature Communications 7: 12227. 2016. doi:10.1038/ncomms12227. PMID 27548043. Bibcode: 2016NatCo...712227S.
- ↑ "Solution structure of the N-terminal domain of the archaeal D-family DNA polymerase small subunit reveals evolutionary relationship to eukaryotic B-family polymerases". FEBS Letters 584 (15): 3370–3375. August 2010. doi:10.1016/j.febslet.2010.06.026. PMID 20598295.
- ↑ "DNA polymerases as useful reagents for biotechnology - the history of developmental research in the field". Frontiers in Microbiology 5: 465. 2014. doi:10.3389/fmicb.2014.00465. PMID 25221550.
- ↑ "The replication machinery of LUCA: common origin of DNA replication and transcription". BMC Biology 18 (1): 61. June 2020. doi:10.1186/s12915-020-00800-9. PMID 32517760.
- ↑ "DNA polymerase family X: function, structure, and cellular roles". Biochimica et Biophysica Acta (BBA) - Proteins and Proteomics 1804 (5): 1136–1150. May 2010. doi:10.1016/j.bbapap.2009.07.008. PMID 19631767.
- ↑ Marks' Basic Medical Biochemistry: a clinical approach (4th ed.). Philadelphia: Wolter Kluwer Health/Lippincott Williams & Wilkins. 2012. p. chapter13. ISBN 978-1608315727.
- ↑ "Primary structure of the catalytic subunit of human DNA polymerase delta and chromosomal location of the gene". Proceedings of the National Academy of Sciences of the United States of America 88 (24): 11197–11201. December 1991. doi:10.1073/pnas.88.24.11197. PMID 1722322. Bibcode: 1991PNAS...8811197C.
- ↑ "Yeast DNA polymerase epsilon participates in leading-strand DNA replication". Science 317 (5834): 127–130. July 2007. doi:10.1126/science.1144067. PMID 17615360. Bibcode: 2007Sci...317..127P.
- ↑ "DNA Polymerases Divide the Labor of Genome Replication". Trends in Cell Biology 26 (9): 640–654. September 2016. doi:10.1016/j.tcb.2016.04.012. PMID 27262731.
- ↑ "A Major Role of DNA Polymerase δ in Replication of Both the Leading and Lagging DNA Strands". Molecular Cell 59 (2): 163–175. July 2015. doi:10.1016/j.molcel.2015.05.038. PMID 26145172.
- ↑ 49.0 49.1 "Structural insights into eukaryotic DNA replication". Frontiers in Microbiology 5: 444. 2014. doi:10.3389/fmicb.2014.00444. PMID 25202305.
- ↑ "Saccharomyces cerevisiae DNA polymerase epsilon and polymerase sigma interact physically and functionally, suggesting a role for polymerase epsilon in sister chromatid cohesion". Molecular and Cellular Biology 23 (8): 2733–2748. April 2003. doi:10.1128/mcb.23.8.2733-2748.2003. PMID 12665575.
- ↑ "Asgard archaea illuminate the origin of eukaryotic cellular complexity" (in En). Nature 541 (7637): 353–358. January 2017. doi:10.1038/nature21031. PMID 28077874. Bibcode: 2017Natur.541..353Z.
- ↑ Separate roles of structured and unstructured regions of Y-family DNA polymerases. Advances in Protein Chemistry and Structural Biology. 78. 2009. pp. 99–146. doi:10.1016/S1876-1623(08)78004-0. ISBN 9780123748270.
- ↑ "DNA polymerase zeta (pol zeta) in higher eukaryotes". Cell Research 18 (1): 174–183. January 2008. doi:10.1038/cr.2007.117. PMID 18157155.
- ↑ "Phylogenetic analysis and evolutionary origins of DNA polymerase X-family members". DNA Repair 22: 77–88. October 2014. doi:10.1016/j.dnarep.2014.07.003. PMID 25112931.
- ↑ "DNA polymerase β: A missing link of the base excision repair machinery in mammalian mitochondria". DNA Repair 60: 77–88. December 2017. doi:10.1016/j.dnarep.2017.10.011. PMID 29100041.
- ↑ "Mitochondrial disorders of DNA polymerase γ dysfunction: from anatomic to molecular pathology diagnosis". Archives of Pathology & Laboratory Medicine 135 (7): 925–934. July 2011. doi:10.5858/2010-0356-RAR.1. PMID 21732785.
- ↑ "Mitochondrial DNA replication and disease: insights from DNA polymerase γ mutations". Cellular and Molecular Life Sciences 68 (2): 219–233. January 2011. doi:10.1007/s00018-010-0530-4. PMID 20927567.
- ↑ "Promiscuous DNA synthesis by human DNA polymerase θ". Nucleic Acids Research 40 (6): 2611–2622. March 2012. doi:10.1093/nar/gkr1102. PMID 22135286.
- ↑ 59.0 59.1 "UniProtKB - Q7Z5Q5 (DPOLN_HUMAN)". Uniprot. https://www.uniprot.org/uniprot/Q7Z5Q5.
- ↑ "Minireview: DNA replication in plant mitochondria". Mitochondrion 19 (Pt B): 231–237. November 2014. doi:10.1016/j.mito.2014.03.008. PMID 24681310.
- ↑ 61.0 61.1 61.2 "Recombination is required for efficient HIV-1 replication and the maintenance of viral genome integrity". Nucleic Acids Research 46 (20): 10535–10545. November 2018. doi:10.1093/nar/gky910. PMID 30307534.
- ↑ "Estimating the in-vivo HIV template switching and recombination rate". AIDS 30 (2): 185–192. January 2016. doi:10.1097/QAD.0000000000000936. PMID 26691546.
- ↑ "Retroviral recombination and reverse transcription". Science 250 (4985): 1227–1233. November 1990. doi:10.1126/science.1700865. PMID 1700865. Bibcode: 1990Sci...250.1227H.
- ↑ "Enzymatic synthesis of deoxyribonucleic acid. XXV. Purification and properties of deoxyribonucleic acid polymerase induced by infection with phage T4". The Journal of Biological Chemistry 243 (3): 627–638. February 1968. doi:10.1016/S0021-9258(18)93650-1. PMID 4866523.
- ↑ "On the exonuclease activity of phage T4 deoxyribonucleic acid polymerase". The Journal of Biological Chemistry 247 (10): 3139–3146. May 1972. doi:10.1016/S0021-9258(19)45224-1. PMID 4554914.
- ↑ "Control of mutation frequency by bacteriophage T4 DNA polymerase. I. The CB120 antimutator DNA polymerase is defective in strand displacement". The Journal of Biological Chemistry 251 (17): 5219–5224. September 1976. doi:10.1016/S0021-9258(17)33149-6. PMID 956182.
- ↑ 67.0 67.1 "The effect on recombination of mutational defects in the DNA-polymerase and deoxycytidylate hydroxymethylase of phage T4D". Genetics 56 (4): 755–769. August 1967. doi:10.1093/genetics/56.4.755. PMID 6061665.
Further reading
- "Eukaryotic DNA polymerases: proposal for a revised nomenclature". The Journal of Biological Chemistry 276 (47): 43487–43490. November 2001. doi:10.1074/jbc.R100056200. PMID 11579108.
External links
- DNA+polymerases at the US National Library of Medicine Medical Subject Headings (MeSH)
- PDB Molecule of the Month DNA polymerase
- Unusual repair mechanism in DNA polymerase lambda, Ohio State University, July 25, 2006.
- A great animation of DNA Polymerase from WEHI at 1:45 minutes in
- 3D macromolecular structures of DNA polymerase from the EM Data Bank(EMDB)
 |  |

