p-value
In null-hypothesis significance testing, the p-value[note 1] is the probability of obtaining test results at least as extreme as the result actually observed, under the assumption that the null hypothesis is correct.[2][3] A very small p-value means that such an extreme observed outcome would be very unlikely under the null hypothesis. Even though reporting p-values of statistical tests is common practice in academic publications of many quantitative fields, misinterpretation and misuse of p-values is widespread and has been a major topic in mathematics and metascience.[4][5]
In 2016, the American Statistical Association (ASA) made a formal statement that "p-values do not measure the probability that the studied hypothesis is true, or the probability that the data were produced by random chance alone" and that "a p-value, or statistical significance, does not measure the size of an effect or the importance of a result", and "does not provide a good measure of evidence regarding a model or hypothesis" without "context or other evidence".[6] That said, a 2019 task force by ASA has issued a statement on statistical significance and replicability, concluding with: "p-values and significance tests, when properly applied and interpreted, increase the rigor of the conclusions drawn from data".[7]
Basic concepts
In statistics, every conjecture concerning the unknown probability distribution of a collection of random variables representing the observed data in some study is called a statistical hypothesis. If we state one hypothesis only and the aim of the statistical test is to see whether this hypothesis is tenable, but not to investigate other specific hypotheses, then such a test is called a null hypothesis test.
As our statistical hypothesis will, by definition, state some property of the distribution, the null hypothesis is the default hypothesis under which that property does not exist. The null hypothesis is typically that some parameter (such as a correlation or a difference between means) in the populations of interest is zero. Our hypothesis might specify the probability distribution of precisely, or it might only specify that it belongs to some class of distributions. Often, we reduce the data to a single numerical statistic, e.g., , whose marginal probability distribution is closely connected to a main question of interest in the study.
The p-value is used in the context of null hypothesis testing in order to quantify the statistical significance of a result, the result being the observed value of the chosen statistic .[note 2] The lower the p-value is, the lower the probability of getting that result if the null hypothesis were true. A result is said to be statistically significant if it allows us to reject the null hypothesis. All other things being equal, smaller p-values are taken as stronger evidence against the null hypothesis.
Loosely speaking, rejection of the null hypothesis implies that there is sufficient evidence against it.
As a particular example, if a null hypothesis states that a certain summary statistic follows the standard normal distribution then the rejection of this null hypothesis could mean that (i) the mean of is not 0, or (ii) the variance of is not 1, or (iii) is not normally distributed. Different tests of the same null hypothesis would be more or less sensitive to different alternatives. However, even if we do manage to reject the null hypothesis for all 3 alternatives, and even if we know that the distribution is normal and variance is 1, the null hypothesis test does not tell us which non-zero values of the mean are now most plausible. The more independent observations from the same probability distribution one has, the more accurate the test will be, and the higher the precision with which one will be able to determine the mean value and show that it is not equal to zero; but this will also increase the importance of evaluating the real-world or scientific relevance of this deviation.
Definition and interpretation
Definition
The p-value is the probability under the null hypothesis of obtaining a real-valued test statistic at least as extreme as the one obtained. Consider an observed test-statistic from unknown distribution . Then the p-value is what the prior probability would be of observing a test-statistic value at least as "extreme" as if null hypothesis were true. That is:
- for a one-sided right-tail test-statistic distribution.
- for a one-sided left-tail test-statistic distribution.
- for a two-sided test-statistic distribution. If the distribution of is symmetric about zero, then
Interpretations
The error that a practising statistician would consider the more important to avoid (which is a subjective judgment) is called the error of the first kind. The first demand of the mathematical theory is to deduce such test criteria as would ensure that the probability of committing an error of the first kind would equal (or approximately equal, or not exceed) a preassigned number α, such as α = 0.05 or 0.01, etc. This number is called the level of significance.
— Jerzy Neyman, "The Emergence of Mathematical Statistics"[8]
In a significance test, the null hypothesis is rejected if the p-value is less than a predefined threshold value , which is referred to as the alpha level or significance level. is not derived from the data, but rather is set by the researcher before examining the data. is commonly set to 0.05, though lower alpha levels are sometimes used. The 0.05 value (equivalent to 1/20 chances) was originally proposed by Ronald Fisher in 1925 in his famous book entitled "Statistical Methods for Research Workers".[9]
Different p-values based on independent sets of data can be combined, for instance using Fisher's combined probability test.
Distribution
The p-value is a function of the chosen test statistic and is therefore a random variable. If the null hypothesis fixes the probability distribution of precisely (e.g. where is the only parameter), and if that distribution is continuous, then when the null-hypothesis is true, the p-value is uniformly distributed between 0 and 1. Regardless of the truth of the , the p-value is not fixed; if the same test is repeated independently with fresh data, one will typically obtain a different p-value in each iteration.
Usually only a single p-value relating to a hypothesis is observed, so the p-value is interpreted by a significance test, and no effort is made to estimate the distribution it was drawn from. When a collection of p-values are available (e.g. when considering a group of studies on the same subject), the distribution of significant p-values is sometimes called a p-curve.[10] A p-curve can be used to assess the reliability of scientific literature, such as by detecting publication bias or p-hacking. [10][11]
Distribution for composite hypothesis
In parametric hypothesis testing problems, a simple or point hypothesis refers to a hypothesis where the parameter's value is assumed to be a single number. In contrast, in a composite hypothesis the parameter's value is given by a set of numbers. When the null-hypothesis is composite (or the distribution of the statistic is discrete), then when the null-hypothesis is true the probability of obtaining a p-value less than or equal to any number between 0 and 1 is still less than or equal to that number. In other words, it remains the case that very small values are relatively unlikely if the null-hypothesis is true, and that a significance test at level is obtained by rejecting the null-hypothesis if the p-value is less than or equal to .[12][13]
For example, when testing the null hypothesis that a distribution is normal with a mean less than or equal to zero against the alternative that the mean is greater than zero (, variance known), the null hypothesis does not specify the exact probability distribution of the appropriate test statistic. In this example, that would be the Z-statistic belonging to the one-sided one-sample Z-test. For each possible value of the theoretical mean, the Z-test statistic has a different probability distribution. In these circumstances, the p-value is defined by taking the least favorable null-hypothesis case, which is typically on the border between null and alternative. This definition ensures the complementarity of p-values and alpha-levels: means one only rejects the null hypothesis if the p-value is less than or equal to , and the hypothesis test will indeed have a maximum type-1 error rate of .
Usage
The p-value is widely used in statistical hypothesis testing, specifically in null hypothesis significance testing. In this method, before conducting the study, one first chooses a model (the null hypothesis) and the alpha level α (most commonly 0.05). After analyzing the data, if the p-value is less than α, that is taken to mean that the observed data is sufficiently inconsistent with the null hypothesis for the null hypothesis to be rejected. However, that does not prove that the null hypothesis is false. The p-value does not, in itself, establish probabilities of hypotheses. Rather, it is a tool for deciding whether to reject the null hypothesis.[14]
Misuse
According to the ASA, there is widespread agreement that p-values are often misused and misinterpreted.[3] One practice that has been particularly criticized is accepting the alternative hypothesis for any p-value nominally less than 0.05 without other supporting evidence. Although p-values are helpful in assessing how incompatible the data are with a specified statistical model, contextual factors must also be considered, such as "the design of a study, the quality of the measurements, the external evidence for the phenomenon under study, and the validity of assumptions that underlie the data analysis".[3] Another concern is that the p-value is often misunderstood as being the probability that the null hypothesis is true.[3][15] p-values and significance tests also say nothing about the possibility of drawing conclusions from a sample to a population.
Some statisticians have proposed abandoning p-values and focusing more on other inferential statistics,[3] such as confidence intervals,[16][17] likelihood ratios,[18][19] or Bayes factors,[20][21][22] but there is heated debate on the feasibility of these alternatives.[23]Cite error: Closing </ref> missing for <ref> tag
Calculation
Usually, is a test statistic. A test statistic is the output of a scalar function of all the observations. This statistic provides a single number, such as a t-statistic or an F-statistic. As such, the test statistic follows a distribution determined by the function used to define that test statistic and the distribution of the input observational data.
For the important case in which the data are hypothesized to be a random sample from a normal distribution, depending on the nature of the test statistic and the hypotheses of interest about its distribution, different null hypothesis tests have been developed. Some such tests are the z-test for hypotheses concerning the mean of a normal distribution with known variance, the t-test based on Student's t-distribution of a suitable statistic for hypotheses concerning the mean of a normal distribution when the variance is unknown, the F-test based on the F-distribution of yet another statistic for hypotheses concerning the variance. For data of other nature, for instance, categorical (discrete) data, test statistics might be constructed whose null hypothesis distribution is based on normal approximations to appropriate statistics obtained by invoking the central limit theorem for large samples, as in the case of Pearson's chi-squared test.
Thus computing a p-value requires a null hypothesis, a test statistic (together with deciding whether the researcher is performing a one-tailed test or a two-tailed test), and data. Even though computing the test statistic on given data may be easy, computing the sampling distribution under the null hypothesis, and then computing its cumulative distribution function (CDF) is often a difficult problem. Today, this computation is done using statistical software, often via numeric methods (rather than exact formulae), but, in the early and mid 20th century, this was instead done via tables of values, and one interpolated or extrapolated p-values from these discrete values . Rather than using a table of p-values, Fisher instead inverted the CDF, publishing a list of values of the test statistic for given fixed p-values; this corresponds to computing the quantile function (inverse CDF).
Example
Testing the fairness of a coin
As an example of a statistical test, an experiment is performed to determine whether a coin flip is fair (equal chance of landing heads or tails) or unfairly biased (one outcome being more likely than the other).
Suppose that the experimental results show the coin turning up heads 14 times out of 20 total flips. The full data would be a sequence of twenty times the symbol "H" or "T". The statistic on which one might focus could be the total number of heads. The null hypothesis is that the coin is fair, and coin tosses are independent of one another. If a right-tailed test is considered, which would be the case if one is actually interested in the possibility that the coin is biased towards falling heads, then the p-value of this result is the chance of a fair coin landing on heads at least 14 times out of 20 flips. That probability can be computed from binomial coefficients as
This probability is the p-value, considering only extreme results that favor heads. This is called a one-tailed test. However, one might be interested in deviations in either direction, favoring either heads or tails. The two-tailed p-value, which considers deviations favoring either heads or tails, may instead be calculated. As the binomial distribution is symmetrical for a fair coin, the two-sided p-value is simply twice the above calculated single-sided p-value: the two-sided p-value is 0.115.
In the above example:
- Null hypothesis (H0): The coin is fair, with Pr(heads) = 0.5.
- Test statistic: Number of heads.
- Alpha level (designated threshold of significance): 0.05.
- Observation O: 14 heads out of 20 flips.
- Two-tailed p-value of observation O given H0 = 2 × min(Pr(no. of heads ≥ 14 heads), Pr(no. of heads ≤ 14 heads)) = 2 × min(0.058, 0.978) = 2 × 0.058 = 0.115.
The Pr(no. of heads ≤ 14 heads) = 1 − Pr(no. of heads ≥ 14 heads) + Pr(no. of head = 14) = 1 − 0.058 + 0.036 = 0.978; however, the symmetry of this binomial distribution makes it an unnecessary computation to find the smaller of the two probabilities. Here, the calculated p-value exceeds 0.05, meaning that the data falls within the range of what would happen 95% of the time, if the coin were fair. Hence, the null hypothesis is not rejected at the 0.05 level.
However, had one more head been obtained, the resulting p-value (two-tailed) would have been 0.0414 (4.14%), in which case the null hypothesis would be rejected at the 0.05 level.
Optional stopping
The difference between the two meanings of "extreme" appear when we consider a sequential hypothesis testing, or optional stopping, for the fairness of the coin. In general, optional stopping changes how p-value is calculated.[24][25] Suppose we design the experiment as follows:
- Flip the coin twice. If both comes up heads or tails, end the experiment.
- Else, flip the coin 4 more times.
This experiment has 7 types of outcomes: 2 heads, 2 tails, 5 heads 1 tail, ..., 1 head 5 tails. We now calculate the p-value of the "3 heads 3 tails" outcome.
If we use the test statistic #, then under the null hypothesis (i.e. #) the two-sided p-value is exactly equal to 1, and both the one-sided left-tail p-value and the one-sided right-tail p-value are exactly equal to .
If we consider every outcome that has equal or lower probability than "3 heads 3 tails" as "at least as extreme", then the p-value is exactly
However, suppose we have planned to simply flip the coin 6 times no matter what happens, then the second definition of p-value would mean that the p-value of "3 heads 3 tails" is exactly 1.
Thus, the "at least as extreme" definition of p-value is deeply contextual and depends on what the experimenter planned to do even in situations that did not occur.
History

.jpg)


P-value computations date back to the 1700s, where they were computed for the human sex ratio at birth, and used to compute statistical significance compared to the null hypothesis of equal probability of male and female births.[26] John Arbuthnot studied this question in 1710,[27][28][29] and "… perhaps the first published report of a nonparametric test …",[28] specifically the sign test; see details at Sign test § History.
The same question was later addressed by Pierre-Simon Laplace, who instead used a parametric test, modeling the number of male births with a binomial distribution:[30]
In the 1770s Laplace considered the statistics of almost half a million births. The statistics showed an excess of boys compared to girls. He concluded by calculation of a p-value that the excess was a real, but unexplained, effect.
The p-value was first formally introduced by Karl Pearson, in his Pearson's chi-squared test,[31] using the chi-squared distribution and notated as capital P.[31] The p-values for the chi-squared distribution (for various values of χ2 and degrees of freedom), now notated as P, were calculated in (Elderton 1902), collected in (Pearson 1914).
Ronald Fisher formalized and popularized the use of the p-value in statistics,[32][33] with it playing a central role in his approach to the subject.[34] In his highly influential book Statistical Methods for Research Workers (1925), Fisher proposed the level p = 0.05, or a 1 in 20 chance of being exceeded by chance, as a limit for statistical significance, and applied this to a normal distribution (as a two-tailed test), thus yielding the rule of two standard deviations (on a normal distribution) for statistical significance (see 68–95–99.7 rule).[35][note 3][36]
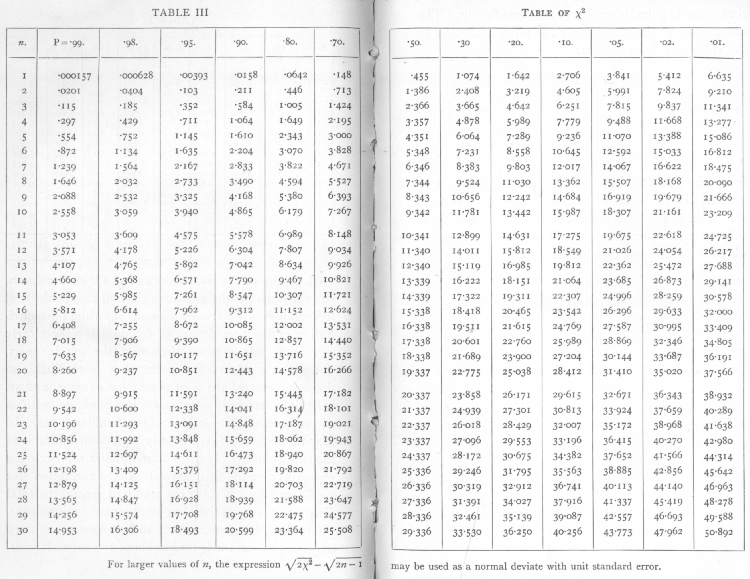
He then computed a table of values, similar to Elderton but, importantly, reversed the roles of χ2 and p. That is, rather than computing p for different values of χ2 (and degrees of freedom n), he computed values of χ2 that yield specified p-values, specifically 0.99, 0.98, 0.95, 0,90, 0.80, 0.70, 0.50, 0.30, 0.20, 0.10, 0.05, 0.02, and 0.01.[37] That allowed computed values of χ2 to be compared against cutoffs and encouraged the use of p-values (especially 0.05, 0.02, and 0.01) as cutoffs, instead of computing and reporting p-values themselves. The same type of tables were then compiled in (Fisher Yates), which cemented the approach.[36]
As an illustration of the application of p-values to the design and interpretation of experiments, in his following book The Design of Experiments (1935), Fisher presented the lady tasting tea experiment,[38] which is the archetypal example of the p-value.
To evaluate a lady's claim that she (Muriel Bristol) could distinguish by taste how tea is prepared (first adding the milk to the cup, then the tea, or first tea, then milk), she was sequentially presented with 8 cups: 4 prepared one way, 4 prepared the other, and asked to determine the preparation of each cup (knowing that there were 4 of each). In that case, the null hypothesis was that she had no special ability, the test was Fisher's exact test, and the p-value was so Fisher was willing to reject the null hypothesis (consider the outcome highly unlikely to be due to chance) if all were classified correctly. (In the actual experiment, Bristol correctly classified all 8 cups.)
Fisher reiterated the p = 0.05 threshold and explained its rationale, stating:[39]
It is usual and convenient for experimenters to take 5 per cent as a standard level of significance, in the sense that they are prepared to ignore all results which fail to reach this standard, and, by this means, to eliminate from further discussion the greater part of the fluctuations which chance causes have introduced into their experimental results.
He also applies this threshold to the design of experiments, noting that had only 6 cups been presented (3 of each), a perfect classification would have only yielded a p-value of which would not have met this level of significance.[39] Fisher also underlined the interpretation of p, as the long-run proportion of values at least as extreme as the data, assuming the null hypothesis is true.
In later editions, Fisher explicitly contrasted the use of the p-value for statistical inference in science with the Neyman–Pearson method, which he terms "Acceptance Procedures".[40] Fisher emphasizes that while fixed levels such as 5%, 2%, and 1% are convenient, the exact p-value can be used, and the strength of evidence can and will be revised with further experimentation. In contrast, decision procedures require a clear-cut decision, yielding an irreversible action, and the procedure is based on costs of error, which, he argues, are inapplicable to scientific research.
Related indices
The E-value can refer to two concepts, both of which are related to the p-value and both of which play a role in multiple testing. First, it corresponds to a generic, more robust alternative to the p-value that can deal with optional continuation of experiments. Second, it is also used to abbreviate "expect value", which is the expected number of times that one expects to obtain a test statistic at least as extreme as the one that was actually observed if one assumes that the null hypothesis is true.[41] This expect-value is the product of the number of tests and the p-value.
The q-value is the analog of the p-value with respect to the positive false discovery rate.[42] It is used in multiple hypothesis testing to maintain statistical power while minimizing the false positive rate.[43]
The Probability of Direction (pd) is the Bayesian numerical equivalent of the p-value.[44] It corresponds to the proportion of the posterior distribution that is of the median's sign, typically varying between 50% and 100%, and representing the certainty with which an effect is positive or negative.
Second-generation p-values extend the concept of p-values by not considering extremely small, practically irrelevant effect sizes as significant.[45]
The S-value, also known as the surprisal value, has been defined as a logarithmic transformation of the p-value: S-value = - log2(p-value). The transformation into S-values is intended to facilitate the interpretation of p-values by using a more intuitive logarithmic scale that indicates how “surprised” one is by a result.[46][47][48]
See also
- Student's t-test
- Bonferroni correction
- Counternull
- Fisher's method of combining p-values
- Generalized p-value
- Harmonic mean p-value
- Holm–Bonferroni method
- Multiple comparisons problem
- p-rep
- p-value fallacy
Notes
- ↑ Italicisation, capitalisation and hyphenation of the term vary. For example, AMA style uses "P value", APA style uses "p value", and the American Statistical Association uses "p-value". In all cases, the "p" stands for probability.[1]
- ↑ The statistical significance of a result does not imply that the result also has real-world relevance. For instance, a medication might have a statistically significant effect that is too small to be interesting.
- ↑ To be more specific, the p = 0.05 corresponds to about 1.96 standard deviations for a normal distribution (two-tailed test), and 2 standard deviations corresponds to about a 1 in 22 chance of being exceeded by chance, or p ≈ 0.045; Fisher notes these approximations.
References
- ↑ "ASA House Style". Amstat News. American Statistical Association. http://magazine.amstat.org/wp-content/uploads/STATTKadmin/style%5B1%5D.pdf.
- ↑ "Not Even Scientists Can Easily Explain P-values". 2015-11-24. https://fivethirtyeight.com/features/not-even-scientists-can-easily-explain-p-values/.
- ↑ 3.0 3.1 3.2 3.3 3.4 "The ASA's Statement on p-Values: Context, Process, and Purpose". The American Statistician 70 (2): 129–133. 7 March 2016. doi:10.1080/00031305.2016.1154108.
- ↑ "Why P Values Are Not a Useful Measure of Evidence in Statistical Significance Testing". Theory & Psychology 18 (1): 69–88. 2008. doi:10.1177/0959354307086923.
- ↑ "A manifesto for reproducible science". Nature Human Behaviour 1 (1). January 2017. doi:10.1038/s41562-016-0021. PMID 33954258.
- ↑ Wasserstein, Ronald L.; Lazar, Nicole A. (2016-04-02). "The ASA Statement on p -Values: Context, Process, and Purpose" (in en). The American Statistician 70 (2): 129–133. doi:10.1080/00031305.2016.1154108. ISSN 0003-1305.
- ↑ Benjamini, Yoav; De Veaux, Richard D.; Efron, Bradley; Evans, Scott; Glickman, Mark; Graubard, Barry I.; He, Xuming; Meng, Xiao-Li et al. (2021-10-02). "ASA President's Task Force Statement on Statistical Significance and Replicability". Chance (Informa UK Limited) 34 (4): 10–11. doi:10.1080/09332480.2021.2003631. ISSN 0933-2480.
- ↑ Neyman, Jerzy (1976). "The Emergence of Mathematical Statistics: A Historical Sketch with Particular Reference to the United States". in Owen, D.B.. On the History of Statistics and Probability. Textbooks and Monographs. New York: Marcel Dekker Inc. p. 161. https://openlibrary.org/works/OL18334563W/On_the_history_of_statistics_and_probability?edition=key%3A/books/OL5206547M.
- ↑ Fisher, R. A. (1992), Kotz, Samuel; Johnson, Norman L., eds., "Statistical Methods for Research Workers" (in en), Breakthroughs in Statistics: Methodology and Distribution, Springer Series in Statistics (New York, NY: Springer): pp. 66–70, doi:10.1007/978-1-4612-4380-9_6, ISBN 978-1-4612-4380-9
- ↑ 10.0 10.1 "The extent and consequences of p-hacking in science". PLOS Biology 13 (3). March 2015. doi:10.1371/journal.pbio.1002106. PMID 25768323.
- ↑ "p-Curve and Effect Size: Correcting for Publication Bias Using Only Significant Results". Perspectives on Psychological Science 9 (6): 666–681. November 2014. doi:10.1177/1745691614553988. PMID 26186117.
- ↑ "Median of the p value under the alternative hypothesis". The American Statistician 56 (3): 202–6. 2002. doi:10.1198/000313002146.
- ↑ "The behavior of the P-value when the alternative hypothesis is true". Biometrics 53 (1): 11–22. March 1997. doi:10.2307/2533093. PMID 9147587. https://zenodo.org/record/1235121.
- ↑ "Scientific method: statistical errors". Nature 506 (7487): 150–152. February 2014. doi:10.1038/506150a. PMID 24522584. Bibcode: 2014Natur.506..150N.
- ↑ "An investigation of the false discovery rate and the misinterpretation of p-values". Royal Society Open Science 1 (3). November 2014. doi:10.1098/rsos.140216. PMID 26064558. Bibcode: 2014RSOS....140216C.
- ↑ "Alternatives to P value: confidence interval and effect size". Korean Journal of Anesthesiology 69 (6): 555–562. December 2016. doi:10.4097/kjae.2016.69.6.555. PMID 27924194.
- ↑ "Why the P-value culture is bad and confidence intervals a better alternative". Osteoarthritis and Cartilage 20 (8): 805–808. August 2012. doi:10.1016/j.joca.2012.04.001. PMID 22503814.
- ↑ "Sifting the evidence. Likelihood ratios are alternatives to P values". BMJ 322 (7295): 1184–1185. May 2001. doi:10.1136/bmj.322.7295.1184. PMID 11379590.
- ↑ "The Likelihood Paradigm for Statistical Evidence" (in en). The Nature of Scientific Evidence. 2004. pp. 119–152. doi:10.7208/chicago/9780226789583.003.0005. ISBN 978-0-226-78957-6.
- ↑ "Replacing p-values with Bayes-Factors: A Miracle Cure for the Replicability Crisis in Psychological Science". 30 April 2015. https://replicationindex.wordpress.com/2015/04/30/replacing-p-values-with-bayes-factors-a-miracle-cure-for-the-replicability-crisis-in-psychological-science/.
- ↑ "Hypothesis Testing: From p Values to Bayes Factors". Journal of the American Statistical Association 95 (452): 1316–1320. December 2000. doi:10.2307/2669779.
- ↑ "A Test by Any Other Name: P Values, Bayes Factors, and Statistical Inference". Multivariate Behavioral Research 51 (1): 23–29. 16 February 2016. doi:10.1080/00273171.2015.1099032. PMID 26881954.
- ↑ "In defense of P values". Ecology 95 (3): 611–617. March 2014. doi:10.1890/13-0590.1. PMID 24804441. Bibcode: 2014Ecol...95..611M. https://zenodo.org/record/894459.
- ↑ Goodman, Steven (2008-07-01). "A Dirty Dozen: Twelve P-Value Misconceptions". Seminars in Hematology. Interpretation of Quantitative Research 45 (3): 135–140. doi:10.1053/j.seminhematol.2008.04.003. ISSN 0037-1963. PMID 18582619. https://www.sciencedirect.com/science/article/pii/S0037196308000620.
- ↑ Wagenmakers, Eric-Jan (October 2007). "A practical solution to the pervasive problems of p values" (in en). Psychonomic Bulletin & Review 14 (5): 779–804. doi:10.3758/BF03194105. ISSN 1069-9384. PMID 18087943. http://link.springer.com/10.3758/BF03194105.
- ↑ "Physico-Theology and Mathematics (1710–1794)". The Descent of Human Sex Ratio at Birth. Springer Science & Business Media. 2007. pp. 1–25. ISBN 978-1-4020-6036-6. https://archive.org/details/descenthumansexr00bria.
- ↑ "An argument for Divine Providence, taken from the constant regularity observed in the births of both sexes". Philosophical Transactions of the Royal Society of London 27 (325–336): 186–190. 1710. doi:10.1098/rstl.1710.0011. http://www.york.ac.uk/depts/maths/histstat/arbuthnot.pdf.
- ↑ 28.0 28.1 "Chapter 3.4: The Sign Test". Practical Nonparametric Statistics (Third ed.). Wiley. 1999. pp. 157–176. ISBN 978-0-471-16068-7.
- ↑ Applied Nonparametric Statistical Methods (Second ed.). Chapman & Hall. 1989.
- ↑ The History of Statistics: The Measurement of Uncertainty Before 1900. Harvard University Press. 1986. p. 134. ISBN 978-0-67440341-3.
- ↑ 31.0 31.1 "On the criterion that a given system of deviations from the probable in the case of a correlated system of variables is such that it can be reasonably supposed to have arisen from random sampling". Philosophical Magazine. Series 5 50 (302): 157–175. 1900. doi:10.1080/14786440009463897. http://www.economics.soton.ac.uk/staff/aldrich/1900.pdf.
- ↑ Biau, David Jean; Jolles, Brigitte M.; Porcher, Raphaël (2010). "P Value and the Theory of Hypothesis Testing: An Explanation for New Researchers". Clinical Orthopaedics and Related Research 468 (3): 885–892. doi:10.1007/s11999-009-1164-4. ISSN 0009-921X. PMID 19921345.
- ↑ Brereton, Richard G. (2021). "P values and multivariate distributions: Non-orthogonal terms in regression models" (in en). Chemometrics and Intelligent Laboratory Systems 210. doi:10.1016/j.chemolab.2021.104264. https://linkinghub.elsevier.com/retrieve/pii/S0169743921000320.
- ↑ "Confusion Over Measures of Evidence (p′s) Versus Errors (α′s) in Classical Statistical Testing", The American Statistician 57 (3): 171–178 [p. 171], 2003, doi:10.1198/0003130031856
- ↑ Fisher 1925, p. 47, Chapter III. Distributions.
- ↑ 36.0 36.1 Dallal 2012, Note 31: Why P=0.05?.
- ↑ Fisher 1925, pp. 78–79, 98, Chapter IV. Tests of Goodness of Fit, Independence and Homogeneity; with Table of χ2, Table III. Table of χ2.
- ↑ Fisher 1971, II. The Principles of Experimentation, Illustrated by a Psycho-physical Experiment.
- ↑ 39.0 39.1 Fisher 1971, Section 7. The Test of Significance.
- ↑ Fisher 1971, Section 12.1 Scientific Inference and Acceptance Procedures.
- ↑ "Definition of E-value". National Institutes of Health. https://blast.ncbi.nlm.nih.gov/Blast.cgi?CMD=Web&PAGE_TYPE=BlastDocs&DOC_TYPE=FAQ.
- ↑ "The positive false discovery rate: a Bayesian interpretation and the q-value". The Annals of Statistics 31 (6): 2013–2035. 2003. doi:10.1214/aos/1074290335.
- ↑ "Statistical significance for genomewide studies". Proceedings of the National Academy of Sciences of the United States of America 100 (16): 9440–9445. August 2003. doi:10.1073/pnas.1530509100. PMID 12883005. Bibcode: 2003PNAS..100.9440S.
- ↑ "Indices of Effect Existence and Significance in the Bayesian Framework". Frontiers in Psychology 10. 10 December 2019. doi:10.3389/fpsyg.2019.02767. PMID 31920819.
- ↑ An Introduction to Second-Generation p-Values Jeffrey D. Blume, Robert A. Greevy, Valerie F. Welty, Jeffrey R. Smith &William D. Dupont https://www.tandfonline.com/doi/full/10.1080/00031305.2018.1537893
- ↑ Die Testentscheidung – Bio Data Science
- ↑ Rafi, Zad; Greenland, Sander (2020-09-30). "Semantic and cognitive tools to aid statistical science: replace confidence and significance by compatibility and surprise" (in en). BMC Medical Research Methodology 20 (1): 244. doi:10.1186/s12874-020-01105-9. ISSN 1471-2288.
- ↑ Rovetta, Alessandro (2024-01-12). "S-values and Surprisal intervals to Replace P-values and Confidence Intervals: Accepted - January 2024" (in en). REVSTAT-Statistical Journal. ISSN 2183-0371. https://revstat.ine.pt/index.php/REVSTAT/article/view/669.
Further reading
- "A Significant Problem: Standard scientific methods are under fire. Will anything change?". Scientific American 321 (4): 62–67 (63). October 2019. "The use of p values for nearly a century [since 1925] to determine statistical significance of experimental results has contributed to an illusion of certainty and [to] reproducibility crises in many scientific fields. There is growing determination to reform statistical analysis... Some [researchers] suggest changing statistical methods, whereas others would do away with a threshold for defining "significant" results.".
- "Tables for Testing the Goodness of Fit of Theory to Observation". Biometrika 1 (2): 155–163. 1902. doi:10.1093/biomet/1.2.155. https://zenodo.org/record/1431595.
- Pearson, Karl (1914). "On the probability that two independent distributions of frequency are really samples of the same population, with special reference to recent work on the identity of Trypanosome strains". Biometrika 10: 85–154. doi:10.1093/biomet/10.1.85.
- Statistical Methods for Research Workers. Edinburgh, Scotland: Oliver & Boyd. 1925. ISBN 978-0-05-002170-5.
- The Design of Experiments (9th ed.). Macmillan. 1971. ISBN 978-0-02-844690-5.
- Statistical tables for biological, agricultural and medical research. London, England. 1938.
- The history of statistics: the measurement of uncertainty before 1900. Cambridge, Mass: Belknap Press of Harvard University Press. 1986. ISBN 978-0-674-40340-6. https://archive.org/details/historyofstatist00stig.
- "Why We Don't Really Know What Statistical Significance Means: Implications for Educators". Journal of Marketing Education 28 (2): 114–120. 2006. doi:10.1177/0273475306288399. https://hops.wharton.upenn.edu/ideas/pdf/Armstrong/StatisticalSignificance.pdf.
- "Why P Values Are Not a Useful Measure of Evidence in Statistical Significance Testing". Theory & Psychology 18 (1): 69–88. 2008. doi:10.1177/0959354307086923. http://wiki.bio.dtu.dk/~agpe/papers/pval_notuseful.pdf. Retrieved 2015-08-28.
- "Fisher and the 5% level". Chance 21 (4): 12. December 2008. doi:10.1007/s00144-008-0033-3.
- The Little Handbook of Statistical Practice. 2012. http://www.tufts.edu/~gdallal/LHSP.HTM.
- "P value and the theory of hypothesis testing: an explanation for new researchers". Clinical Orthopaedics and Related Research 468 (3): 885–892. March 2010. doi:10.1007/s11999-009-1164-4. PMID 19921345.
- Statistics Done Wrong: The Woefully Complete Guide. No Starch Press. 2015. p. 176. ISBN 978-1-59327-620-1. http://statisticsdonewrong.com.
- "The ASA President's Task Force Statement on Statistical Significance and Replicability". Annals of Applied Statistics 15 (3): 1084–1085. 2021. doi:10.1214/21-AOAS1501.
- Benjamin, Daniel J.; Berger, James O.; Johannesson, Magnus; Nosek, Brian A.; Wagenmakers, E.-J.; Berk, Richard; Bollen, Kenneth A.; Brembs, Björn et al. (1 September 2017). "Redefine statistical significance". Nature Human Behaviour 2 (1): 6–10. doi:10.1038/s41562-017-0189-z. PMID 30980045.
External links
- Free online p-values calculators for various specific tests (chi-square, Fisher's F-test, etc.).
- Understanding p-values, including a Java applet that illustrates how the numerical values of p-values can give quite misleading impressions about the truth or falsity of the hypothesis under test.
- StatQuest: P Values, clearly explained on YouTube
- StatQuest: P-value pitfalls and power calculations on YouTube
- Science Isn't Broken - Article on how p-values can be manipulated and an interactive tool to visualize it.
 |  |

{kind=link}